4.1. Центральный объект, усредненный и Медианный центры
Центрографическая статистика (центрографика) - это набор инструментов геопространственной статистики, используемых для анализа Географического распределения путем измерения центра, дисперсии и направленного тренда пространственного расположения. Центрографика рассчитывается на основе местоположения каждого объекта, что является основным отличием этой статистики от описательной статистики, которая касается только непространственных атрибутов пространственных объектов. Действительно величина дохода, объем выбросов в атмосферу или доля зеленых насаждений не имеют точной пространственной локализации и относятся не к "месту" как таковому, а к выбранной для расчета операционно-территориальной единице (кварталу, микрорайону, округу). Тогда как совершенное преступление, дорожно-транспортное происшествие, торговый центр или станции метро могут быть локализованы с точностью и отображены в принятом масштабе геометрическим примитивом "точка".
В данном разделе мы будем использовать два набора данных по тяжким преступлениям против личности в Нью-Йорке: убийства за 15 лет, и убийства в 2021 году.
Рис. 4.1 Исходные данные для построения центрографической статистики: a) точечный слой убийств в Нью-Йорке за 15 лет и b) слой убийств за 2021 г.
Совокупность точек, отображающих однотипные объекты (шурфы для отбора почвенных проб, карстовые воронки) или явления (ДТП, преступления) представляют собой набор пространственных объектов, для которых могут быть рассчитаны базовые центрографические статистики:
Усредненный центр,
Медианный центр,
Центральный объект,
Стандартное расстояние,
Стандартный отклоняющийся эллипс.
Mean Center|Усредненный центр - это географический центр или "показатель центральной тенденции", который рассчитывается как среднее Xi и Yi значений центроидов набора пространственных объектов. Несмотря на то, что чаще всего центрографические статистики рассчитываются для точечных данных, они могут быть отнесены и к полигонам; в этом случае алгоритм работает с центроидами таких объектов.
В рамках данной модели Усредненный центр позволяет определять нечто вроде центральной зоны преступности, а также - при наличии данных за разные временные периоды оценить тенденцию "перемещения" преступной активности. Усредненный центр может рассчитываться для всех объектов совокупности, например - для всех населенных пунктов административной области, и тогда это будет единственная центральная точка или для отдельных ареалов - административных районов той же области, и тогда результатом будет набор "средних" точек, представляющих отдельные районы.
Дополнительной и часто используемой статистикой является Weighted Mean Center|Взвешенный Усредненный центр. Параметры "взвешивания" подбираются в соответствии с задачами моделирования: для населенных пунктов это может быть численность населения, для точек несанкционированных свалок - объем ТБО, для мест совершений преступлений - относительная тяжесть преступлений или время суток (день или ночь) и т.д.
В ArcMAP10.x инструменты центрографики находятся в группе Пространственная статистика в двух наборах Географическое распределение и Анализ паттернов. Усредненный центр - одна из утилит Географического распределения: ArcToolBox >> Spatial Statistics Tools >> Measuring Geographic Distributions >> Mean Center. Отметим, что исходные данные для инструментов Spatial Statistics должны быть в геодезической проекции.
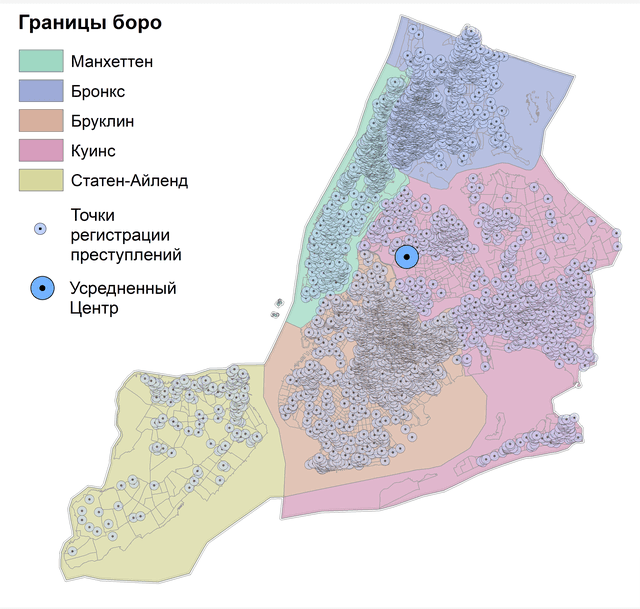
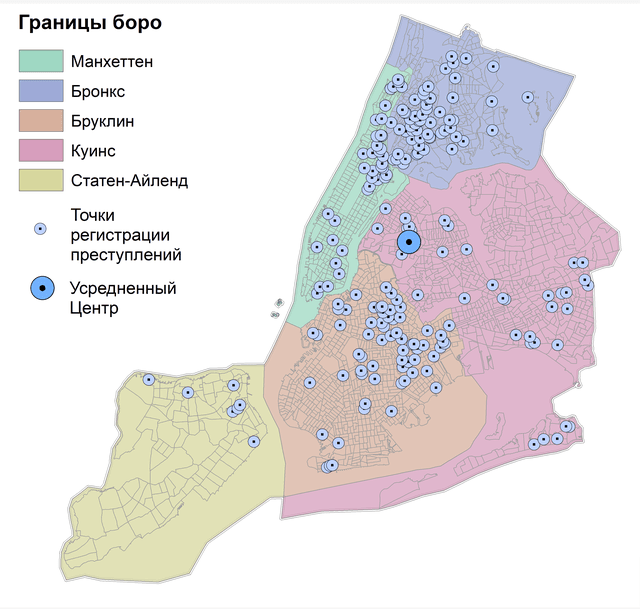
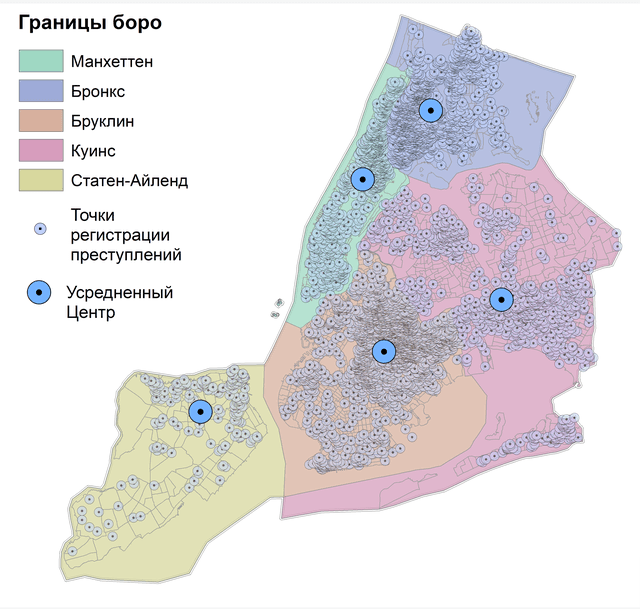
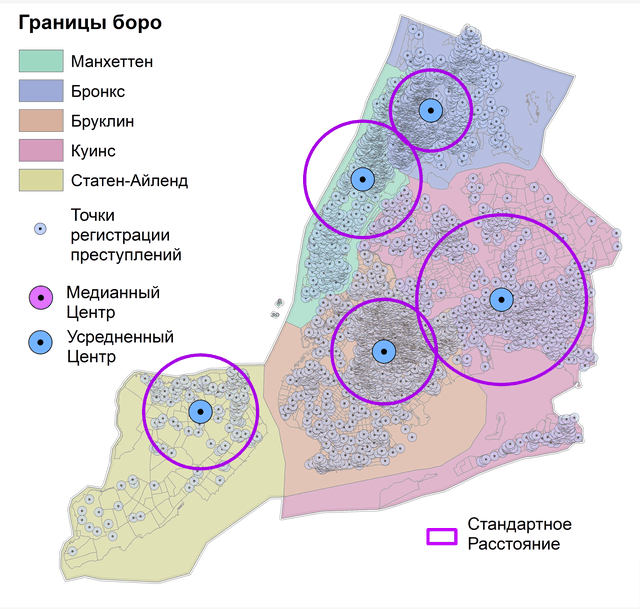
Рис. 4.2 Усредненный центр для точек убийств в Нью-Йорке: a) за 15 лет, b) за 2021 г.
Легко убедиться, что Усредненный центр 2021 г. не сильно отличается от статистики за предыдущие 15 лет - он "сдвинулся" на 1200 м к северо-западу, "переехав" из одного Соседства боро Куинс (Calvary & Mount Zion Cemeteries) в другое (Woodside). Однако для большого массива точек и огромного города Усредненный центр не слишком информативен, полезнее обнаружить локализованные центры, например - для отдельных боро Нью-Йорка. Для этой цели при запуске инструмента Усредненный центр необходимо заполнить позицию Case Field (т.е., указать поле с наименованиями или цифровыми индексами операционно-территориальных единиц).
