II. БАЗОВЫЕ ПРОЦЕДУРЫ АНАЛИЗА ДАННЫХ В ГЕОЭКОЛОГИИ
8. АНАЛИЗ ГРУППИРОВАНИЯ И КЛАСТЕРИЗАЦИЯ КАК СПОСОБЫ КЛАССИФИЦИРОВАНИЯ И РАЙОНИРОВАНИЯ
8.1. Районирование как типология и районирование как классификация
Районирование как типология и районирование как классификация – своего рода "классика географии", процедуры, предполагающие методы дифференциации (разделения) совокупности матрицы операционно-территориальных единиц (ОТЕ) по одному или нескольким признакам.
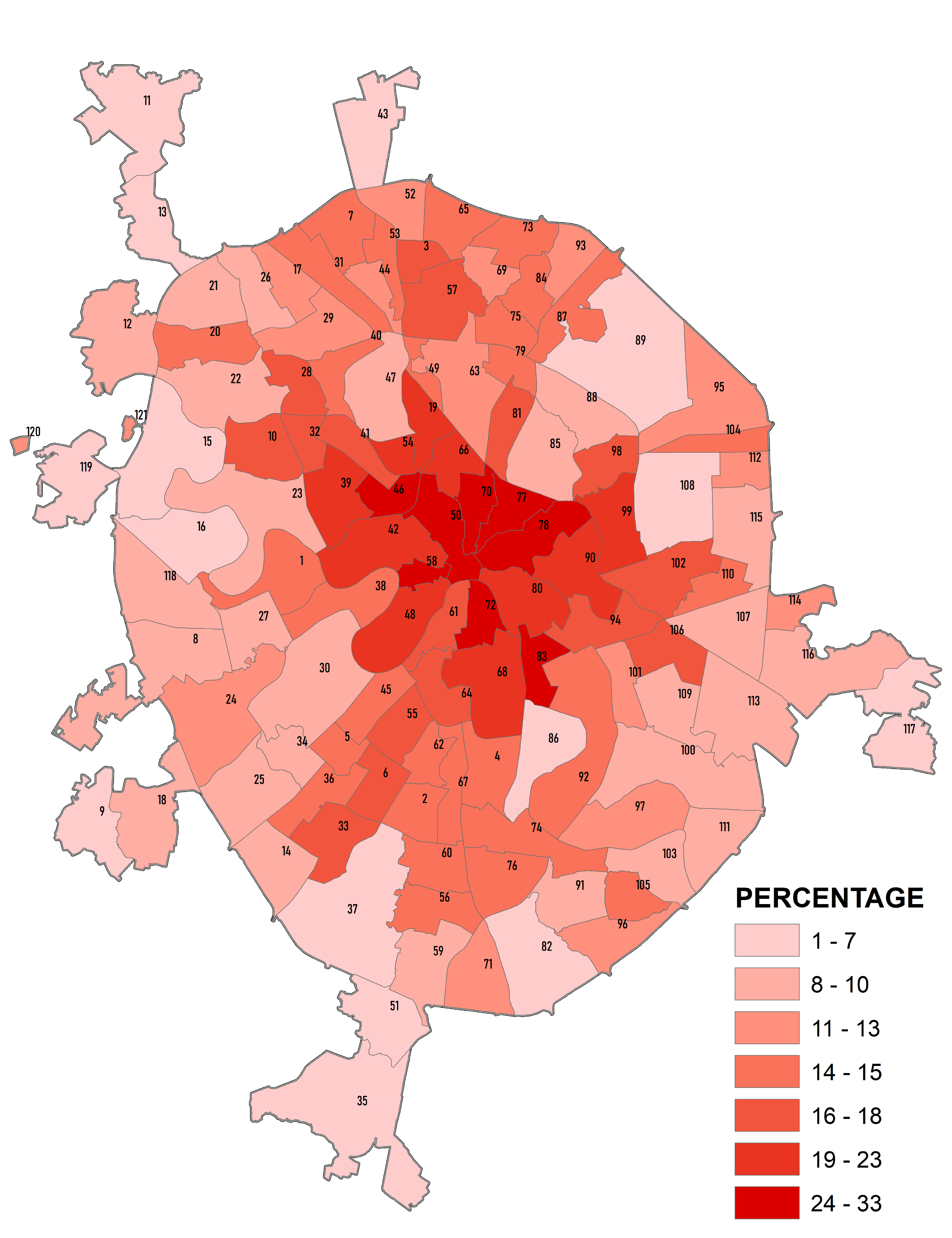
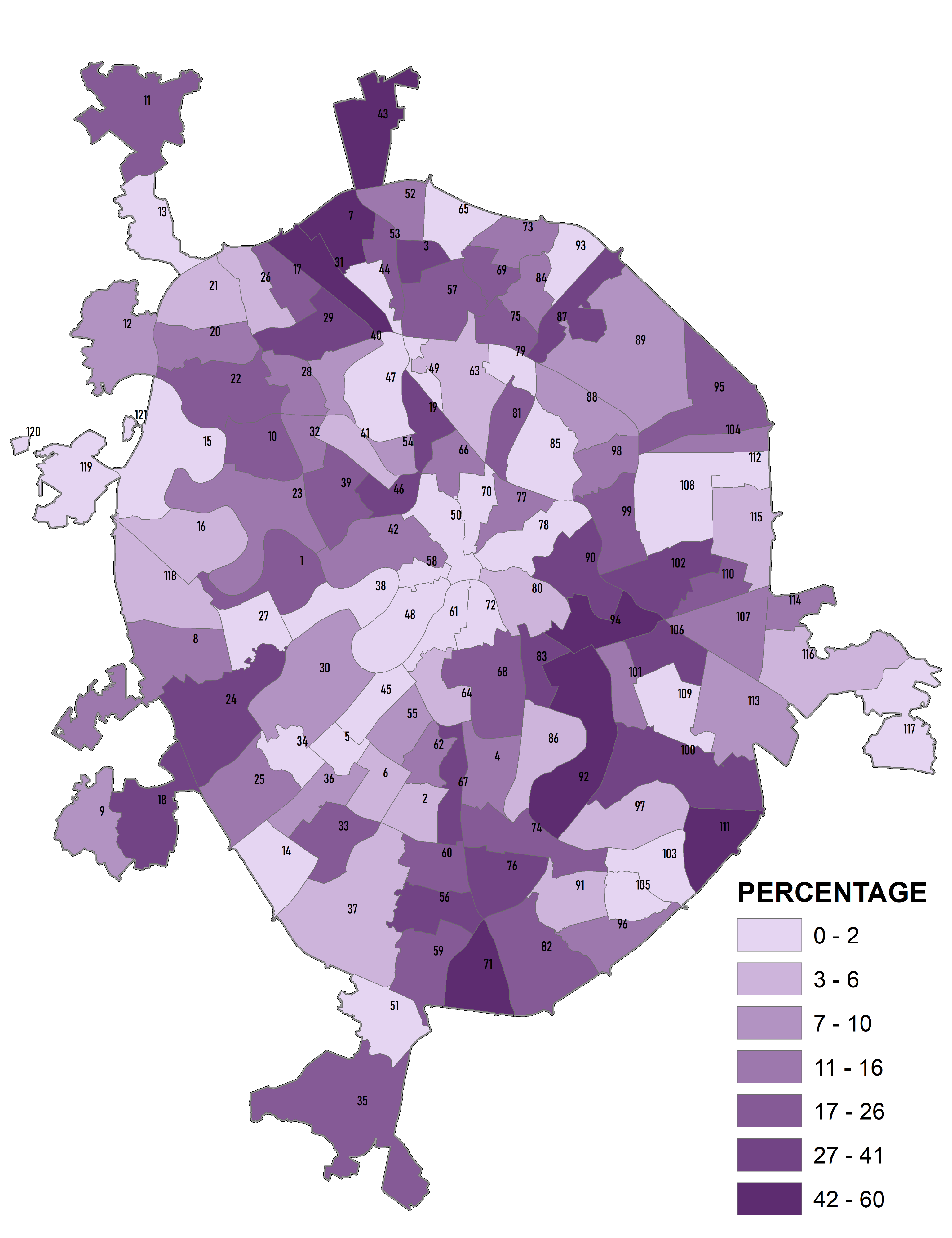
Здесь важно не запутаться в понятиях. Простейшая классификация может быть проведена по любому признаку или свойству. Так, если взять значения переменной с континуальной шкалой (например, значения абсолютной высоты), то имея показатель средней высоты для каждого района можно оформить картограмму, выбрав, например, 10 классов любым способом (равные интервалы или естественные границы) и это тоже будет "классификацией", поскольку в результате выделятся более "высокие", "низкие" или "средневысотные" районы (Рис. 8.1).
