I. ОСНОВЫ ПРОСТРАНСТВЕННОГО АНАЛИЗА
5. ПРОСТРАНСТВЕННАЯ АВТОКОРРЕЛЯЦИЯ
5.1. Пространственная автокорреляция
Пространственная автокорреляция — это степень пространственной зависимости, связи или корреляции между значением переменной пространственного объекта и значениями той же переменной соседних объектов. Термины Spatial Association|Пространственная ассоциация и Spatial Dependence|Пространственная зависимость часто используются также для отражения пространственной автокорреляции. Пространственная автокорреляция исследуется чтобы определить, существуют ли взаимосвязи между значениями атрибутов близлежащих местоположений и образуют ли эти значения паттерны в пространстве.
По сути, пространственная автокорреляция - это содержательное продолжение анализа причинно-следственных связей между зависимой переменной и предикторами, призванное зафиксировать наличие и локализацию кластеров с высокими значениями - так называемые hot spot|горячие точки, а также отследить пространственные выбросы. Помимо этого пространственная автокорреляция - это еще и интерпретация статистической значимости результатов, используемая в том числе для оценки соответствия масштаба анализа масштабу анализируемого явления [Grekousis, 2020].
Таким образом, пространственная автокорреляция - это метод оценки пространственной зависимости данных, каковая может наблюдаться в соответствии с "первым законом географии" постулирующим, что объекты по соседству, как правило, имеют больше сходств и взаимодействий, чем объекты, расположенные дальше [Tobler, 1970]. Проще говоря, пространственная автокорреляция измеряет, насколько значение переменной в определенном местоположении связано со значениями той же переменной в соседних местоположениях.
Автокорреляция существует, когда атрибутивная переменная пространственного набора данных коррелирует сама с собой на определенных расстояниях, называемых lags|лагами. Это означает, что местоположение влияет на значения переменной таким образом, что способствует кластеризации значений в определенных ареалах. Типичным примером положительной пространственной автокорреляции является распределение доходов внутри города, когда домохозяйства с более высокими доходами, как правило, группируются в определенных районах города, в то время бедные домохозяйства сосредотачиваются в других районах.
Различают два масштабных уровня пространственной автокорреляции: первый, называемый (не слишком удачно) Global Autocorrelation|Глобальной автокорреляцией, и второй, именуемый Local Autocorrelation|Локальной автокорреляцией. Эти понятия не связаны жестко с размерностью и масштабом и скорее апеллируют к вышеприведенному примеру с пабами Лидса: мы можем проводить исследования в границах целого города (изучая "глобальную автокорреляцию"), а можем выбрать отдельные районы (центр, периферию) и использоваться "локальную автокорреляцию".
Для определения пространственной автокорреляции используются несколько диагностических показателей. Показатели, которые оценивают пространственную автокорреляцию по одному значению для всей исследуемой области и считаются глобальными мерами пространственной автокорреляции, включают:
Общий Индекс G-статистики Гири
Для оценки пространственной автокорреляции на локальном уровне используются локальные показатели пространственной автокорреляции, такие как:
Локальный Индекс I Морана,Локальный Индекс G-статистики Гири
Следует понимать, что пространственная корреляция не обязательно означает наличие причинно-следственной связи; она подразумевает только ассоциацию.
5.2. Глобальный Индекс Морана и Общая G-статистика
Инструмент Moran’s Index I|Индекс Морана вычисляет глобальную пространственную автокорреляцию, принимая во внимание одновременно и местоположения объектов, и значения атрибутов, и вычисляя среднее значение, отклонение от среднего значения и дисперсию данных [O'Sullivan, Unwin, 2010, стр. 206]. Результат - Точечные диаграммы Морана - интерпретируется на основе ожидаемого значения, рассчитанного в соответствии с нулевой гипотезой об отсутствии пространственной автокорреляции ("полная пространственная случайность"), и статистически оценивается с использованием P-значения и Z-балла - так же, как и любая другая выводимая статистика|inferential statistic.
Ожидаемое значение - это значение, которое было бы получено, если бы конкретный набор данных был результатом полной пространственной случайности. Поскольку ожидаемое значение рассчитывается как:
E = -1/ (n-1)
где n - число пространственных объектов,
то чем больше объектов, тем больше ожидаемое значение стремится к нулю.
Наблюдаемое значение индекса Морана - это значение, рассчитанное для конкретного набора данных.