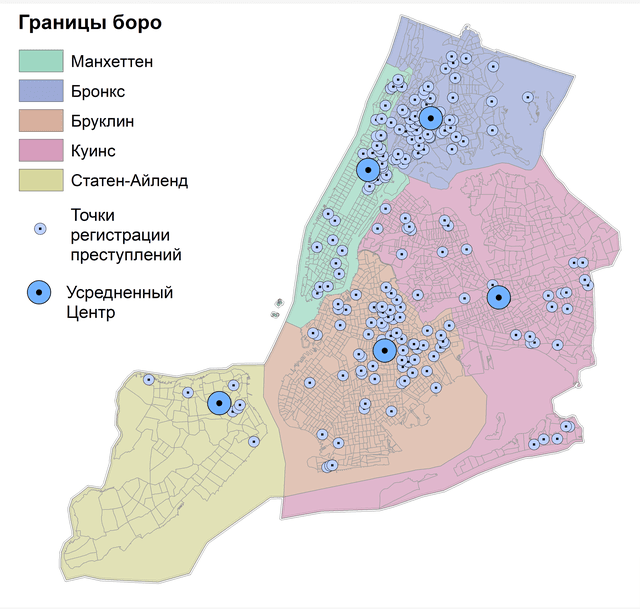
Рис. 4.3 Усредненный центр точек убийств для отдельных боро Нью-Йорка a) за 15 лет, b) за 2021 г.
Моделирование локальных мест преступной активности, позволяет убедиться в их относительной стабильности, поскольку существенных различий между 15-летним периодом и 2021 годом не наблюдается.
Проблема алгоритма Усредненный центр заключается в том, что на результат могут сильно повлиять выбросы значений, которые, например, в данных о преступности имеют высокий показатель Эксцессов7,84. Для таких множеств лучше подходит инструмент Median Center|Медианный центр, вычисляющий точку, минимизирующую стоимостное расстояние до всех прочих точек (аналог центроида для полигона). Медианный центр также может использоваться с учетом веса (население, транспортная нагрузка и т.д.).
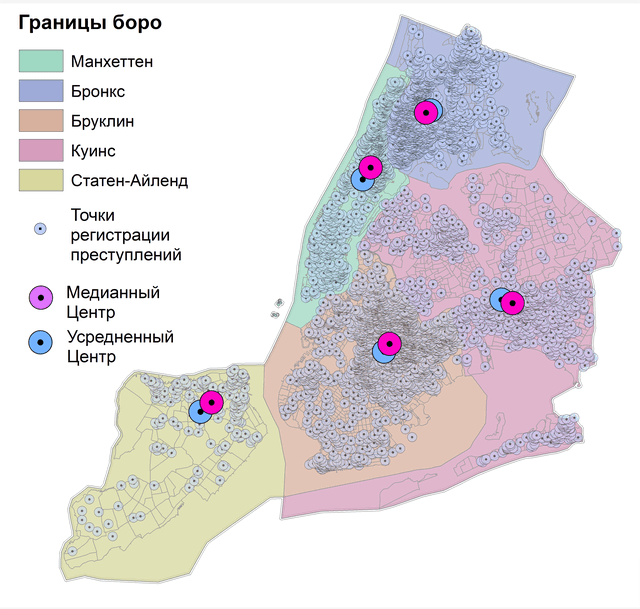
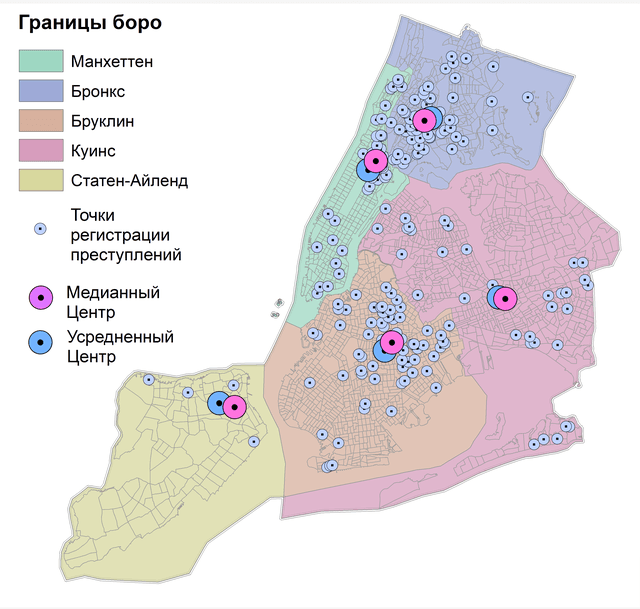
Рис. 4.4 Медианный центр точек убийств для отдельных боро Нью-Йорка: a) за 15 лет, b) за 2021 г.
Как можно убедиться (Рис. 4.4) - все точки Медианных центров смещены на разные расстояния (от 800 м до 1200 м) и в различных направлениях от Усредненных центров боро Нью-Йорка.
Использование статистики Медианный центр обычно связывают с задачами так называемого геомаркетинга - размещения объектов обслуживания населения (например, торговых центров) на основании локализации кварталов с разной численностью населения и удаленностью, а также с задачами оптмизированного патрулирования ареалов с повышенной преступностью [Gorr, Kurland, Dodson, 2018] и т.д. Но на самом деле ничто не мешает пользователю решать с помощью инструментов центрографики и другие задачи, особенно при использовании "взвешенных" по разным признакам статистик.
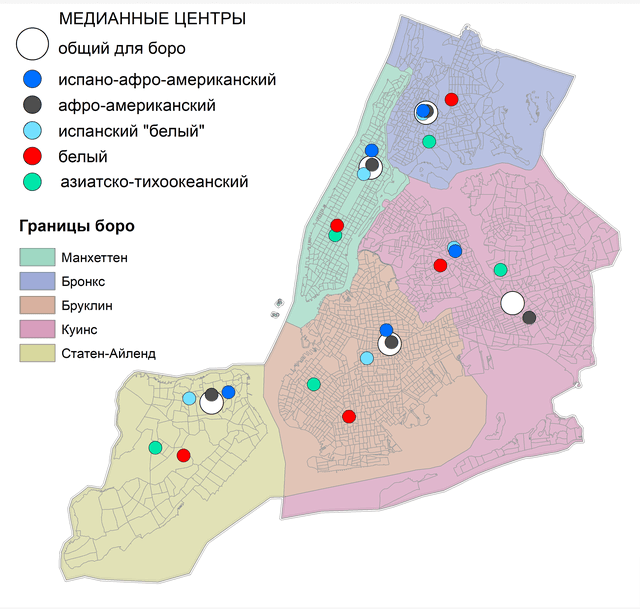
В качестве примера попытаемся верифицировать потенциальные расовые аспекты преступности. У современных урбанистов и гуманитарных географов весьма популярна идея о том, что многонациональные мегаполисы состоят как бы из нескольких этнических или национальных субпространств со своими поведенческими паттернами, общественными (событийными, аттрактивными) центрами и собственной периферией. Если спроецировать эту идею на гипотезу моделирования причинно-следственных связей феномена преступности, то логично предположить, что у "афро-американской" преступности должны быть свои медианные центры в каждом боро, а у "белой" преступности - свои. Данные о преступлениях Нью-Йорка содержат поле SUSP_RACE с указанием на расовую принадлежность обвиняемого. Поскольку все инструменты ArcMAP10.x в ситуации с предварительной выборкой значений обрабатывают только выбранные объекты, для проверки этого предположения необходимо запустить инструмент Median Center последовательно, с разными параметрами выборки (в скобках указано число обвиняемых):
Рис. 4.5 Медианные центры с учетом расовой/национальной принадлежности обвиняемых для отдельных боро Нью-Йорка за 15 лет: белый пунсон - общий центр боро, синий пунсон - испано-афроамериканский, черный - афроамериканский, голубой - испаноязычные светлокожие американцы, красный - белые американцы, зеленый - американцы азиатского и тихоокеанского (островного) происхождения
Полученные результаты, в принципе, подтверждают гипотезу расовых/этнических "подпространств" мегаполиса. С общими центрами преступности в каждом боро совпадают только те центры, где обвиняемые в совершении преступления афроамериканцы, что неудивительно, ибо на их долю падает 40% всех зарегистрированных случаев. Близки к ним во всех боро за исключением Куинса мулаты "черные испанцы" - BLACK HISPANIC. не совпадают с общим центром (за исключением Бронкса) светлокожие испаноязычные американцы. Медианные центры для преступлений, совершенных белыми американцами и американцами азиатского происхождения, отдалены от общих центров на расстояние от 5 км (Манхеттен) до 7 км (Бруклин). Выводы безусловно интересны для специалистов, изучающих расовые и этнические корни преступности, но мы должны понимать что выборки очень неравноценны по объему - число тяжких преступлений, совершенных чернокожими американцами 'BLACK' плюс 'BLACK HISPANIC' в десять раз превышает число преступлений, совершенных белыми американцами, поэтому неизвестно - идет ли речь о действительных различиях в географии поведения и можно ли с уверенностью говорить о формировании ареалов этнической преступности. Но, так или иначе, центрографика может дать "пищу" для размышлений специалистам.