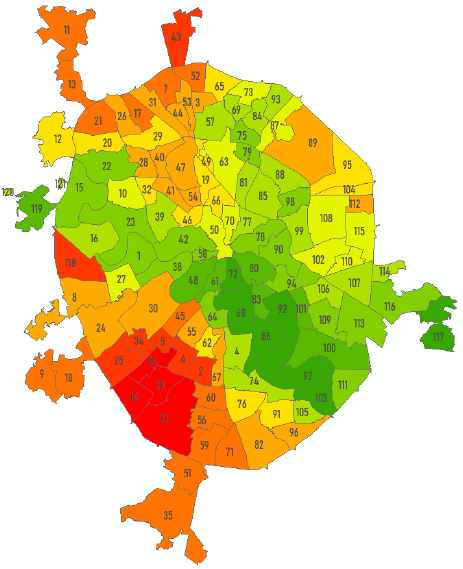

Рис. 8.1 Средняя высота поверхности районов "Старой" Москвы - 10 таксонов, выделенных способом "естественные границы"
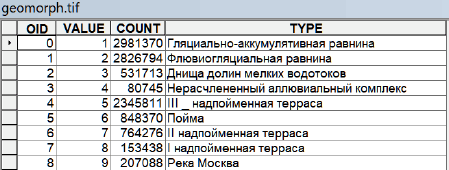
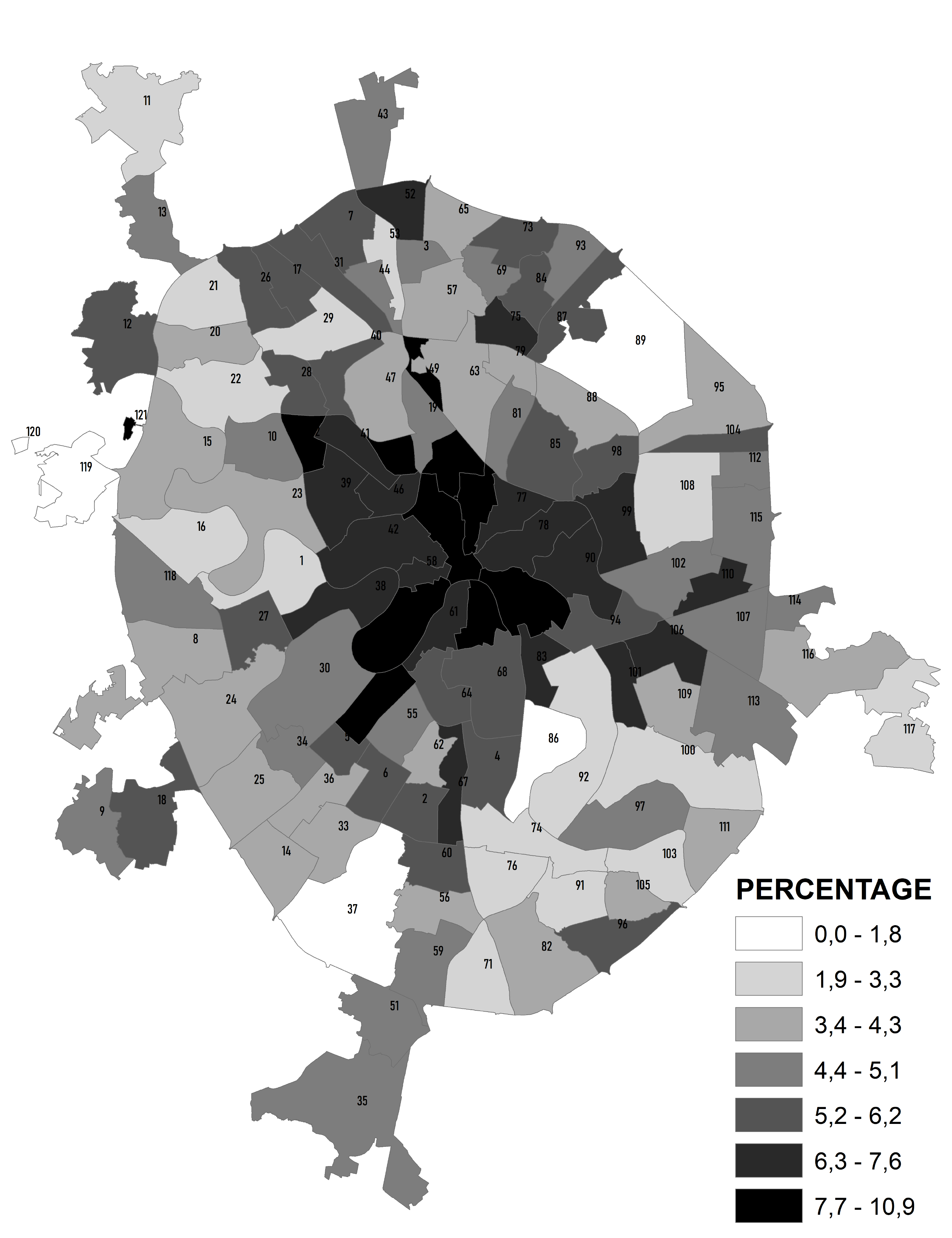
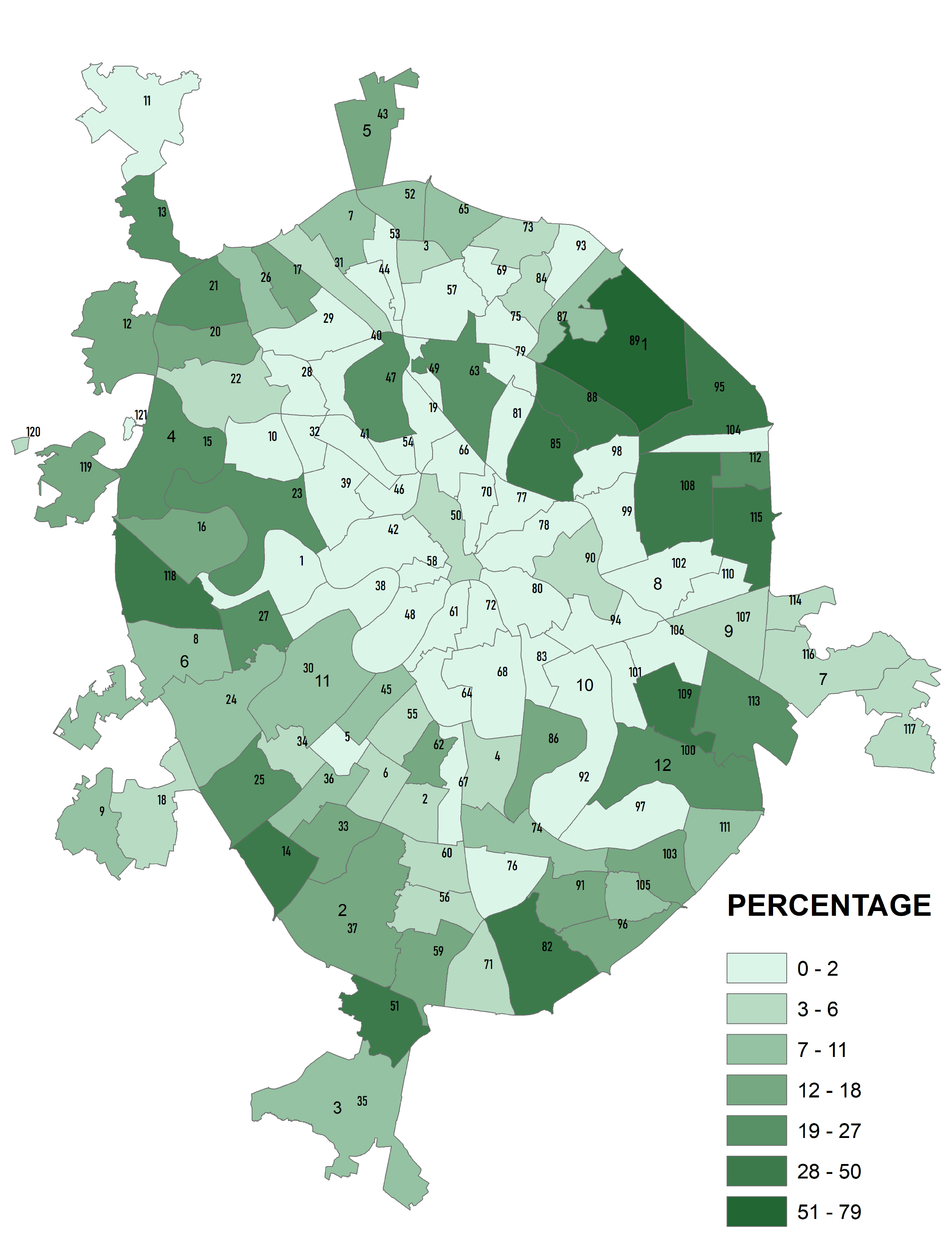
Сложнее обстоит дело с переменными, выражаемыми ранговыми или номинативными шкалами, такими как виды геоморфологических поверхностей, или типы земельно-ландшафтного покрова (LULC) – в этом случае единицы ОТЕ (районы) различаются долей площади каждого класса (Рис. 8.2).
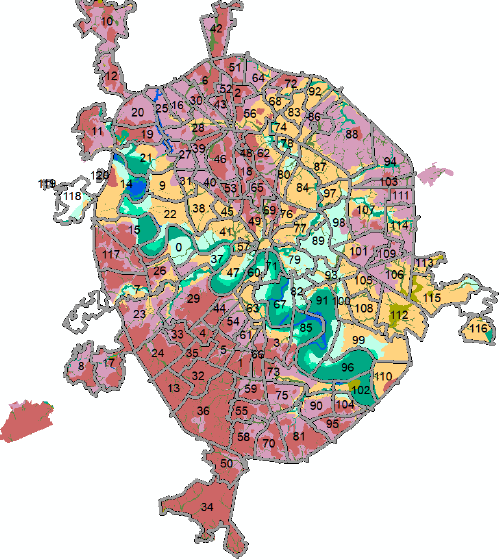