Положительные наблюдаемые значения индекса Морана I, заметно превышающие ожидаемое значение, указывают на кластеризацию и положительную пространственную автокорреляцию (т.е., близлежащие местоположения имеют аналогичные значения). Отрицательные наблюдаемые значения индекса Морана I, меньшие, чем ожидаемое значение, указывают на отрицательную пространственную автокорреляцию или "тренд дисперсии", что означает, что соседние местоположения имеют разные значения исследуемой переменной. Значения, близкие к ожидаемому значению, указывают на отсутствие автокорреляции. Разница между наблюдаемыми и ожидаемыми значениями оценивается на основе Z-балла и P-значения. С помощью этих показателей мы оцениваем, является ли эта разница статистически значимой.
Если значение P велико (P > 0,05), результаты не являются статистически значимыми, и мы не можем отвергнуть нулевую гипотезу о том, что пространственное распределение значений является результатом полной пространственной случайности. Небольшое значение P (P < 0,05) указывает на то, что мы можем отвергнуть нулевую гипотезу о полной пространственной случайности и принять, что пространственная автокорреляция существует. В этом случае Z-значение позволяет оценить характер пространственной автокорреляции: при положительном Z-значении наблюдается положительная пространственная автокорреляция и расположенные рядом точки будут иметь сходные отклонения от среднего значения (либо высокие, либо низкие). Если Z-значение отрицательное, то имеет место отрицательная пространственная автокорреляция и рассеянный набор значений, в котором близлежащие местоположения будут иметь разные значения атрибутов на противоположных сторонах среднего значения (т.е., объект с высоким значением как бы отталкивает другие объекты с низкими значениями).
Хорошей иллюстрацией пространственной автокорреляции может служить обычная шахматная доска и различные варианты ее раскраски [Grekousis, 2020]. В идеально распределенном паттерне шахматной доски клетки расположены таким образом, что у каждой из них есть соседи противоположного цвета (черные у белой клетки и белые у черной клетки). Индекс Морана для шахматной доски получает отрицательное (меньшее, чем ожидаемое) значение, и свидетельствует о наличии отрицательной пространственной автокорреляции. Положительная пространственная автокорреляция будет наблюдаться если мы "разведем" черные и белые клетки шахматной доски по противоположным углам, разделив их воображаемой диагональю: в этом случае у нас будет два выраженных кластера (угол черных клеток и угол белых клеток), а Индекс Морана получит положительное, значительно больше ожидаемого значение. Другие варианта размещения черных и белых клеток на доске (т.е., не "классическое" и не кластерное) будут давать значения Индекса Морана близкие к нулю и таким образом фиксировать обстоятельство случайного распределения.
Рассчитаем в ArcMAP10.x глобальную пространственную автокорреляцию некоторых показателей нашей модели (преступности, заболеваемости и доходов) по полигональному файлу кварталов Нью-Йорка NYCTRACTs, используя Global Moran's I:
Input Feature Class: NYCTRACTs
Input Field: Murdr_15y
Generate Report: Check the box
Conceptualization of Spatial Relationships = INVERSE_DISTANCE
Distance: EUCLIDEAN_DISTANCE
Standardization: ROW (*Пространственные веса СТРОК стандартизированы, каждый вес делится на сумму строк - сумму весов всех соседних объектов)
Distance Band or Threshold Distance|Диапазон расстояний или Пороговое расстояние: оставляем пустым
Показатели пространственной автокорреляции доступны в Results (Main Menu >> Geoprocessing >> Results >> Current Session >> Spatial Autocorrelation) = C:\Users\ArcGIS\MoransI_Result1.html, где кроме показателей Z-оценки и P-значения доступны график а также "сообщение":
Given the z-score of 76.7040522927, there is a less than 1% likelihood that this clustered pattern could be the result of random chance.Moran's Index: 0,342806
Expected Index: -0,000475
Variance: 0,000020
z-score: 76,704052
p-value: 0,000000
Distance Threshold: 10079,9475 US_Feet
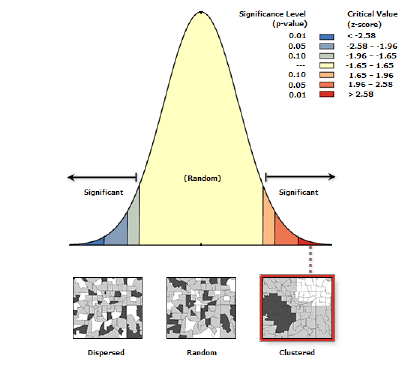
Рис. 5.1 График Отчета Spatial Autocorrelation|Анализа пространственной автокорреляции Морана для переменной Число убийств в кварталах Нью-Йорка
Для сравнения рассчитаем Глобальный индекс Морана для другой переменной - Доходов домохозяйств Нью-Йорка.