Точно также можно определять Медианные центры для любых других параметров, имеющихся в базовом файле точек зарегистрированных преступлений — это может быть разделение по полу, возрасту, преступлениям, совершенным на улице или в домах. Предварительный выбор точек может быть произведен с помощью дополнительного слоя: сетки конкретных улиц, или окрестностей определенных объектов; например, если нас интересуют аспекты молодежной преступности в слое точек должны быть выбраны преступления совершенные лицами моложе 25 лет, а из этого подмножества можно выбрать точки находящиеся не далее 650 м (принятое в международной практике расстояние десятиминутной прогулки) от учебных заведений.
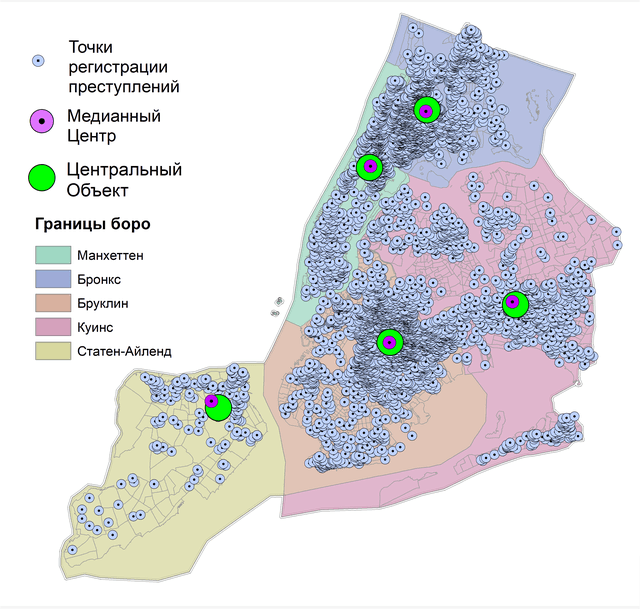
Еще одним интересным и полезным инструментом группы является алгоритм Central Feature|Центральный объект, отличие которого от Усредненного (или Медианного) центра в том, что в результате моделирования мы получаем не новую рассчитанную точку, а один из существующих (наиболее центральных) объектов исходного множества, в данном случае - конкретное место преступления. Алгоритм Центральный объект используется в задачах геомаркетинга, когда необходимо определить наиболее удобный банк, школу, торговый центр из относительно небольшого числа существующих (как правило — это первые десятки объектов).
Предположим, стоит задача сокращения расходов на содержание некой торговой сети и сохранения 70% из общего числа существующих магазинов в разных районах города. Исходя из того, что магазины обслуживают население, проживающее в жилых кварталах, полигоны кварталов можно использовать как входной файл инструмента Центральный объект с параметром численности населения как опцией веса (позиция Weight Field) и границами районов в качестве Case Field. На выходе - получим "центральные кварталы" в которых, по всей вероятности магазины должны быть сохранены.
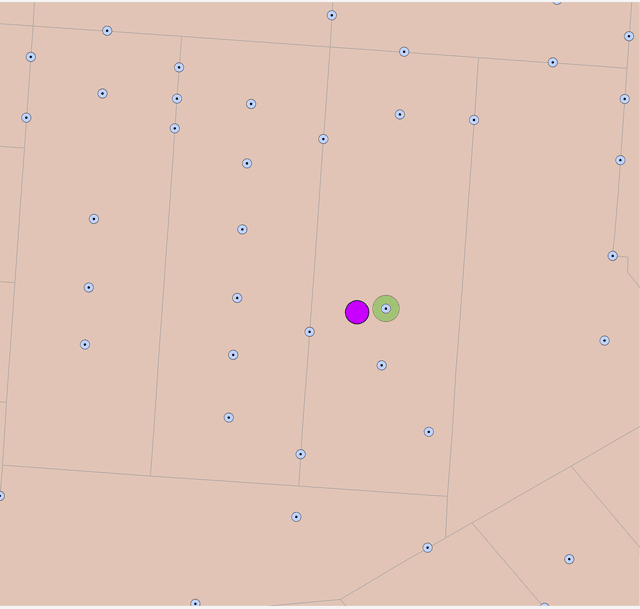
В нашем случае с более чем двумя тысячами преступлений Центральный объект не будет заметно отличаться от Усредненного центра или Медианного центра по той простой причине, что при такой высокой плотности точек, любая статистика перекрывает ту или иную точку, т.е., так или иначе почти совпадет с одним из реальных мест совершенного преступления.
Рис. 4.5 Центральный объект точек убийств для отдельных боро Нью-Йорка: a) общая сцена - Центральные объекты отображены зелеными пунсонами, b) фрагмент слоя - Центральный объект перекрывает существующую точку совершения преступления, Медианный центр рядом представляет собой новую расчетную точку
4.2. Дистанционные статистики
Рассмотренные выше центрографические статистики позволяют определить центральные места множества точек, отображающих те или иные объекты или явления реального мира, но они ничего "не говорят" о компактности и распределении самого множества в географическом пространстве. Эта задача решается с использованием другой группы алгоритмов, принадлежащих в пакете ArcMAP10.x к тому же набору инструментов Измерения географического расстояния|Measuring Geographic Distributions.
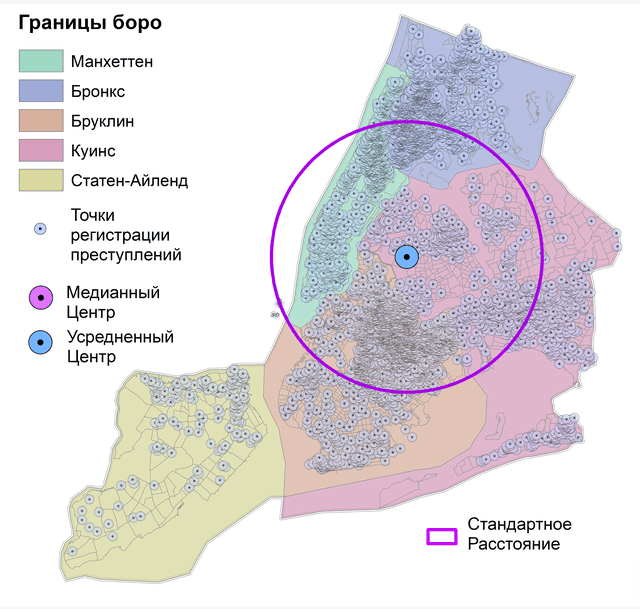
Алгоритм Standard Distance|Стандартное расстояние строит окружность, радиус которой проводится от Усредненного центра данного набора точек. Таким образом, Стандартное расстояние - это мера рассеивания, выражающая компактность и/или разброс набора пространственных объектов.
Таким образом, Стандартное расстояние используется в геомаркетинге для определения ареалов обслуживания объектов торговых сетей или предприятий общественного питания (магазинов или кафе). Аналогично в исследовании преступности Таким образом, Стандартное расстояние может быть использовано для понимания локализации ареалов, построенных для разных этнических групп, видов преступлений или даже просто времени суток ("дневная" и "ночная" преступность) [Grana, Windell, 2017; Wilpen, Kurland, Dodson, 2018].
В ArcMAP10.x утилита запускается ArcToolBox >> Spatial Statistics Tools >> Measuring Geographic Distributions >> Standard Distance с уже знакомыми опциями Case Field для конфигурирования в пределах отдельных районов сцены моделирования и Weight Field для указания числового поля, содержащего значения веса признака.
Рис. 4.6 Стандартное расстояние точек совершения тяжких преступлений: a) для Нью-Йорка в целом, b) для отдельных боро
Очевидно, что Стандартные расстояния, локализованные по районам Нью-Йорка. имеют разные радиусы и охватывают разную долю общего массива точек. В целом по городу в окружности Стандартного расстояния попадает 4270 из 5765 точек (74,1%), при этом зоны влияния соседних центров немного перекрываются. Стандартное расстояние должно охватывать объекты в пределах одного стандартного отклонения - т.е., приблизительно 68% всей совокупности.
Однако, полученный нами результат (Таблица 4.1) достаточно сильно отличается от этой величины. Довольно значительно различается как радиусы окружности Стандартного расстояния, так и число точек, попавших в окружность. Поскольку радиус отражает именно компактность географического рассеяния точек, то его размер не связан напрямую с площадью отдельных боро Нью-Йорка, поэтому сравнительно небольшой радиус Манхеттена охватывает максимальное (95,5%) количество точек. Несовершенство алгоритма Стандартное расстояние заключается в том, что он предполагает анизотропное рассеяние точек по всем направлениям, а реальное рассеяние, как можно видеть, имеет более сложный характер.