Рис. 8.2 Типы геоморфологических поверхностей в пределах административных районов "Старой" Москвы
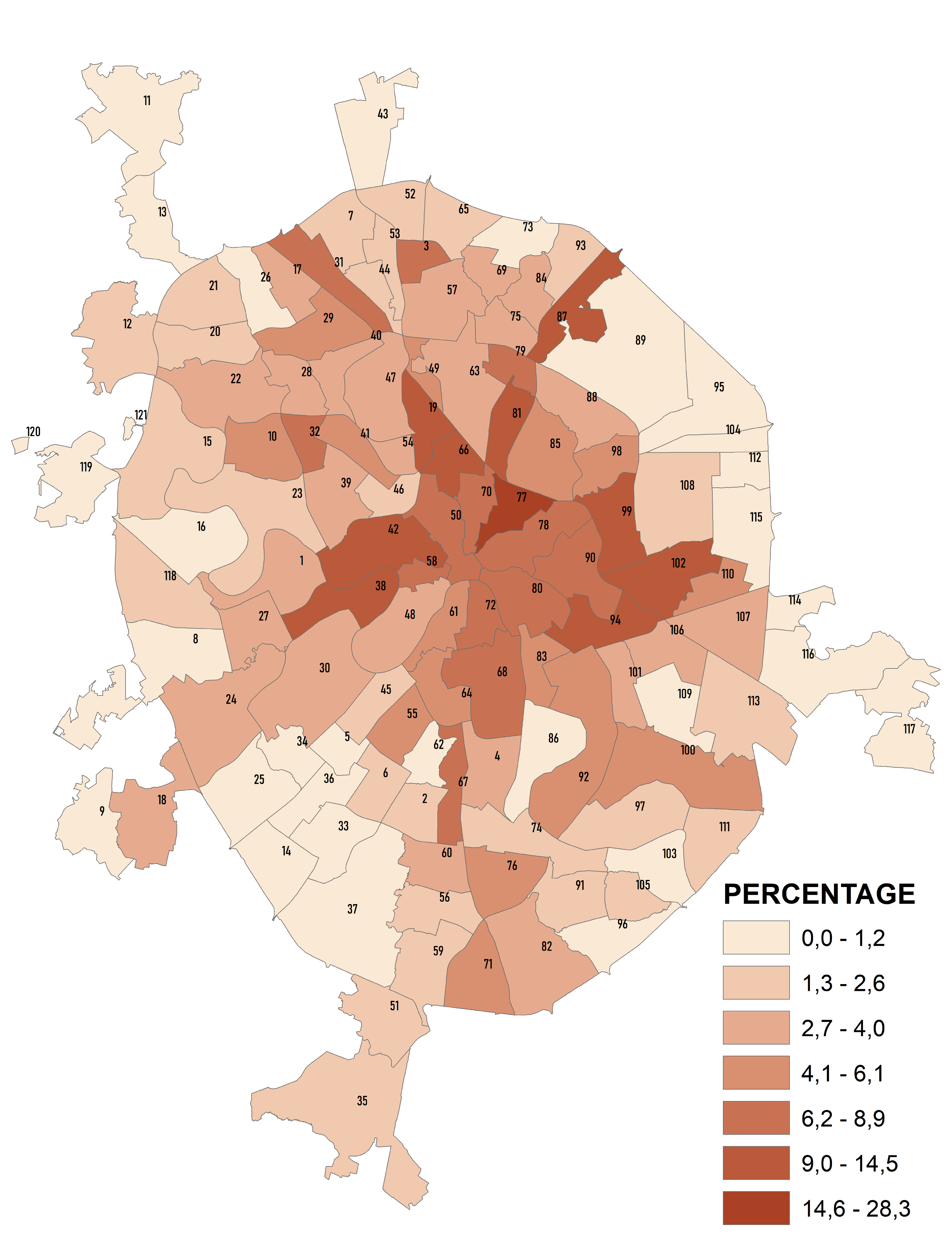
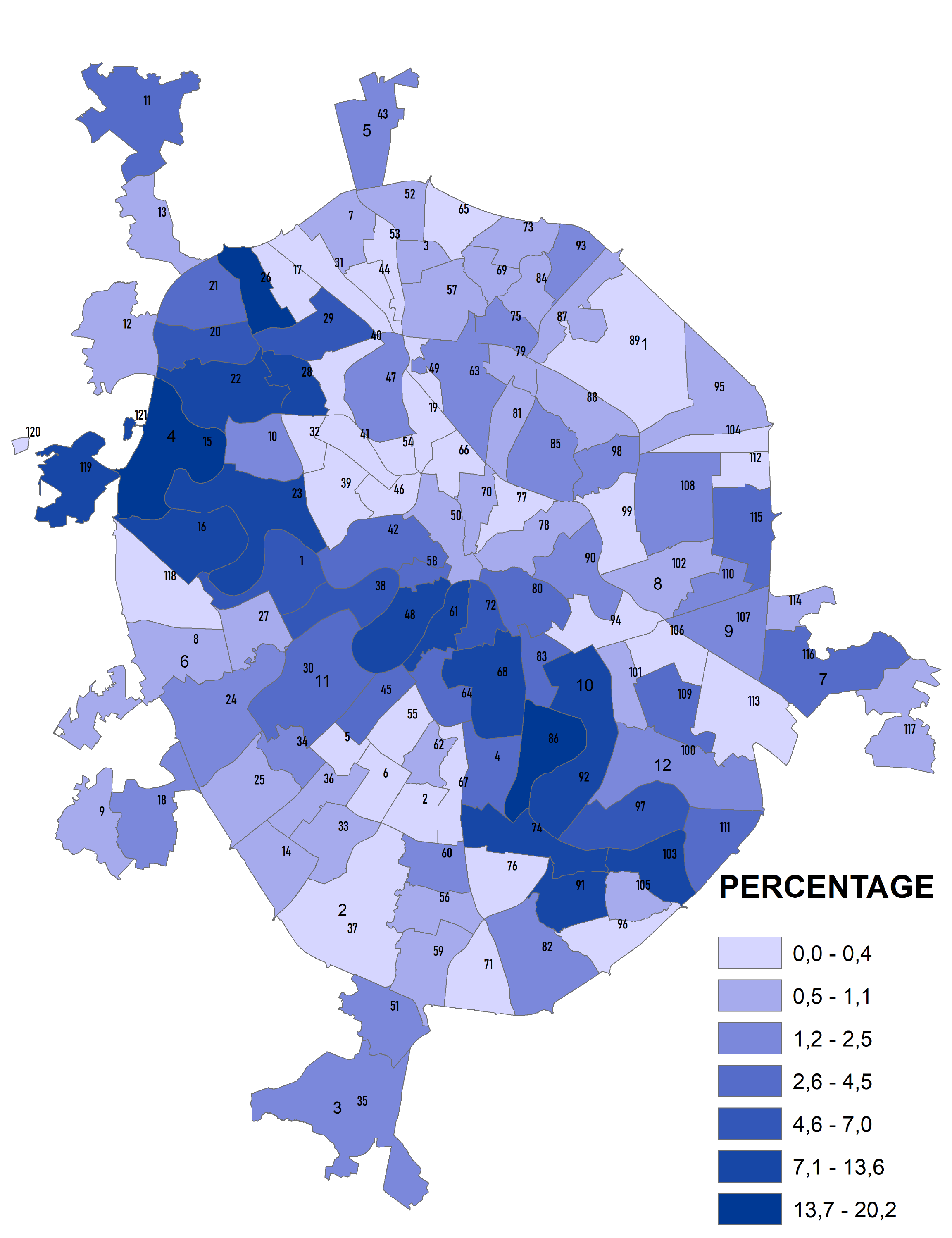
Можно строить картограммы по отдельным классам чтобы выяснить, например, какую долю занимают поймы в пределах разных районов. В результате отказа от индивидуальных значений площади пойм и перехода к интервалам значений мы получаем районирование, дифференцирующие районы Москвы по единственному признаку - доле пойменных поверхностей (Рис. 8.3).
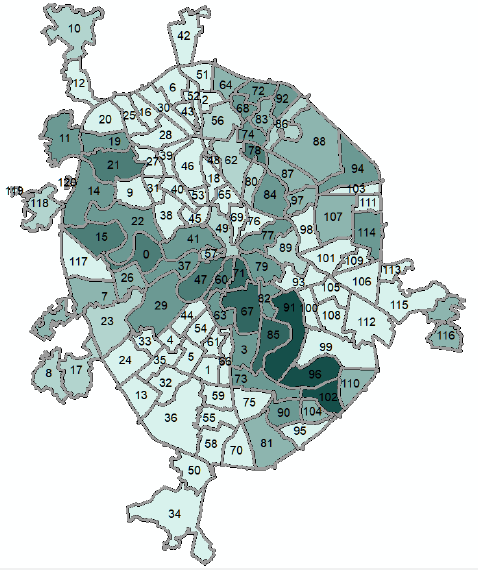
Рис. 8.3 Доля пойм в общей площади районов "Старой" Москвы
Но, допустим, что нас интересуют не только поймы, но и все остальные формы рельефа; иными словами, мы хотим получить ответы на два вопроса:
- Как различаются административные районы Москвы по представленности (есть-нет) и соотношению (доля площади) в их пределах разных форм рельефа?
- Каким образом можно сгруппировать административные районы по этим двум признакам?
Именно в таком порядке был бы озадачен вопросами специалист, пытающийся провести геоморфологическое "районирование" Москвы по административной сетке.