Moran's Index: 0,487167Expected Index: -0,000475
Variance: 0,000020
z-score: 108,932727
p-value: 0,000000
Distance Threshold: 10079,9475 US_Feet
Мы видим, что Индекс Морана значительно превышает ожидаемое значение 0,342806 против -0,000475, что указывает на кластеризацию и положительную пространственную автокорреляцию (т.е., расположенные по соседству кварталы будут иметь близкие значения преступности). Принимая во внимание крайне высокое значение Z-оценки 76,704052 и нулевое P-значение мы можем констатировать что кластерное распределение изучаемого явления закономерно; дополнительное подтверждение - график html-отчета (Рис. 5.2).
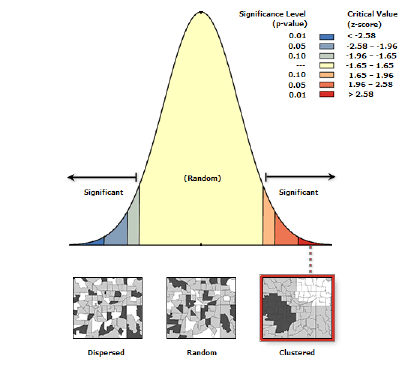
Рис. 5.2 График Отчета Spatial Autocorrelation анализа Пространственной Автокорреляции Морана для переменной "Доход домохозяйств" в кварталах Нью-Йорка
Кластерность и "неслучайность" распределения Дохода домохозяйств по кварталам Нью-Йорка также не подлежит сомнению, поскольку мы имеем еще большее превышение Индекса Морана над ожидаемым значением 0,487167 против <-0,000475) и еще более высокий Z-балл 108,9. Обратим внимание на то обстоятельство, что поскольку в обоих случаях расчет Глобального индекса Морана велся по одной и той же сетке, мы получили и одинаковую величину Distance Threshold|Порогового значения - 10079,9475 US_Feet, составляющую чуть более 3 км (3072 м).
Итак, Глобальный индекс Морана - надежный алгоритм, позволяющий принять или опровергнуть "нулевую гипотезу" о пространственной автокорреляции для множества точек и любой сети операционно-территориальных единиц (полигонов, нагруженных разными переменными), и, таким образом, выявить неслучайное кластерной или дисперсное поведение исследуемого феномена. Заметим, что Индекс Морана может свидетельствовать о наличии кластеризации явления, но он не отличает кластеров высоких значений от кластеров низких значения. Для разделения таких кластеров используется Общий индекс Getis-Ord G - еще один статистический индекс, позволяющий обнаружить кластеры низких значений ("холодные точки") или высоких значений ("горячие точки") и являющийся показателем пространственной взаимосвязи [Ord, Getis, 1995].
Общий G-Индекс используется для ответа на вопрос о том, вызвана ли обнаруженная автокорреляция кластеризацией высоких значений или кластеризацией низких значений. Значения G-Индекса варьируется от 0 до 2: при этом значение 1 обычно указывает на отсутствие пространственной автокорреляции. Значения, значительно меньшие 1, указывают на положительную пространственную автокорреляцию, в то время как значения, значительно большие 1, указывают на отрицательную пространственную автокорреляцию [O’Sullivan, Unwin, 2010]. Как и в случае с Индексом Морана результаты G-Индекса интерпретируются на основе Z-оценки и P-значения, которые позволяют либо принять либо отклонить нулевую гипотезу о полной пространственной случайности.
Аналогичны и правила интерпретации. Когда значение P невелико P < 0,05, нулевая гипотеза отвергается, и имеются статистически значимые доказательства кластеризации, далее:
(a) Если Z-оценка положительная и наблюдаемое общее значение G-статистики больше ожидаемого, это указывает на концентрацию высоких значений (горячих точек).(b) Если Z-оценка отрицательная и наблюдаемое общее значение G-статистики меньше, ожидаемого это указывает на то, что низкие значения (холодные пятна) сгруппированы в ареалах исследуемой области.
Рассчитаем Getis-Ord General G-statistic для преступности и дохода домохозяйств по кварталам Нью-Йорка в ArcMAP10.x, воспользовавшись инструментом из набора Пространственная Статистика, который так и называется High/Low Clustering|Кластеры Высоких и Низких Значений.
Input Field: Murdr_15y
Generate Report: Check the box
Conceptualization of Spatial Relationships: INVERSE_DISTANCE
Distance: EUCLIDEAN_DISTANCE
Standardization: ROW
Distance Band or Threshold Distance: Leave blank
Доступ к результатам -как обычно через Геообработку: Main Menu >> Geoprocessing >> Results >> Current Session >> High/Low Clustering (Getis-Ord General G)>> DC on GeneralG_Results .html:
Observed General G: 0,000017Expected General G: 0,000009
Variance: 0,000000
z-score: 8,142788
p-value: 0,000000
Значение G-Индекса в два раза больше ожидаемого при высоком положительном значении Z-оценки и "доверительном" (< 0,05) P-значении свидетельствует о кластеризации "горячих" точек - вывод, подтверждаемый и Графиком, и "подсказкой":
Given the z-score of 38.1427875193, there is a less than 1% likelihood that this high-clustered pattern could be the result of random chance.