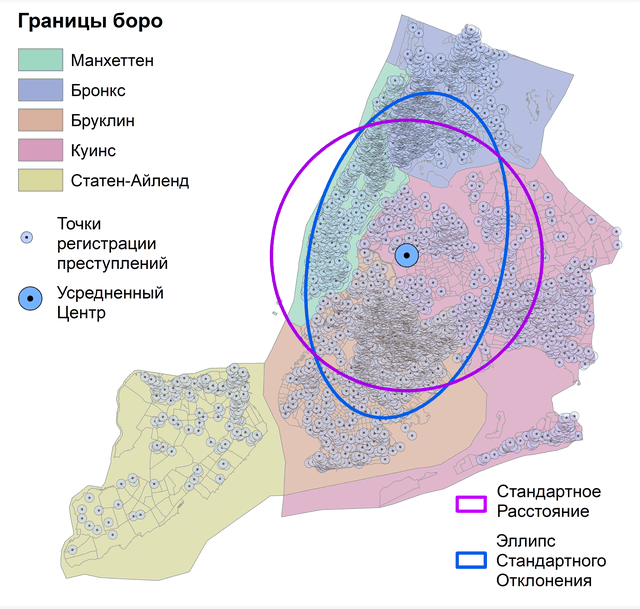
Свойство неравномерного рассеяния частично преодолевается другим, более совершенным инструментом Standard Deviational Ellipse|Эллипс стандартного отклонения (или Эллипс стандартного отклонения), который используется для обобщения компактности и отображения смещения (направленного тренда) Географического распределения. Также как и все другие статистики этой группы Эллипс стандартного отклонения может быть рассчитан с использованием веса атрибута. На выходе инструмента Эллипс стандартного отклонения, мы получаем:
1) эллипс, центрированный по Усредненному центру всех объектов,
2) два стандартных расстояния (длина длинной и короткой осей),
3) ориентацию эллипса.
Вращение оси рассчитывается таким образом, чтобы сумма квадратов расстояний между точками и осями была сведена к минимуму. Эллипс стандартного отклонения представляет пространство распространения явления с лучшим приближением к реальности и поэтому используется более широко, чем Стандартное расстояние.
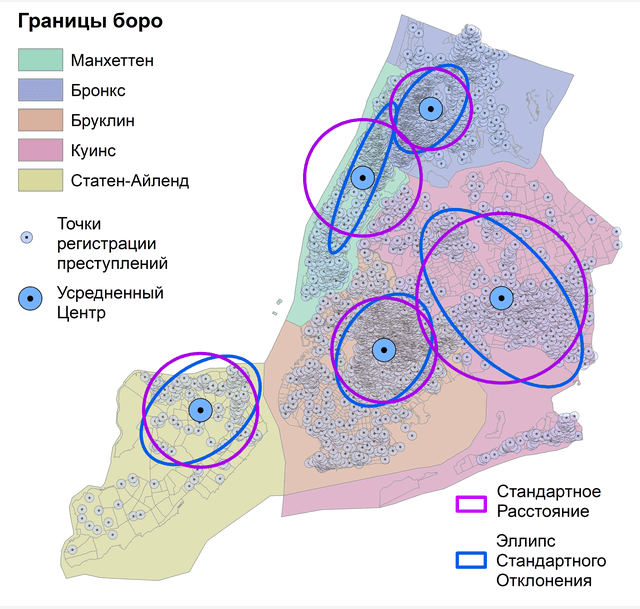
Рис. 4.7 Эллипс стандартного отклонения точек убийств: a) для Нью-Йорка в целом, b) для отдельных боро
В соответствии с эмпирическим правилом, полученным из распределения Рэлея для двумерных данных Эллипс стандартного отклонения первого порядка должен покрывать примерно 63% распределения, Эллипс стандартного отклонения второго порядка – 98%, третьего порядка 99%. Эллипс центрирован по Усредненному центру и повернут на определенный угол (θ) между севером и главной осью. Если знак касательной к эллипсу положительный, то главная ось вращается по часовой стрелке от направления на север. Если касательная отрицательная, то она вращается против часовой стрелки с севера [Lee, Wong, 2001, стр. 49].
Можно констатировать, что Эллипс стандартного отклонения как бы поворачивается вдоль оси максимальной плотности точек. В каждом боро Эллипс охватывает порядка 63% распределения, что в приложении к данному случаю отражает ареалы наибольшей опасности (и, соотвественно - более безопасное пространство за его пределами).
Pattern - одно из центральных понятий геопространственного анализа, которому, к сожалению, не очень просто найти соответствие в русском языке: это и "узор", и "мозаика", и "структура", и "образец", и "рисунок" но, пожалуй, уж точно не "шаблон" (тоже нерусское слово), и не "орнамент". В таких случаях, возможно, действительно проще использовать "обращенный в кириллицу" термин, тем более что понятие "паттернов" вошло уже в разные научные дисциплины. Пространственный паттернточек S - это набор местоположений S = {s1, s2, s3,...sn} в предопределенной области R, где было зарегистрировано N событий[Gatrell et al., 1996].
Для слоя точек паттерн состоит из набора событий в ареале, где каждое событие представляет собой состояние или наблюдение в определенном месте [O'Sullivan, Unwin, 2010, p. 122]. Слой событий — это реализация Пространственного процесса, который можно рассматривать как статичную ситуацию, или как ситуацию, получающую развитие во времени. Поэтому точечные паттерны используется как для описания изменений событий в пространстве, так и для определения взаимосвязей между событиями посредством определения процесса, который обуславливает их расположение.
Наборы точечных событий широко распространены в географическом анализе на самых разных масштабных уровнях: расположение населенных пунктов, размещение магазинов, локализация преступлений, - это всего лишь несколько примеров наборов событий, которые создают точечные паттерны в пространстве. В геоэкологии точечными объектами могут считаться места родниковых источников, точки выхода скальных пород в толще рыхлых отложений, точки слияния рек разного порядка, точки обнаружения редких видов растений и/или животных, точки повышенного содержания токсикантов в депонирующих средах (почве, илах) и т.д.
Соответственно по точечному слою можно реализовать анализ, позволяющий получить ответ на вопросы:
Существуют ли ареалы концентрации населенных пунктов в региональной системе расселения?
Где в пределах городского района расположены горячие точки преступности?
Формируют ли точки наблюдения редких видов единые популяции?;
Связан ли наблюдаемый ареал загрязнения почв тяжелыми металлами с каким-либо из известных источником выбросов?
Являются ли источники водозабора питьевого водоснабжения населения причиной повышенной заболеваемости жителей?
Связаны ли многочисленные археологические памятники с центрами распространения той или иной археологической культуры?
По сути, анализ пространственных паттернов - следующий шаг на пути количественной оценки Географического распределения. Основная идея анализа точечного массива данных заключается в проверке гипотезы о том, что существует пространственный процесс, который генерирует закономерное расположение событий в виде паттерна, и что этот паттерн не является результатом случайности.
В геопространственном анализе различают три основных типа пространственных процессов; в свою очередь, эти процессы формируют три основных типа пространственных паттернов[Oyana, Margai, 2015, стр. 151]:
1. Процесс абсолютной пространственной случайности|Complete spatial randomness process, также называемый - Independent random process|Независимым случайным процессом, представляет собой процесс, при котором пространственные объекты (или значения их атрибутов) разбросаны по географическому пространству в соответствии с двумя правилами [O'Sullivan, Unwin 2010, p. 101]: a) существует равная вероятность возникновения события в любом месте исследуемого ареала (независимость первого порядка), и b) местоположение события не зависит от местоположения других событий (независимость второго порядка). Результатом независимого случайного процесса является Случайный ("рандомный") пространственный паттерн|Random spatial pattern, при котором отображаемые события случайным образом разбросаны по всей исследуемой области. Часто распределение таких точек соответствует распределению Пуассона, описывающему вероятность наступления независимых событий.
2. Конкурентный процесс|Competitive process - это процесс, при котором каждое событие должно располагаться на возможно большем расстоянии от каждого соседнего события, максимизируя таким образом свою зону влияния/воздействия. В этом случае точки, как правило, распределяются более-менее равномерно, по всему исследуемому ареалу таким образом, чтобы находиться на достаточной дистанции от своих соседей подчиняясь Дисперсному рассредоточенному паттерну|Dispersed spatial pattern. Таково, обычно, расположение банковских филиалов, почтовых отделений или кинотеатров, образующих рассредоточенную структуру, поскольку каждый из таких объектов "обслуживает" собственную зону тяготения.
3. Процесс агрегирования|Aggregating process - это процесс, в котором события имеют тенденцию группироваться в результате некоторого агрегирующего, стягивающе-концентрирующего воздействия, формирующего в результате Кластерный пространственный паттерн|Clustered spatial pattern. Например, точки загрязнения депонирующих сред образуют кластеры вокруг производственных зон, а большинство дорогих отелей в городе с развитой сферой туруслуг, как правило, расположены вблизи исторических достопримечательностей.
Очевидно, что именно кластерные паттерны, представляют, как правило, наибольший интерес для геопространственного анализа. Было выяснено, что кластеризация, т.е., формирование закономерной неравномерности размещения объектов может вызываться различными по своей природе пространственными эффектами.