В современных геоинформационных системах для решения задач классификации множества объектов предлагается несколько инструментов кластерного анализа, которые с легкой руки разработчиков ESRI получили второе наименование (используемые в продуктах семейства ARCGIS) - Анализ Группирования; но мы должны понимать, что в данном случае "группы" это те же "кластеры", т.е., "таксоны" или "классы".
Эти инструменты реализованы в пакетах ArcMAP10.x (Анализ Группирования) и SAGA GIS (Кластерный Анализ). На наш взгляд имеет смысл применять их в комбинации (т.е., последовательно и совместно) – сравнивая (и выбирая) результаты процедуры, ибо в каждом из программных пакетов есть свои преимущества и свои недостатки.
Все сюжеты классифицирования и районирования можно разделить на две категории. Первая - сюжеты, когда число конечных классов известно, например, когда мы решаем задачу разделения множества местоположений по совокупности признаков на четыре известных класса (элювиальные, трансэлювиальные, трансаккумулятивные и аккумулятивные), или множество лесных выделов на шесть классов возраста. Вторая - сюжеты, когда нам неизвестно на какое число классов может быть разделено оптимальным образом множество объектов. Допустим, что есть совокупность водосборов с природными (гидрологическими, морфометрическими) и антропогенными (распаханность, застроенность) параметрами, и это множество необходимо разделить на некоторое число классов. Второй сюжет со всей очевидностью значительно сложнее первого: один эксперт сочтет, что необходимо выделить четыре класса водосборов, но другой может решить, что необходимо, по меньшей мере, семь классов. "Big Data" снабжают нас множеством данных, но зачастую эти данные заранее не "говорят" нам ничего или почти ничего о том, как может быть проведена классификация в многомерном пространстве факторов.
8.2. Анализ группирования как способ районирования в ArcMAP
Задача районирования, понимаемая как географический вариант более широкой (в общенаучном смысле) задачи классифицирования, распадается на две "подзадачи":
- Определение условий соседства и "граничности" (число соседей и характер контакта) объектов (в ГИС-моделировании - полигонов) принадлежащих к одному классу,
- Определение оптимального числа классов (таксонов), на которое необходимо разбить множество объектов (районов).
На традиционном для географии языке определение условий соседства означает различие между индивидуальным районированием - когда выделяемые районы одного типа соседствуют между собой (т.е., по сути, формируют единый ареал) и типологическим районированием, когда районы одного и того же типа могут располагаться в разных ареалах ("кластерах"). Индивидуальное районирование часто полагают дедуктивным, т.е., начинающимся сверху (top-down): всю область районирования делят на крупные отличающиеся друг от друга части, а затем на все более мелкие различающиеся ареалы, и каждый из них неповторим, индивидуален. Типологическое районирование, напротив индуктивно и начинается снизу (bottom-up): определяется комплекс свойств по которому задается тип и к нему подбираются подходящие, не обязательно расположенные рядом, далее выделяется следующий тип и так далее.
Инструмент Grouping Analysis|Анализ Группирования ArcMAP10.x позволяет задать условия соседства и граничности прозрачным и воспроизводимым образом, что выводит операцию районирования на новый, методически обоснованный уровень. Это обстоятельство важно не только для науки, но (и возможно в большей степени) для практики, поскольку районирование всегда было предметом, по поводу которого "ломались копья" многих научных школ. Классифицирования и районирование (как вариант классификации) были и остаются важным инструментом научного познания. На классификаторы и схемы районирования разного рода опираются все практики природоохранного регулирования, методы ландшафтного планирования и экологической реабилитации природных объектов, процедуры землеустройства, лесоустройства, подходы стратегического и градостроительного планирования.
Уникальность инструмента Grouping Analysis|Анализ Группирования заключается в том, что, придумав для этого способа классифицирования/районирования/кластеризации новое название - "группирование" (за что их неоднократно подвергали критике) - специалисты ESRI украсили его "вишенкой на торте", снабдив дополнительной опцией определения оптимального числа групп. Именно эта особенность привлекает к алгоритму пользователей, решающих самые разнообразные практические задачи.
Следует сразу отметить, что корректность и релевантность определения оптимального числа классов в качестве одного из результатов использования инструмента Grouping Analysis|Анализ Группирования не гарантирована, и в каждом конкретном случае предложенное число групп должно пристально оцениваться экспертом. Мы оставляем за пределами обсуждения отдельный (и почти "философский") вопрос о том, возможно ли вообще решить данную проблему "идеально" безотносительно конкретной задачи. Обособленность или специфичность любого класса определяется степенью дифференцированности привлеченных к анализу признаков-параметров разделения конкретного множества, но и сами эти признаки - каждый в отдельности - могут быть сложно распределенными в собственном пространстве.
Так или иначе, общий алгоритм Grouping Analysis|Анализ Группирования, может быть представлен следующим образом:
- Запускаем инструмент Grouping Analysis ArcMAP10.x для выявления оптимального числа классов, задавая при этом потенциально максимально возможное число- 15;
- Изучаем PDF-Отчет на предмет выявления оптимального числа "групп" (классов, или типов районов);
- Повторно запускаем Grouping Analysis ArcMAP10.x с выявленным оптимальным числом классов, интерпретируем результат;
- Запускаем Cluster Analysis (Shapes) кластеризацию в SAGA GIS для получения альтернативного варианта классификации в виде "кластеров", интерпретируем кластеры и сравниваем с результатом Анализа Группирования;
- Выбираем наиболее адекватный поставленной задаче инвариант дифференциации на группы/кластеры.