Поскольку G-Индекс значительно меньше единицы, следовательно можно говорить о положительной пространственной автокорреляции.
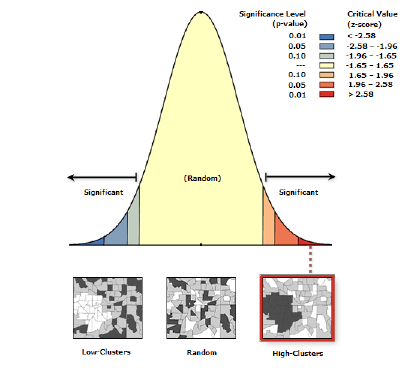
Рис. 5.3 График Отчета High-Low Clustering анализа для переменной Число убийств в кварталах Нью-Йорка
Рассчитаем G-Индекс для Дохода домохозяйств по кварталам Нью-Йорка:
Observed General G: 0,000009Expected General G: 0,000009
Variance: 0,000000
z-score: 0,032577
p-value: 0,974012
Значения ожидаемого и расчетного General G одинаковы, при этом P-значение больше 0,5 и Z-оценка меньше 0,05 - признаки рандомного распределения; в "послании" html_отчета читаем:
Given the z-score of 0.032577, the pattern does not appear to be significantly different than random.
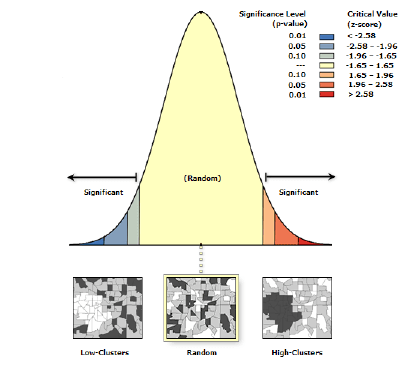
Рис. 5.4 График Отчета High-Low Clustering анализа для переменной Доход домохозяйств в кварталах Нью-Йорка
Следовательно, несмотря на наличие "кластерности", выявленное с помощью Индекса Морана, скопления высоких значений (горячих точек) не обнаруживают пространственной закономерности - они случайны.
5.3. Пошаговая пространственная автокорреляция
Пошаговая пространственная автокорреляция|Incremental Spatial Autocorrelation - метод, основанный на индексе Global Moran's I для проверки наличия пространственной автокорреляции в диапазоне расстояний, позволяющий выявить шаг изменчивости признака в пространстве. Вместо произвольного выбора дистанций этот метод определяет соответствующий фиксированный диапазон расстояний, для которого пространственная автокорреляция более выражена. Другими словами, алгоритм определяет самое дальнее расстояние, на котором объект все еще оказывает значительное влияние на другой. После установления соответствующей шкалы анализа можно более точно рассчитать локальные пространственные индексы автокорреляции и другую пространственную статистику.
Алгоритм Пошаговая пространственная автокорреляция измеряет автокорреляцию для ряда расстояний и при необходимости создает линейный график этих расстояний и соответствующих Z-оценок. Статистически значимые пиковые Z-оценки указывают расстояния, на которых пространственные процессы, способствующие кластеризации, наиболее выражены.
Выбор подходящего масштаба анализа для выстраиваемой модели является одной из самых сложных задач в пространственном анализе. Масштаб анализа определяет размер и форму районов, для которых рассчитывается пространственная статистика, и тесно связан с рассматриваемой проблемой. Исследователи и аналитики, не имеющие глубокого понимания проблемы, часто склонны применять инструменты пространственной статистики, основанные на предопределенных значениях по умолчанию (default). Между тем, некритический выбор расстояния анализа может приводить к некорректным оценкам и неправильным выводам. Ситуация осложняется тем, что в реальном пространстве кластеризация может оказаться значимой одновременно на разных пространственных уровнях: например, на уровне кварталов и на уровне районов города. Иными словами "дьявол кроется в мелочах". По этой причине Пошаговую пространственную автокорреляцию рекомендуют проводить с предварительным выбором освобождением от значений-выбросов. В качестве начального расстояния необходимо выбрать то, которое гарантирует, что у каждого объекта есть хотя бы один сосед [Grekousis, 2020].
Рассчитаем Пошаговую пространственную автокорреляцию для кварталов Нью-Йорка по полю Числа тяжких преступлений за 15 лет (ArcToolBox >> Spatial Statistics Tools >> Analyzing Patterns >> Incremental Spatial Autocorrelation).