Эффект пространственной неравномерности Первого порядка|First-order Spatial variation Effectвозникает, когда значения или местоположения пространственных объектов меняются от места к месту из-за локального нарушающего равномерность эффекта (O'Sullivan, Unwin 2010, p. 29). Другими словами, соответствующие события не происходят с одинаковой вероятностью везде: например, места проявления событий, связанных с онкологическими заболеваниями, могут варьироваться от места к месту в пределах города, но ожидается, что они будут образовывать аномалии в местах с высокой плотностью населения. Этот тип пространственного влияния на изменение равномерности расположения и/или значения точек вызванный с показателями плотности/интенсивности событий называется эффектом первого порядка.
Эффект Пространственной неравномерности Второго порядка|Second-order Spatial variation effect возникает, когда значение близлежащих местоположений способны влиять друг на друга, (т.е., не выполняется предположение о независимости второго порядка). Продолжая пример с заболеваемостью, можно полагать, что высокие значения инфекционных или вирусных заболеваний будут дополнительно концентрироваться в кварталах с плотным населением в силу контагино́зности. Другой пример - иммигранты, впервые приехавшие в город, которые с большей вероятностью будут проживать в районе, где проживают люди той же этнической принадлежности, поскольку они, вероятно, чувствовали бы себя там более комфортно. В обоих описанных случаях между событиями существует сильное локальное взаимодействие, которое вызывает эффект неравномерности пространства второго порядка (O'Sullivan, Unwin, 2010, p. 112).
Эффекты первого и второго порядка выражают различия в проявлении и интенсивности пространственного процесса на исследуемой территории, что сказывается на значении пространственной автокорреляции. При нулевой (т.е., отсутствующей) пространственной автокорреляции изменение местоположения или значения точки-события является случайным и никаких закономерностей их размещения обнаружить не получится.
Эффекты неравномерности географического пространства первого и второго порядка не всегда легко различимы, но отслеживание их существования чрезвычайно важно для формулировки гипотезы моделирования. Пространственный анализ как раз и позволяет получить обоснованный ответ на основной вопрос - может ли наблюдаемая картина распределения точек и значений их атрибутов быть результатом некоего гипотетического пространственного процесса? При этом сначала мы должны выяснить каков наблюдаемый пространственный паттерн, затем - каким процессом он мог бы быть сформирован.
Алгоритмически подобный анализ выглядит как принятие или опровержение гипотезы о Полной пространственной Случайности, которая относится к конкретным местоположениям, в которых расположены объекты, и пространственному распределению значений их атрибутов. В статистике этому феномену соответствует так называемая Нулевая гипотеза, согласно которой, наблюдаемая картина является результатом стохастического процесса, вероятность обнаружения кластеров в исследуемых данных минимальна, и пространственная автокорреляция отсутствует.
Стохастический процесс можно проиллюстрировать воображаемым экспериментом с разбрасыванием (с некоторой высоты) над абсолютной ровной поверхностью разноцветных (скажем - красных, зеленых и синих) мячей. Сколько бы не повторяли эксперимент, вероятность того, что распределение шаров на плоскости будет кластерным или дисперсным ничтожно мала: они "раскатятся" в случайном порядке. А вот если разбрасывать шары над реальной местностью с выраженным рельефом холмов и котловин, то есть высокая вероятность обнаружения скопления мячей в отрицательных формах рельефа (поскольку "сработает" неравномерность первого порядка). Однако и в этом случае сложно ожидать появления кластеров с только красными или только зелеными мячами, ибо одноцветные мячи никак не "притягивают" друг друга.
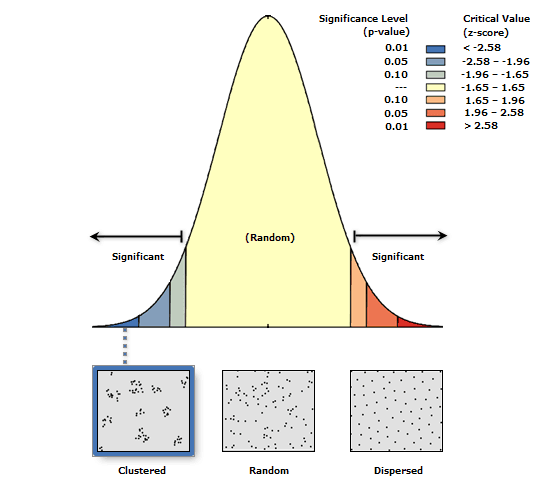
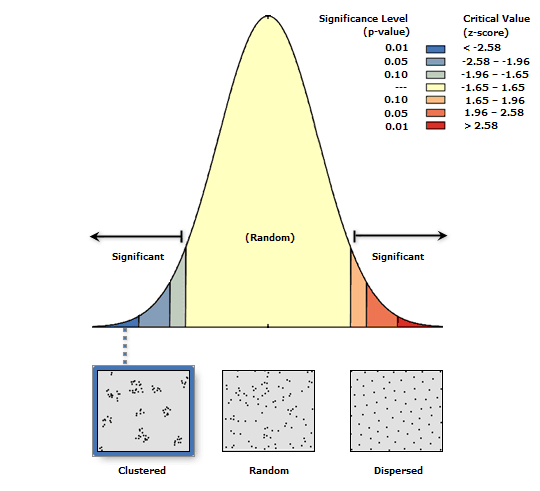
Для принятия (т.е., признания случайности) или опровержения (т.е., признания закономерности) пространственного распределения точек-событий используются Z-оценка и P-значение. Z-оценка - это критический параметр, используемый для вычисления соответствующего P-значения при условии нормального распределения изучаемых данных. Z-оценкаотражает количество стандартных отклонений, при которых значение атрибута отличается от среднего значения. В свою очередь P-значение это вероятность, описывающая уровень достоверности того, что наблюдаемый паттерн был создан случайным образом[Mitchell, 2005]. Если данные демонстрируют пространственную случайность, не обнаруживая закономерности и, следовательно, лежащего в основе закономерности процесса, то нет никакой дальнейшей необходимости в географическом анализе, и наоборот если данные показывают, что они подвержены одному из двух (или сразу обоим) эффектам неравномерности (локализация в пространстве, и зависимость значения рядом расположенных точек) открывается возможность и необходимость геопространственного анализа.
Существует два основных (взаимосвязанных) метода анализа точечных паттернов: методы, основанные на плотности, и методы, основанные на расстоянии. Методы, основанные на плотности, используют интенсивность событий, происходящих в пространстве, поэтому они лучше описывают эффекты первого порядка. К ним относятся алгоритмы оценки Плотности точек|Point Density и плотности ядра|Kernel estimation methods. Методы, основанные на расстоянии, описывают эффекты второго порядка, когда значение одной точки может оказывать влияние на значения точки, расположенной по соседству. Такие методы включают метод Ближайшего соседа|Nearest Neighbor method, Функции Расстояния G и F|the G and F Distance Functions, Функцию расстояния Рипли K|the Ripley’s K-distance function[O'Sullivan, Unwin 2010, p. 85].
4.4. Метод ближайшего соседа и Функция K Рипли
Метод ближайших соседей|Nearest neighbor method также называемый средним ближайшим соседом (average nearest neighbor) - это статистический тест, используемый для оценки пространственного процесса, на основе которого был сгенерирован точечный паттерн. Потенциальные тематические исследования с помощью Метода ближайшего соседа включают отслеживание очагов во время вспышки заболевания или оценки потребителей продуктов или услуг на исследуемой территории.
Сравнивая наблюдаемое пространственное распределение со случайным теоретическим распределением алгоритм Ближайшего соседа определяет какой паттерн - случайный, дисперсный или кластерный - описывает данный набор точек-событий, и, одновременно проверяет нулевую гипотезу о том, что наблюдаемый паттерн является случайным и генерируется полной пространственной случайностью. Тест выводит наблюдаемое среднее расстояние, ожидаемое среднее расстояние (с помощью однородного процесса точки Пуассона), коэффициент ближайшего соседа R, P-значение и Z-балл (оценку).
Ожидаемое среднее расстояние|Expected mean distance - это среднее расстояние, которое, на котором, скорее всего, встречалось бы одинаковое количество событий, если бы они были распределены случайным образом.
Наблюдаемое среднее расстояние|Obsereved mean distance - это фактическое среднее расстояние, разделяющее между собой точки набора данных.
P-значение -это вероятность того, что наблюдаемый точечный шаблон является результатом полной пространственной случайности. P-значения варьируются от 0 до 1, причем чем меньше значение P, тем меньше вероятность того, что наблюдаемый паттерн был сгенерирован полной пространственной случайностью. Доверительные P-значения распределяются следующим образом:
Таблица 4.3 Уровне доверительности P-значения
P-значение
Уровень доверительности
p < 0,10
90%
p < 0,05
95%
p < 0,01
99%
Z-оценка - это стандартные отклонения, которые являются мерой того, на сколько стандартных отклонений находится элемент от среднего значения. Z-оценка 0представляет элемент, равный среднему значению, в то время как оценка +2,5 указывает на то, что элемент находится на расстоянии 2,5 стандартных отклонений. Эти оценки могут быть положительными или отрицательными. Мы также можем связать Z-оценки с уровнями достоверности.