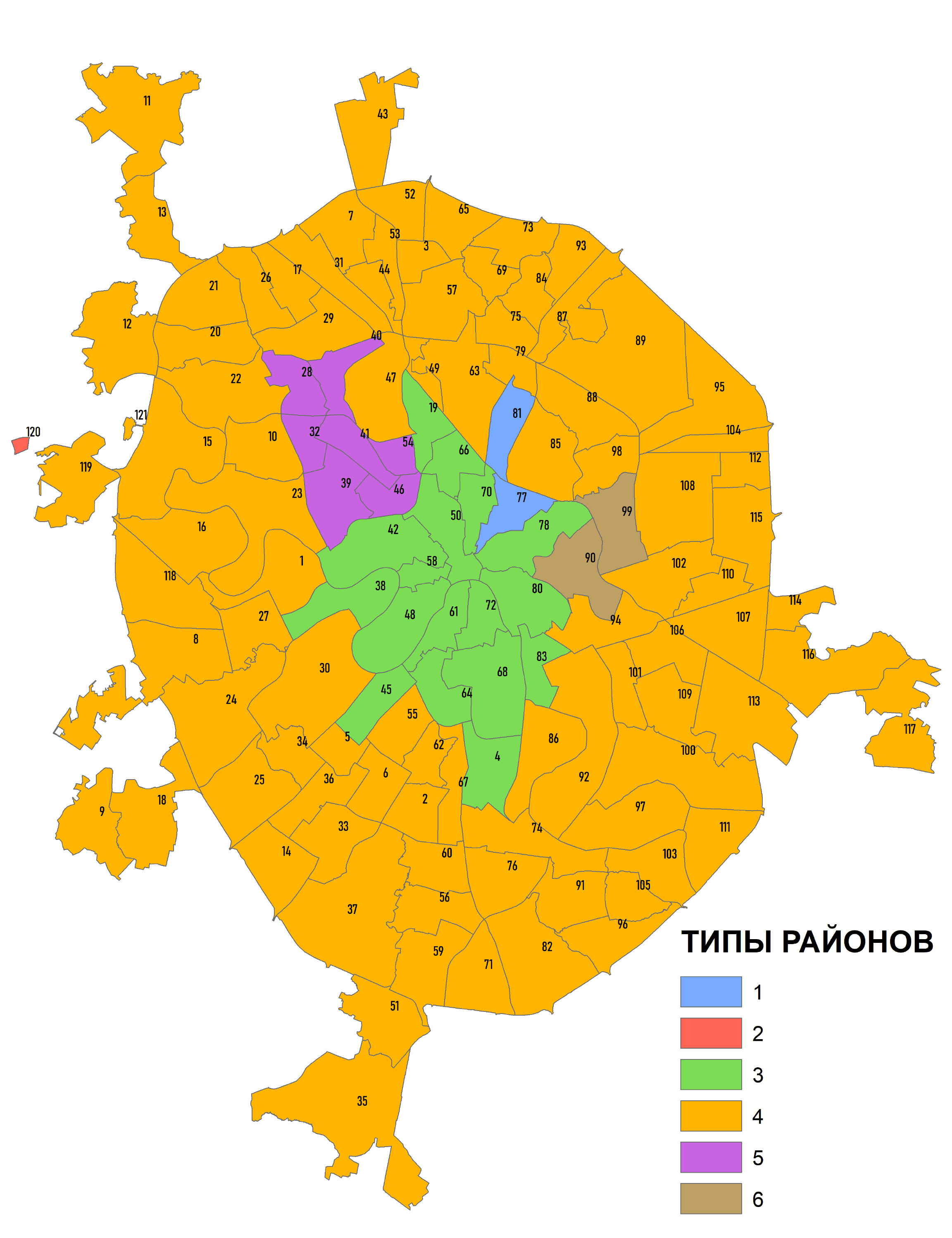
Продемонстрируем возможности классификации инструментом Анализ Группирования на примере шейп-файла районов "Старой" Москвы с извлеченными значениями доли, занимаемой каждой из 9 типов геоморфологических поверхностей. Таким образом, задача классификации - разделить районы Москвы по сочетанию (спектру) типов рельефа.

Рис. 8.4 Скриншот таблицы исходного шейп-файла районов "Старой Москвы"; значения полей: a1 - гляциально-аккумулятивная равнина, a2 - флювиогляциальная равнина, a3 - днища долин мелких водотоков, a4 - нерасчлененный аллювиальный комплекс, a5 - третья надпойменная терраса, a6 - пойма, a7 - вторая надпойменная терраса, a8 - первая надпойменная терраса, a9 - акватория Москвы-реки
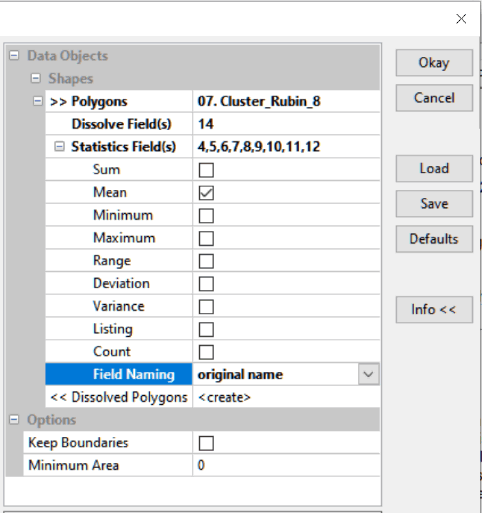
Инструмент Grouping Analysis пакета ArcMAP10.x находится в наборе Mapping Clusters группы Spatial Statistic Tools; использование предполагает тщательную установку всех необходимых опций - в противном случае результат будет слабо интерпретируем.
Input Features: Old_Moscow_reg
Unic ID Field: FID
Output Feature Class: ... Mscw_Reg_Group_15_exprmnt
Number of Group: 15 (*в первом запуске используем максимально возможное число групп для определения "оптимального" в пределах от 2 до 15)
Analysis Fields: a1, a2, a3, ... a9 (*перечисляем все поля учитываемых переменных исходной таблицы)
Spatial Constrains: NO_SPATIAL_CONSTRAINT
Distance Method: MANHATTAN
Initialization Method: Find Seeds Locations
Evaluate Optimal Number of Groups: check
Output Report File: ... 15_Group_exprmnt.pdf
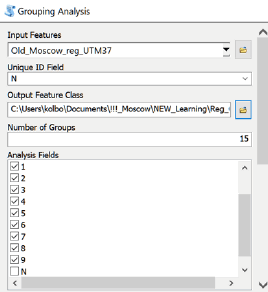
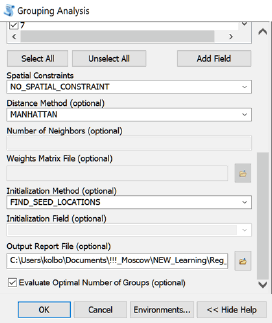
Рис. 8.5 Диалоговое окно инструмента Grouping Analysis ArcGIS10.x
К специфическим (т.е., определяющим параметры работы инструмента) опциям относится Number of Group|Число Групп. При первом "прогоне" инструмента для определения оптимального числа будущих групп-классов имеет смысл задать максимум (15) - с большими значениями программа не работает, с другой стороны, непросто представить себе множество, которое мы способны разделить на большее количество классов, и, что важнее, затем подвергнуть их содержательной интерпретации.
Следующее поле - Analysis Field - предполагает указание полей, которые будут использоваться для классификации, в данном случае это поле исходного шейп-файла со значениями доли (в %) занимаемой каждым типом поверхности от площади отдельного района АТД Старой Москвы. Количество полей - т.е., число признаков, привлекаемых для классификации, сказывается на продолжительности работы инструмента. Характер данных полей влияет на результат классифицирования, опять-таки, в разбираемом (простейшем) кейсе все поля качественно однородны и относятся к одному признаку (тип рельефа) и распределены по единой (процентной) шкале. Когда привлекаются разные признаки, существующие в разных шкалах - результат может быть мало предсказуемым и в значительной степени зависимым от их подбора и комбинаторики данных.
В нижней части вкладки диалогового окна Grouping Analysis размещены остальные критические опции. Позиция Spatial Constrains|Пространственные Ограничения чрезвычайно важна, поскольку она определяет характер будущей классификации. Здесь мы сталкиваемся с традиционным теоретическим дискурсом географии и спорами о том, чем "типологическое"" районирование отличается от "индивидуального" [Гвоздецкий, 1979]. С позиций ГИС- моделирования процедуры "индивидуального физико-географического районирования" и "типологического районирования" могут быть осуществлены одним и тем же инструментом анализа - кластерным анализом - и различаются (1) определением условий соседства полигонов районов, (2) алгоритмом описания граничности и (3) способом измерения расстояний.