Input Feature Class: NYCTRACTs
Input Field: Murdr_15y
Number of distance bands: 10
Beginning Distance: Leave blank
Distance Increment: Leave blank
Distance: EUCLIDEAN
Row Standardization: Check the box
Output Table: ... Increment
Output Report File: .... Increment.pdf
Алгоритм выводит PDF-файл отчета и отдельную таблицу. По графику Distance в файле отчета можно судить о "пиковом" расстоянии, на котором наблюдается кластеризация изучаемой переменной (Рис. 5.5). В данном случае - это дистанция около 15214 футов (или 4,64 км).
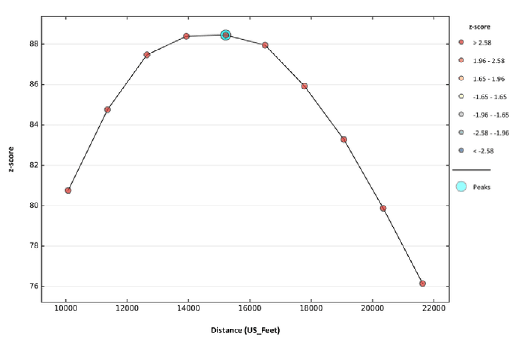
Рис. 5.5 График Пошаговой пространственной автокорреляции для переменной Число убийств за 15 лет в кварталах Нью-Йорка
По таблице PDF-отчета (Рис. 5.6) мы можем видеть, что значению дистанции 15214 соответствуют наибольшее значение Z и положительный Индекс I Морана 0,224595, что подтверждает сделанный ранее вывод о наличии кластеризации и положительной пространственной автокорреляции.
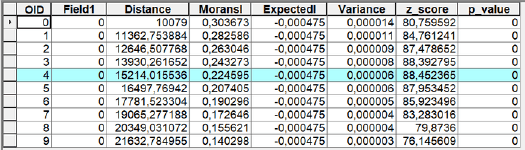
Рис. 5.6 Скриншот таблицы Incremental Spatial Autocorrelation для переменной Число убийств за 15 лет в кварталах Нью-Йорка
Следующий шаг Анализа Пространственной автокорреляции - Generate Spatial Weights Matrix|Вычисление матрицы пространственных весов. Дистанция максимальной автокорреляции, полученная в качестве "пикового" расстояния Incremental Spatial Autocorrelation, используется для вычисления Матрицы весов таким образом, что объекты, расположенные дальше этого расстояния, не будут включены в расчет функции веса. Одновременно устанавливается минимальное число соседей, и если в пространстве порогового значения эти число не обеспечивается - дистанция увеличивается до включения установленного минимума (скажем 3 или 4 соседа).
Input Feature Class = NYCTRACTs
Unique ID Field: FID
Output Spatial Weights Matrix File: ... NYCTRACTs.swm
Conceptualization of Spatial Relationships: FIXED_DISTANCE
Distance Method: EUCLIDEAN
Exponent: 1
Threshold Distance: 15214 (как результат пошаговой пространственной автокорреляции в Incremental Spatial Autocorrelation)
Number of Neighbors: 3
Row Standardization: Check
Результирующий файл выводится в нечитаемом формате swf: чтобы отредактировать веса для каждого набора пространственных объектов, мы должны преобразовать swf-файл в таблицу с помощью функции Convert Spatial Weights Matrix to Table|Преобразовать пространственные веса в таблицу.

Рис. 5.7 Скриншот таблицы Пространственных Весов
Типичная матрица пространственных весов в ArcMAP10.x состоит из трех столбцов:
ID - уникальный идентификатор пространственного объекта,NID - идентификатор соседнего объекта, с которым существует связь,
WEIGHT - значение веса, которое количественно определяет пространственную связь.
По таблице (Рис. 5.7) мы можем судить, что, например, объект (квартал с ID 2089 ) связан с пятью другими объектами (кварталами) и вес этой связи 0,2. Таблица Весов не представляет самостоятельного интереса, но она используется в локальных индексах, в частности - в Локальном индексе Морана.
5.4. Анализ кластеров и выбросов
Глобальные индексы пространственной автокорреляции определяют, есть ли кластеризация в значениях переменной, но они не указывают, где расположены кластеры. Чтобы определить местоположение и величину пространственной автокорреляции, мы должны использовать локальные индексы, в частности Local Moran’s I or Cluster and Outlier Analysis|Локальный Индекс Морана или Анализ кластеров и выбросов.
Локальный индекс Морана I интерпретируется на основе ожидаемого значения, P-значения и Z-оценки в соответствии с нулевой гипотезой об отсутствии пространственной автокорреляции. При расчете Локального индекса Морана используется величина Пространственного веса. Как и в случае с Глобальным индексом Морана положительные наблюдаемые значения Локального индекса Морана I, значительно превышающие ожидаемое значение, указывают на потенциальную кластеризацию. Отрицательные наблюдаемые значения Локального индекса Морана I, значительно меньшие, чем ожидаемое значение, указывают на потенциальное наличие пространственных выбросов. Значения, близкие к ожидаемому значению, указывают на отсутствие автокорреляции [Grekousis, Gialis, 2018].