Рис. 4.8 Отчет по результатам Ближайшего среднего для точечного набора убийств 2021 г. Нью-Йорка
Observed Mean Distance: 2270,1855 US_Feet
Expected Mean Distance: 3876,8416 US_Feet
Nearest Neighbor Ratio: 0,585576
z-score: -11,461696
p-value: 0,000000
Интерпретируем результаты: Z-оценка-11,4, что меньше чем -2,58, и указывает положение в крайне левой "синей" части "колокола" графика с нарисованной под этой частью картинкой кластеризованного (clustered) расположения точек. P-значение0,0000, что меньше 0,01 следовательно вероятность того, что этот кластеризованный паттерн может быть результатом полной пространственной случайности, близка к нулю. Коэффициент Ближайшего соседа|Nearest Neighbor Ratio составляет 0,585 (т.е., значительно меньше единицы) и статистически значим на данном уровне, P-значения0,000, что также указывает на процесс кластеризации. Собственно об этом прямо сообщает фраза в html-отчете по результатам теста: "Given the z-score of -11.4616962534, there is a less than 1% likelihood that this clustered pattern could be the result of random chance."
Естественно поинтересоваться, насколько 2021 год был типичным для общей картины распространения самого тяжкого вида преступлений против личности в Нью-Йорке. Для ответа на этот вопрос запустим Average Nearest Neighbor еще раз теперь уже для поля мест убийств за 15 лет Murdr_15y.
Рис. 4.9 Отчет по результатам Ближайшего среднего точек совершения убийств 2005-2020 г.Нью-Йорка
Observed Mean Distance: 332,6281 US_Feet
Expected Mean Distance: 912,5224 US_Feet
Nearest Neighbor Ratio: 0,364515
z-score: -92,307253
p-value: 0,000000
Сравним результаты с предыдущими (для одного года). Коэффициент ближайших соседей|Nearest Neighbor Ratio равен 0,364 (т.е., еще меньше, чем для 2021), Z-оценка-92,3; P-value0,000. Таким образом мы имеем дело с более "жестко" кластеризованной моделью существует вероятность менее 1%, что этот кластеризованный шаблон может быть результатом полной пространственной случайности, о чем свидетельствует аналогичная запись в html-отчете алгоритма. Иными словами, мы можем утверждать с более чем 99% достоверностью, что распределение тяжких преступлений в Нью-Йорке образует кластеризованный паттерн: преступность не распределяется случайным образом, и в некоторых местах мегаполиса вероятность подвергнуться нападению значительно выше чем в других.
Алгоритм Average Nearest Neighbor|Ближайшего среднего не позволяет проследить, где именно находятся кластеры, для их выявления применяются другие инструменты, в частности - Kernel Density Estimation|Оценка плотности ядра. Но перед применение этого метода необходимо выявить типичные расстояния, на которых (в данном точечном наборе данных) выражена кластеризация. Для определения таких расстояний используется функция K-Рипли и преобразованная функция K Рипли.
Multi-Distance Spatial Cluster Analysis (Ripley's K Function)|Функция Рипли - это метод пространственного анализа для совокупности точек, основанный на функции расстояния. Результатом функции является ожидаемое количество событий в радиусе D, рассчитываемом как ряд дополнительных расстояний d, центрированных по каждому из точек-событий по очереди. Алгоритм строит окружности радиусом D для каждой отдельной целевой точки совокупности и затем подсчитывает, сколько точек-событий находится внутри. Эта процедура повторяется для серии диапазонов расстояний D (например, каждые 100 м, начиная со 100 м и до 1000 м) [Oyana, Margai, 2015, p. 163].
Построим график Функции К-Рипли для совокупности точек мест убийств в Нью-Йорке в 2021 г. Для запуска функции необходимо привлечь полигональный файл области исследований - в данном случае это общие границы Нью-Йорка. Алгоритм находится в составе группы Пространственная статистика: ArcToolBox >> Spatial Statistics Tools >>Analyzing Patterns >> MultiDistance Spatial Cluster Analysis. Дополнительные опции, которые необходимо указать:
Number of Distance Bands: 10 (* Число Дистанционных Диапазонов),
Compute Confidence Envelope: 99_PERMUTATIONS (* 99 наборов точек, от которых будут строиться окружности, размещаются случайным образом),
Boundary Correction Methods: SIMULATE_OUTER_BOUNDARY_VALUES (* условие для учета точек за пределами исследуемой области, если таковые имеются, чтобы не недооценивать количество соседей, для точек близких к границам),
Study Area Method: USER_PROVIDED_STUDY_AREA_FEATURE_CLASS (* условие отнесения совокупности точек к изучаемому ареалу),
Study Area Feature Class: Boundaries (* указывается полигональный файл границ исследуемого ареала).
Рис. 4.10 К-Рипли график для слоя точек убийств 2021 г. Нью-Йорка
Результатом алгоритма являются график функции, таблица и сохраняемое во вкладке Results сообщение Messages - Executing: MultiDistanceSpatialClustering, фактически дублирующее таблицу. В нашем случае все результаты "выданы" в футах (исходные данные имеют проекцию NAD_1983_StatePlane_New_York_Long_Island_FIPS_3104_Feet), но их несложно перевести в метры.
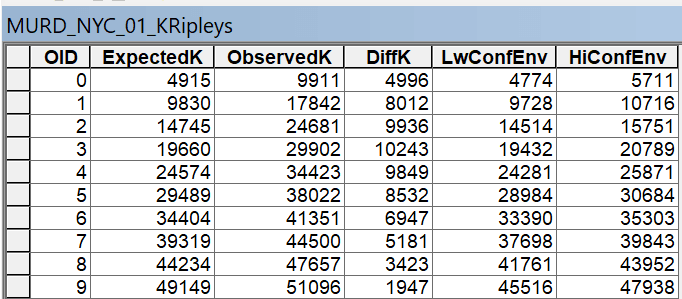
Рис. 4.11 Скриншот таблицы результатов К-Рипли функции для слоя точек убийств Нью-Йорка за 2021 г.
В таблице приведены 10 интервалов дистанций: как можно видеть на графике они размечены через каждые 200 футов (60 м). Поле ExpectedK - ожидаемое среднее расстояние между точками в окружности заданного радиуса, поле ObservedK - фактически наблюдаемое среднее расстояние между точкам, поле DiffK- различия между ожидаемыми и наблюдаемыми значениями средних расстояний между точками для каждого радиуса, LwConfEnv - граница нижнего доверительного интервала, HiConfEnv - граница верхнего доверительного интервала.
Как можно интерпретировать полученные результаты? В-первых, наблюдаемое значение Observed Kво всех диапазонах больше, чем ожидаемое значение для всех десяти значений расстояния в пределах диапазона (400 – 5000 футов, или 120 - 1500 м), что указывает на то, что распределение событий имеет тенденцию быть кластеризованным, а не случайным. Во-вторых, для всех диапазонов расстояний, Observed K больше, чем значение верхней доверительной границы (HiConfEnv в таблице или maxL(d) в Messages), и это доказывает, что пространственная кластеризация статистически значима для каждого расстояния. В-третьих, чем больше разница между наблюдаемым и ожидаемым значением, тем интенсивнее кластеризация на этом расстоянии (разница).
Следовательно, с помощью функции K Рипли, мы можем определить дистанцию наиболее выраженной кластеризации, ориентируясь на поле Diff (Diff в Messages) и ObservedK а также график функции (дистанция наибольшего расхождения красной линии наблюдаемого среднего расстояния между точками от синей линии ожидаемого среднего расстояния между точками). Наибольшее различие между ожидаемым и наблюдаемым средним расстоянием 10243 фута зафиксировано расстояния в 29902 фута или 9114 м.
Таким образом, пространственная кластеризация нападений более очевидна на дистанции 9114 м. С точки зрения построения гипотезы исследования это означает, что, если бы мы хотели продолжить анализ феномена преступности в Нью-Йорке, хороший масштаб анализа (расстояние, на котором вычисляются пространственные веса для пространственной статистики) составлял бы около 1 км. Это расстояние и является базовым для следующей статистики - Kernel Density Function|Функция плотности ядра.
4.5. Функция плотности ядра
Kernel Density Function|Функция плотности ядра ("ядерная функция") вычисляет плотность вероятности события на некотором расстоянии от контрольной точки. Оценка плотности ядра - это непараметрический метод, использующий функции ядра для создания сглаженных значений растровых карт плотности, в которых плотность в каждом местоположении указывает на концентрацию точек в соседней области: высокие концентрации в виде "гор" и "пиков", низкие - в виде "долин" и "депрессий". Термин "kernel/ядро" в пространственной статистике используется главным образом для обозначения окна, центрируемого в окрестностях очередной точки для вычисления соответствующей формулы и последовательно перемещаемого в новое местоположение [Oyana, Margai, 2015, p. 168].