Иными словами, в кейсах индивидуального районирования мы как бы "идем сверху", в поисках различий разделяем все множество сначала на все более дробные (две, потом три-четыре и так далее) части, и при таком дедуктивном способе полигоны классов в выделяемых частях всегда будут граничить между собой и формировать единый "индивидуальный" (отличающийся от всех других) ареал. Опция, дифференцирующая индивидуальное районирование - характер граничности, поскольку результат будет различаться в зависимости от того как задаются условия соседства: "только углы полигонов", "только стороны полигонов", "углы и стороны полигонов" и т.д. (см. ниже). Заметим, что "угловатость" полигонов, это свойство, которое может быть присуще искусственным объектам (например - городским районам и кварталам, контурам сельскохозяйственных угодий), но которое сложно применять к природным объектам (речным бассейным, ландшафтам, лесным выделам и проч.). Поэтому на эксперта ложится дополнительная задача апробации разных опций соседства и граничности в сочетании с разными способами измерения расстояний между полигонами, а также интерпретации и сравнения результатов.
При типологическом районировании мы поступаем противоположным "индуктивным" образом: ищем сходные черты у отдельных полигонов и объединяем их, двигаясь снизу, при этом мы полагаем, что районы, принадлежащие к одному типу, не обязательно должны соседствовать между собой (т.е., их полигоны могут иметь, а могут и не иметь общую границу). Все остальные опции соседства и граничности здесь также должны апробироваться и оцениваться экспертно исходя из характера данных и ожидаемого результата.
Выбор траектории моделирования как раз и задается опцией Spatial Constrains, предлагающей целый ряд вариантов учета соседства, или взаимного расположения полигонов, а именно:
- CONTIGUITY_EDGES_ONLY - класс формируется смежными полигонами, т.е., только полигоны, имеющие общее ребро, могут быть частью одного класса (жесткое условие смежности подходящее для индивидуального районирования);
- CONTIGUITY_EDGES_CORNERS — класс формируется смежными полигонами, но при этом полигонам достаточно иметь общее ребро и/или общую вершину (смягченное условие смежности - полигоны по сути могут касаться друг друга только в одной "угловой" точке);
- DELAUNAY_TRIANGULATION - естественные соседские отношения внутри класса основаны на триангуляции Делоне, полигоны в одном классе должны иметь хотя бы одного общего соседа, граничащего с другим полигоном этого же класса - (другой вариант смягченного условия соседства);
- K_NEAREST_NEIGHBORS — условие соседства, основанное на параметре k-ближайшего, целочисленное значение которого (т.е., сколько смежных полигонов 2,3 ... 8 должен иметь каждый конкретный полигон класса) указывается пользователем (третий, регулируемый вариант смягченного соседства);
- GET_SPATIAL_WEIGHTS_FROM_FILE - пространственные отношения определяются предварительно формируемым (инструмент Generate Spatial Weights) файлом Пространственных Весов (четвертый, регулируемый вариант смягченного соседства);
- NO_SPATIAL_CONSTRAINT— объекты не обязательно должны находиться рядом друг с другом в пространстве чтобы быть частью одной группы (класса) - вариант, при котором полигон, принадлежащий к одному классу, может быть окружен полигонами других классов и не иметь соседа, принадлежащего к этому же классу.
Таким образом для типологического районирования подходит только последний шестой вариант, не задающий условий обязательного соседства. Заметим, что выражение NO_SPATIAL_CONSTRAINT при этом не запрещает соседства, т.е., полигоны относящиеся к одному классу могут как формировать, так и не формировать ареалы из смежных полигонов.
При выборе любого из вариантов смежности следует определить Distance Method|Метод вычисления Дистанции между объектами; здесь возможны два варианта: EUCLIDEAN — оценивается кратчайшее расстояние ("полет вороны"), MANHATTAN - оценивается как разность дистанций по двум осям координат X и Y, имитирующая путь таксомотора по улицам между городскими кварталами - отсюда экзотичное название.
Наконец, последняя опция - указание на оценку оптимального числа групп (классов) - Evaluate Optimal Number of Groups, в этой позиции при первом прогоне алгоритма указывается максимально возможное число групп (15), при последующих - рекомендованное и/или экспертное.
После первого прогона инструмента Grouping Analysis на выходе новый шейп-файл с 15 ("заказанными") классами, но нас в данном случае больше интересует PDF-отчет, который содержит серии таблиц, объясняющие как распределен конкретный признак (скажем доля пойм или террас) при разном числе групп (т.е., типов районов), начиная с 2 групп.
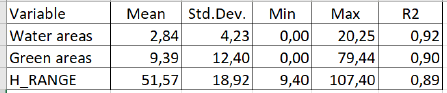
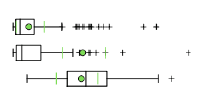
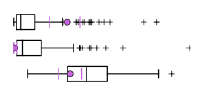
Верхняя схема отчета демонстрирует принцип построения статистического "ящика с усами": в центре ящика – черная линия медианы, значение, выше и ниже которого располагается ровно половина всех значений выборки. Левый и правый края ящика маркируют значение нижней и верхней квартили (четверти из общего числа значений выборки). Наконец левый и правый "ус" показывают соответственно самое низкое и самое высокое значение. Цветная точка-окружность – маркирует среднее арифметическое значение. Все знаки +, не попадающие в верхний или нижний ящичек, представляют собой выбросы в данных.
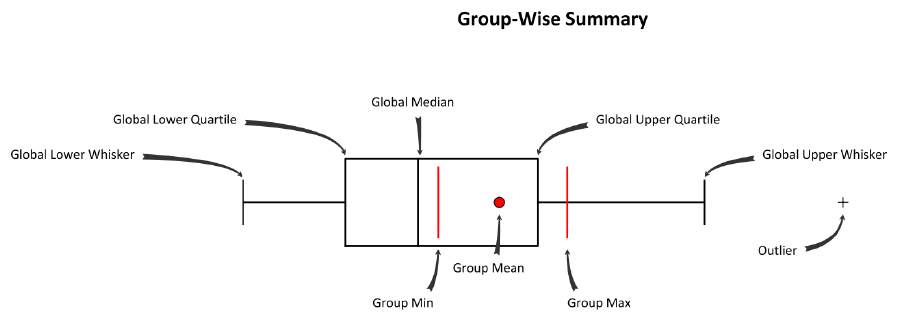
Рис. 8.6 Ящичковая диаграмма, демонстрирующая распределение статистик
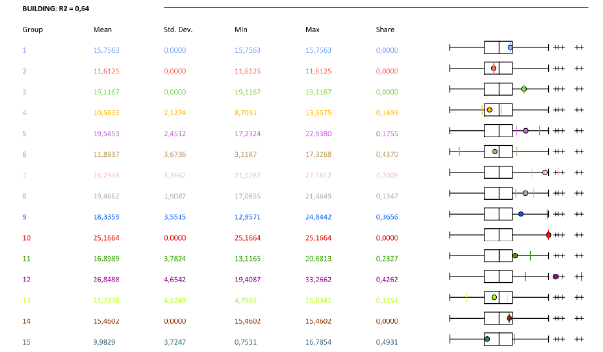
Для каждого числа классов (групп), апробированных утилитой, в файле PDF-Отчета построены собственные таблицы значений каждой переменной (Mean, Std.Dev, Min, Max, Share) и представлены ящичковые диаграммы. Последовательно просматривая данные таблиц и диаграммы, можно судить о том, насколько удачно распределяется конкретная переменная при данном числе групп: в "хороших" вариантах круглый пунсон Mean|Средней должен оказаться внутри "ящика" и располагаться как можно ближе к черте медианы.