Небольшие P-значения < 0,05 указывает на то, что мы можем отвергнуть гипотезу о полной пространственной случайности и признать, что пространственная автоматическая корреляция существует. В этом случае если Z-оценка положительная > 0, мы имеем положительную пространственную автокорреляцию и кластеризацию. Высокая положительная Z-оценка (например, больше 2,60) для пространственной сущности означает, что образуются кластеры High-High - пространственные сущности с высокими значениями (для конкретной переменной) окружены пространственными сущностями высоких значений (одной и той же переменной). Если Z-оценка отрицательная (< 0), наблюдается отрицательная пространственная автокорреляция, причем когда значения низкие, то образуются кластеры Low-Low, что означает, что пространственные объекты с низкими значениями окружены пространственными объектами низких значений [Anselin, 2010].
Рассчитаем Локальный индекс Морана I относительно преступности, и доходов домохозяйств чтобы определить, существуют ли кластеры и выбросы по данному параметру среди кварталов Нью-Йорка.
Input Feature Class: NYCTRACTs
Input Field: Murdr_15y (*income - для анализа по доходам)
Output Feature Class: LocalMoranI_Murdr.shp
Conceptualization of Spatial Relationships: GET_SPATIAL_WEIGHTS_FROM_FILE
Weights Matrix File: Tracts_Spatial_Weights
Apply False Discovery Rate (FDR) Correction: Check
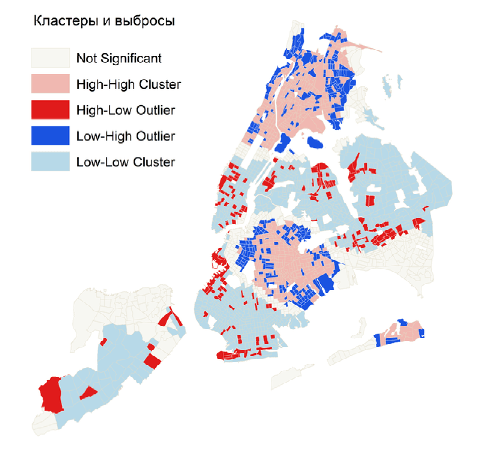

Рис. 5.8 Кластеры и Выбросы: a) для переменной Число убийств, b) Доходы домохозяйств в кварталах Нью-Йорка
Для интерпретации результатов полезно помнить, как расшифровываются значения пяти классов легенды картограммы LocalMoranI|Локального индекса Морана, два из которых соответствуют кластерам, два - выбросам и один - фону. Продемонстрируем это на примере переменной дохода:
Not Significant - фоновые значения, которые нельзя отнести ни к "горячим" (кварталам с высоким значением доходов домохозяйств), ни к "холодным" (кварталам с низкими доходами);High-High Cluster (HH в таблице файла) - кластер кварталов с высокими значениями доходов, т.е., соседом каждого такого квартала является другой "высокодоходный" квартал;
Low-Low Cluster (LL в таблице файла) - кластер кварталов с низкими значениями доходов, когда соседом каждого такого квартала является другой "бедный" квартал;
High-Low Outlier (HL в таблице файла) - кварталы с контрастно высоким значением дохода, окруженные "бедными" кварталами;
Low-High Outlier (LH в таблице файла) - "бедные" кварталы, окруженные "богатыми" кварталами.
В нашем случае выявления возможных причин распределения феномена преступности обе полученные картограммы целесообразно рассматривать в сравнении. Легко заметить, что, например, в Бруклине и Бронксе кварталы с Low-High выбросами по числу убийств зачастую одновременно являются кварталами-выбросами High-Low по размеру дохода домохозяйств. В тоже время большая часть кварталов High-High кластера по доходам в Куинсе являются Low-Low кластерами в Куинсе и Статен-Айленде.
В дополнении к картограммам можно анализировать таблицы создаваемого алгоритмом слоя (Рис. 5.9), где в поле COType указывается, является ли объект (в нашем случае - квартал) выбросом или он принадлежит кластеру.