В широком смысле Функция плотности ядра предоставляет метод интерполяции для оценки влияния каждого события на его окрестности в соответствии с выбранным радиусом расчета. Растровые карты плотности "раскрашиваются" алгоритмом на концентрические зоны: темные (с высокими значениями) и светлые (с низкими значениями). Ядро может быть представлено в виде колокола с высоким значением плотности на его своде и низким - по краям. Форма ядра зависит от параметра радиуса поиска bandwidth: использование большего радиуса для набора точек приводит к более "расплывчатому" ядру с плавно понижающимися значениями от центра плотности ядра к периферии, и наоборот для того же набора точек меньший радиус приведет к конфигурированию компактных ядер с резким падением значений от центра к краям. Основное преимущество оценки плотности ядра состоит в том, что результирующая функция плотности непрерывна во всех точках исследуемой области; вместо точечных карт пользователь получает сплошную поверхность, в пределах которой он может оценивать общую вероятность событий (преступности, заболеваемости, загрязнения депонирующих сред и т.д.).
Сложным моментом использования алгоритма Функции плотности ядра является субъективность в определении радиуса поиска. Именно по этой причине в качестве стартового значения обычно используют диапазон наибольшего различия между ожидаемым и наблюдаемым средним расстоянием функции K-Рипли. После "первой пробы" алгоритм можно запускать с другими значениями двигаясь к оптимальному (для конкретной задачи) результату методом "проб и ошибок".
Kernel Density функция ArcMAP10.x также принадлежит к группе инструментов Пространственного Анализа: ArcToolBox >> Spatial Analyst Tools >> Density >> Kernel Density. Регулированию подлежат опции выходного размера ячейки Output cell size (можно оставить значение по умолчанию), поле учета "весового атрибута" Population field и важная опция поискового радиуса Search radius (можно использовать расстояние функции К-Рипли).
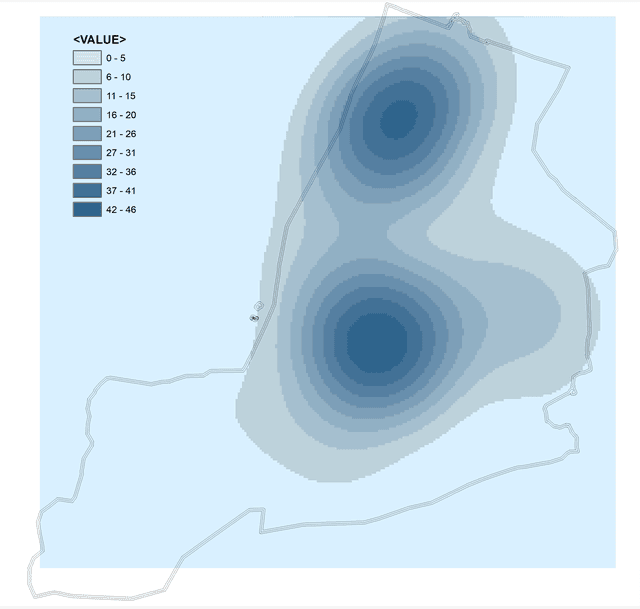
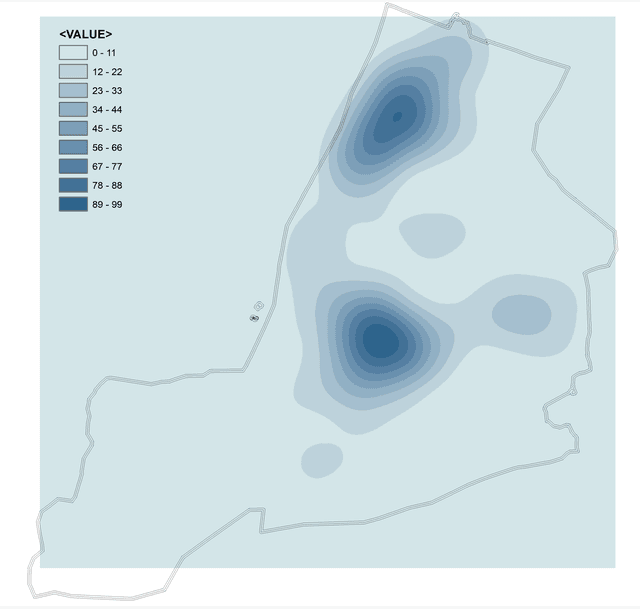
Рис. 4.12 Оценка плотности ядра для слоя точек убийств (2005-2020 гг.) Нью-Йорка с радиусом поиска: a) 1R - 29902 футов, b) 2R - 59000 футов, c) 0,5R - 14500 футов
Очевидно (Рис. 4.12), что значения радиуса поиска, "рекомендованное" функцией К-Рипли действительно является неким объективным средним: места преступлений формируют два очага высокой плотности (один Бронкс плюс Манхеттен, другой в Бруклине), но при этом внутренние различия очагов затушеваны. Вдвое больший радиус поиска рисует нам единое пятно, сориентированное в направлении высоких концентраций точек, но при этом скрывающее любые внутренние различия. Наконец с радиусом равным половине рекомендованного значения (14500 футов) функция более точно конфигурирует очертания двух главных очагов, при этом открывая три очага второго порядка (два в Куинсе и один в Бруклине).
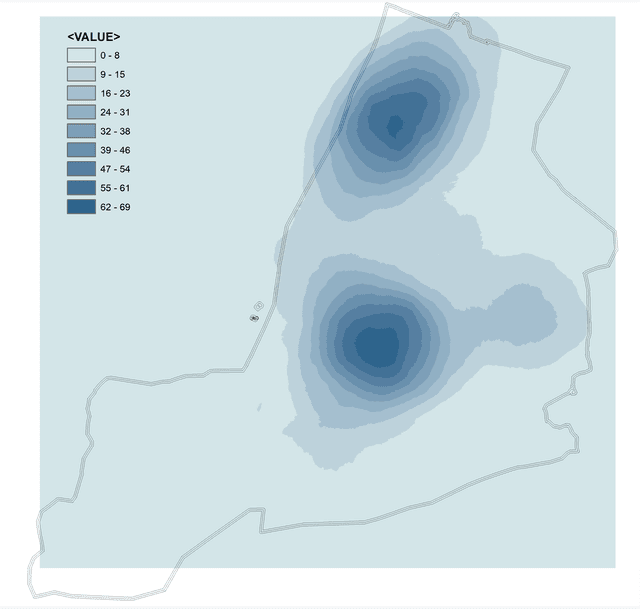
Отметим, что Kernel Density функция "взвешивает" близлежащие события в окрестностях каждой отдельной точки таким образом, что ближе расположенные точки (и значения их атрибутов) учитываются как более тяжелые, чем те, которые находятся дальше, тем самым воспроизводится эффект усиления/ослабления взаимного расположения точек. Это отличает Kernel Density функцию от функции простого расчета плотности точек Point Density, при котором плотность рассчитывается для каждой точки на основе количества соседних объектов, разделенных на окружающую площадь, без дифференциации на основе близости или любой другой схемы взвешивания. Чтобы убедиться в различиях сравним результат двух алгоритмов Kernel Density и Point Density, отработавших с одинаковым радиусом поиска - 14500 футов.
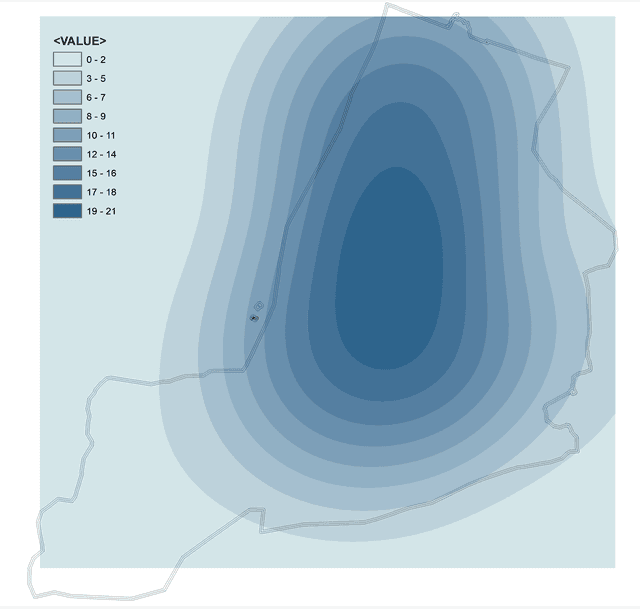
Рис. 4.13 a) Оценка плотности ядра, b) Оценка плотности точек для слоя точек убийств (2005-2020 гг.) Нью-Йорка с радиусом поиска 14500 футов
Как можно убедиться (Рис. 4.13)Функция Плотности ядра|Kernel Density лучше отражает пространственный характер распределения место преступлений чем Функция Плотности точек|Point Density даже при условии того, что мы не задействовали никакие весовые атрибуты
Отметим также, что в данном случае структура преступности лучше всего выражается при значении радиуса меньше рекомендованного, что лишний раз свидетельствует о роли эксперта в любых "полуавтоматизированных" ГИС-построениях. Стоит обратить внимание на то обстоятельство, интенсивность не оценивается для боро Статен-Айленд, ввиду небольшого числа точек и остальной части других боров, потому что там не было зафиксировано соответствующих событий. При необходимости растр плотности ядер может быть конвертирован в полигональный шейп-файл с последующим выбором полигонов "высокой плотности" изучаемого явления.