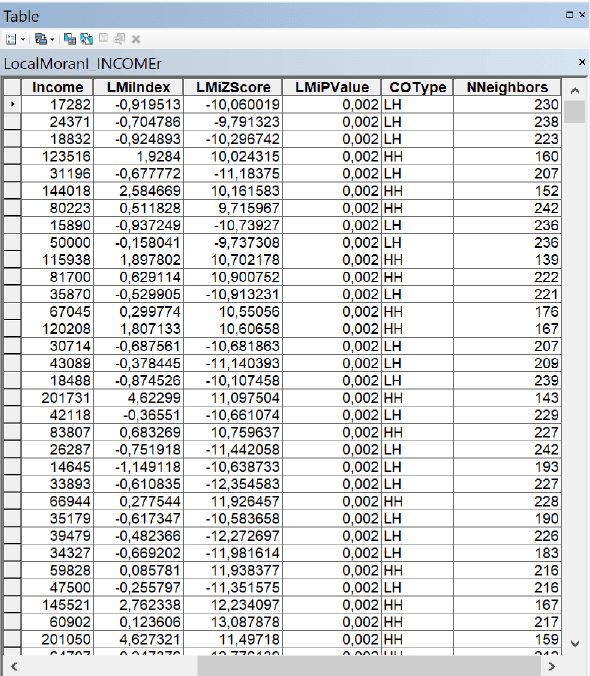
Рис. 5.9 Скриншот таблицы со значениями Локального индекса Морана для переменной Доходы домохозяйств в кварталах Нью-Йорка
Таблица файла Локального индекса Морана позволяет оценить не только класс распределения (кластер - выброс - фон) но и Z-оценку и P-значение для любого квартала или группы кварталов, что позволяет судить о знаке автокорреляции: положительная при положительных значениях Z и отрицательная - при отрицательных, соответственно статистическая значимость проверяется по P-значению в той же строке.
5.5. Анализ горячих точек
Hot Spot Analysis|Анализ горячих точек или Getis-Ord Gi*I - еще один алгоритм, который идентифицируют статистически значимые кластеры с высокими значениями (горячие точки) и кластеры с низкими значениями (холодные точки) и используются в качестве показателей пространственной взаимосвязи [Kleinschmidt et all, 2016].
Алгоритм рассчитывает Z-оценку и P-значение; которые интерпретируются также, как и в других инструментах рассматриваемой группы. Наличие высокой положительной Z-оценки и небольшого P-значения указывает на пространственную кластеризацию высоких значений (т.е., горячую точку), тогда как наличие низкой отрицательной Z-оценки с небольшим P-значением указывает на наличие холодных точек (пространственная кластеризация низких значений). В обоих случаях наблюдается положительная пространственная автокорреляция. Чем выше Z-оценка (положительная или отрицательная), тем интенсивнее кластеризация [O’Sullivan, Unwin, 2010].
Построим картограмму Анализа Горячих Точек последовательно для переменной преступлений и переменной дохода домохозяйств по кварталам Нью-Йорка.
Input Field: Murdr_15y, (*income - для анализа Доходов домохозяйств)
Output Feature Class: ... \HotSpotMurdr_15y.shp
Conceptualization of Spatial Relationships :GET_SPATIAL_WEIGHTS_FROM_FILE
Self Potential Filed: Leave blanc
Weights Matrix File: ...\TractsWeights.swm
Apply False Discovery Rate (FDR) Correction: Do not check (*статистическая значимость будет определяться P-значением и Z-оценкой)
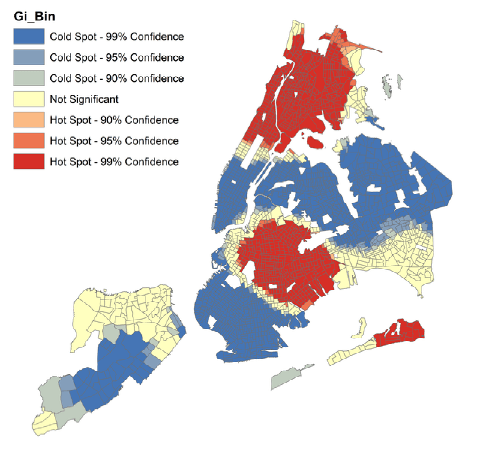
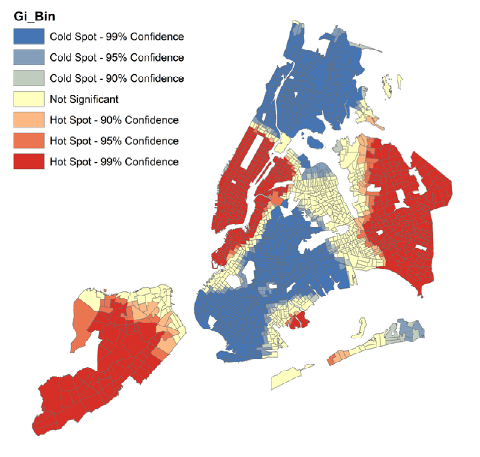
Рис. 5.10 Картограммы Анализа Горячих Точек в кварталах Нью-Йорка: a) для переменной Число убийств за 15 лет, b) Доходы домохозяйств
Алгоритм генерирует картограммы с семью классами:
Not Significant - в этих кварталах отсутствует кластеризация по рассматриваемой переменной или признаку;три типа кластеров "Cold Spot - холодных точек", в которых кварталы с низкими значениями окружены такими же с последовательно понижающейся вероятностью (Confidence 99%, 95% и 90%);
три типа кластеров "Hot Spot - горячих точек", в которых кварталы с высокими значениями окружены такими же с последовательно понижающейся вероятностью (Confidence 99%, 95% и 90%).