4.6. Факторы веса на примере сети городов
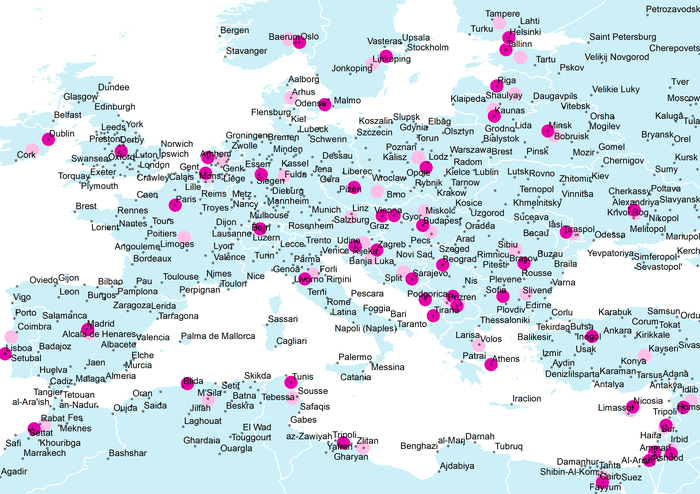
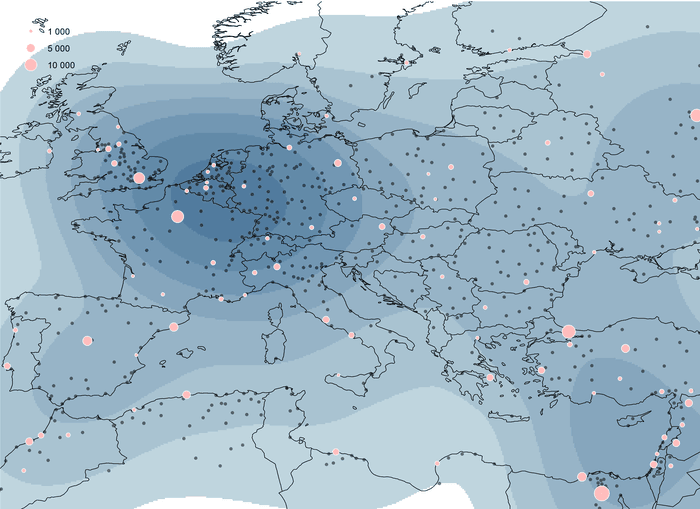
Весовые атрибуты играют существенную роль в расчете центрографических статистик и функций плотности. Классический пример такого рода влияний обычно демонстрируют на переменной численности населения, привязанной к населенным пунктам. Воспользуемся точечным файлом городов Европы (Рис. 4.14).
Рис. 4.14 Исходный файл точек городов Европы
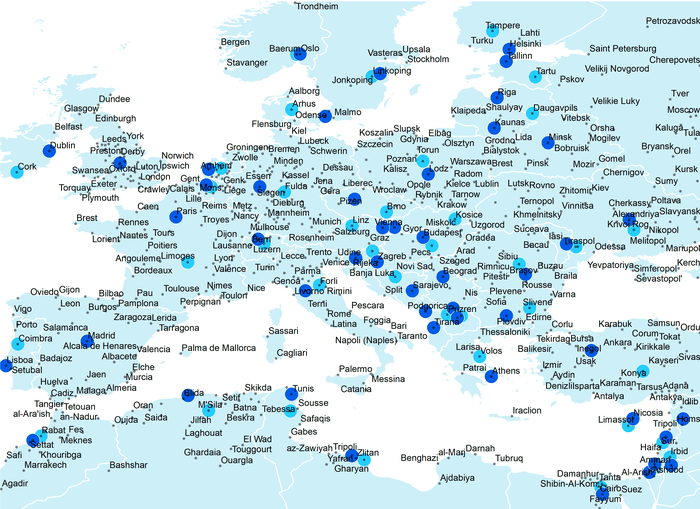
Статистика Central Feature|Центральный объект демонстрирует нам сразу два интересных эффекта: во-первых "Центральный объект" без учета численности вовсе не обязательно совпадает со столицей, во-вторых, учет "веса" данного фактора приводит к смещению Центрального объекта, и это смещение тем больше, чем больше размер страны (опция Case алгоритма) чем больше городов и чем выше разницы в численности населения между ними.
Рис. 4.15 Города Европы: Центральные объекты (голубые пунсоны), Центральные Объекты с учетом "веса" (синие пунсоны)
Аналогичная ситуация с Медианным центром, можно наблюдать отчетливое смещение на расстояние в 200 и даже 300 км
Рис. 4.16 Города Европы: Медианные центры (розовые пунсоны), Медианные Центры с учетом "веса" (брусничные пунсоны)
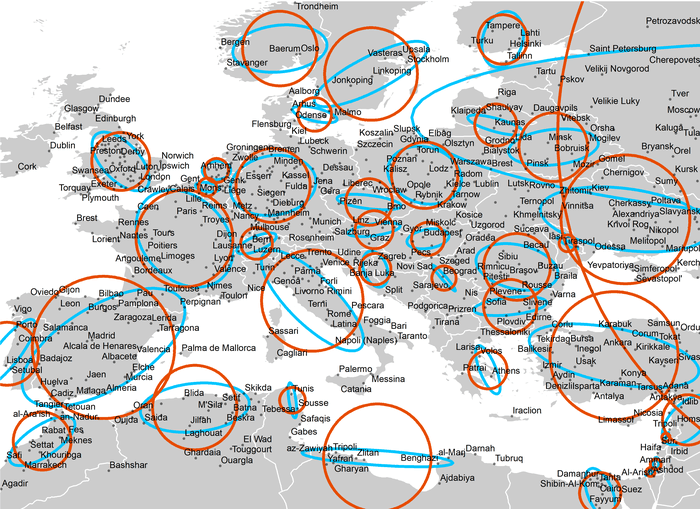
Весьма интересны также результаты алгоритмов Cтандартное расстояние и Эллипс стандартного отклонения.
Рис. 4.17 Города Европы: Стандартное отклонение (оранжевые окружности) и Эллипс стандартного отклонения (голубые эллипсы)
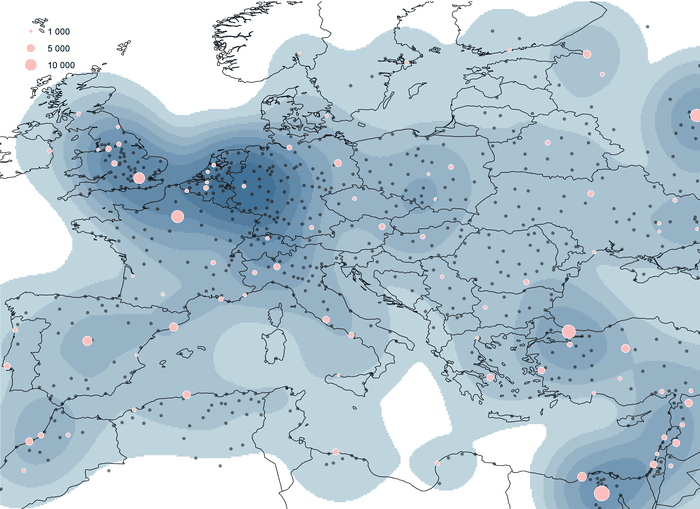
Но безусловно, наиболее наглядно влияние "веса" в плотностных характеристиках (Рис. 4.18)
Рис. 4.18 Города Европы: Плотность ядер с расстояниями 500 км, 700 км и 1000 км
Корректно подобранное расстояние позволяет выявить ареалы "плотной урбанизации"; превышение расстояния сильно огрубляет картину, хотя и такой результат может оказаться полезным для решения определенных задач.
Таким образом, методы центрографической статистики представляют собой начальный этап исследования любого географического феномена, на котором решаются важные задачи поиска "центральных мест" процесса или явления, расчета базовых дистанционных статистик, и определения типологии пространственного распределения - рандомного, дисперсного или кластерного. Кроме фиксации паттернов локализации множества точек исследователь может оценить роль факторов "веса", т.е., тех или иных атрибутов, и понять в какой степени они изменяют чисто пространственную картину распределения объектов или явлений. Плотностные функции, в свою очередь, позволяют перейти от множества точек (воспринимаемых как места в географическом пространстве) к сплошным "полям", характеризующим потенциальную "напряженность" фактора и/или феномена, что может оказаться важным для многих практических целей, например - при интерполяции загрязнения депонирующих сред (почв, илов) в пределах городской застройки, проводимой на основе конечного набора локальных "точечных" данных.