Сравнивая картограммы Анализа горячих точек по преступлениям и доходам домохозяйство можно констатировать их практически абсолютную (с незначительными отклонениями) противоположность: "горячие" (99%) кластеры кварталов с высоким числом убийств за 15 лет соответствуют "холодным" (99%) кластерам кварталов с низкими доходами, что, по крайней мере, отчасти, подтверждает гипотезу о социальных истоках преступности.
Так называемый Optimized Hot Spot Analysis|Оптимизированный анализ горячих точек ArcMAP10.x выполняет всю процедуру автоматизированным способом, что значительно экономит время анализа. Результаты аналогичны результатам Hot Spot Analysis. Выходное сообщение содержит информацию о масштабе анализа (в нашем случае 1157 м), а также о наличии (или отсутствии) локальных выбросов.
Input Feature Class = NYCTRACTs;
Input Field = Murdr_15y, (* income - для анализа Доходов домохозяйств);
Output Feature Class = ... \OptimizedHotSpotMurdr_15y.shp.
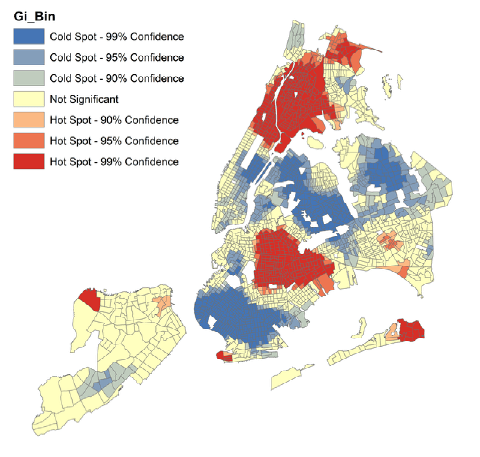
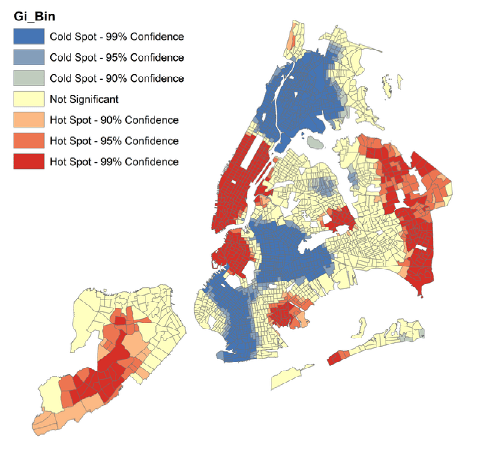
Рис. 5.11 Картограммы Оптимизированного анализа горячих точек в кварталах Нью-Йорка: a) для переменной Число убийств, b) Доходы домохозяйств
Как можно убедиться, Оптимизированный Анализ Горячих Точек демонстрирует более концентрированные и, возможно, точнее локализованные кластеры. Определенный интерес представляет и Messages, открывающийся в Результатах Геообработки.

Рис. 5.12 Скриншот сообщения Оптимизированного анализа горячих точек для переменной Число убийств за 15 лет в кварталах Нью-Йорка
Сообщение оповещает нас об общем количестве валидных 2108 кварталов, включенных в анализ, обнаруженном числе выбросов 34 outlier, которые не использовались для расчета оптимальной дистанции учета соседских объектов, а также о числе таких соседств 30 nearest neighbours и диапазоне их обнаружения 6105 футов (1861 м).
Таким образом, инструменты Пространственной Автокорреляции позволяют не просто обнаружить обстоятельство взаимосвязи расположения объектов и ассоциации их атрибутов, но и локализовать кластеры, разделив их на "холодные" (с пониженными значениями) и "горячие" (с повышенными значениями), а также - определить характерные дистанции их формирования. Все эти характеристики могут быть эффективно использованы в анализе как геоэкологических процессов (распространение и распределение загрязнений различных сред, конфигурирование ареалов заболеваемости с выявлением их центров), так и социально-экономических феноменов (величины и неравенства доходов, девиантного поведения и преступности, формирования центров разнообразных обслуживающих сетей и т.д.).