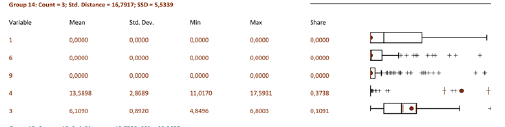
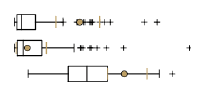
Рис. 8.7 Таблица статистик и графики для варианта 14 выходных классов в файле PDF-Отчета
Просматривая цветные серии таблиц, мы можем видеть насколько сильно "разлетаются" значения при заданном числе групп в процессе перебора программой вариантов от 2 до 15 групп.
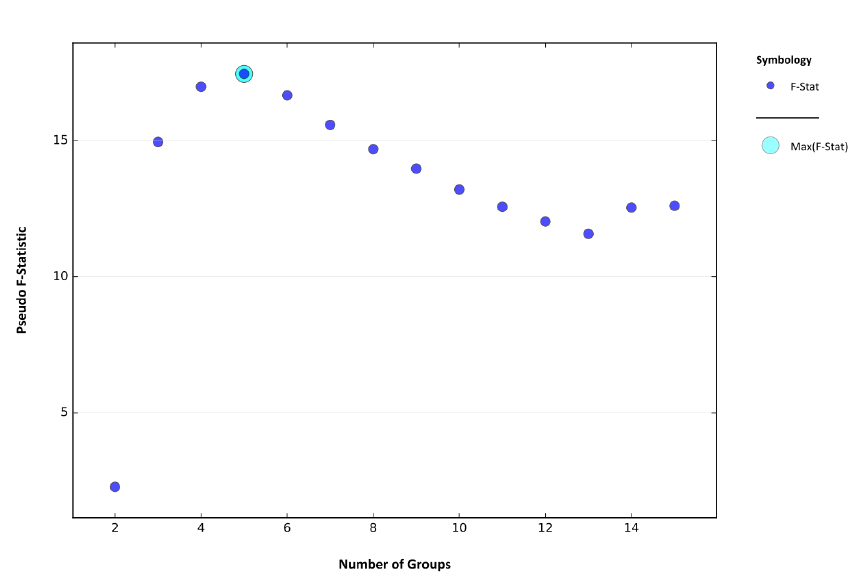
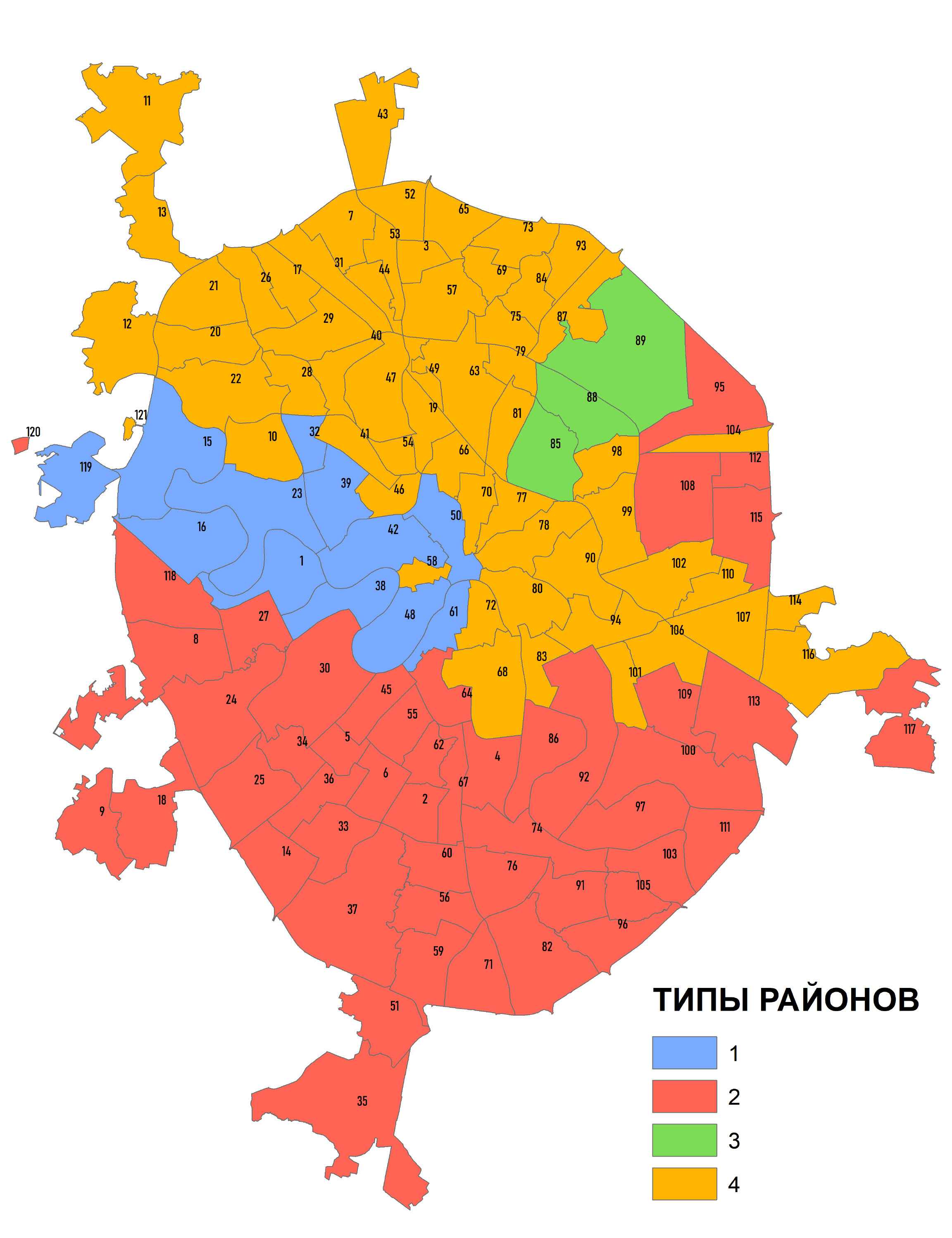
Диаграмма Pseudo F-statistic на предпоследней странице PDF-Отчета показывает Оптимальное число Групп размещением голубого пунсона на осях диапазона значений Minimum-Maximum, при этом Mean|Среднее и Median|Медианного значения отражены соответственно синим кружочком и красным ромбом. Иногда это разочаровывающе малое число групп-классов: как в данном случае всего 3 группы районов (Рис.8.8).
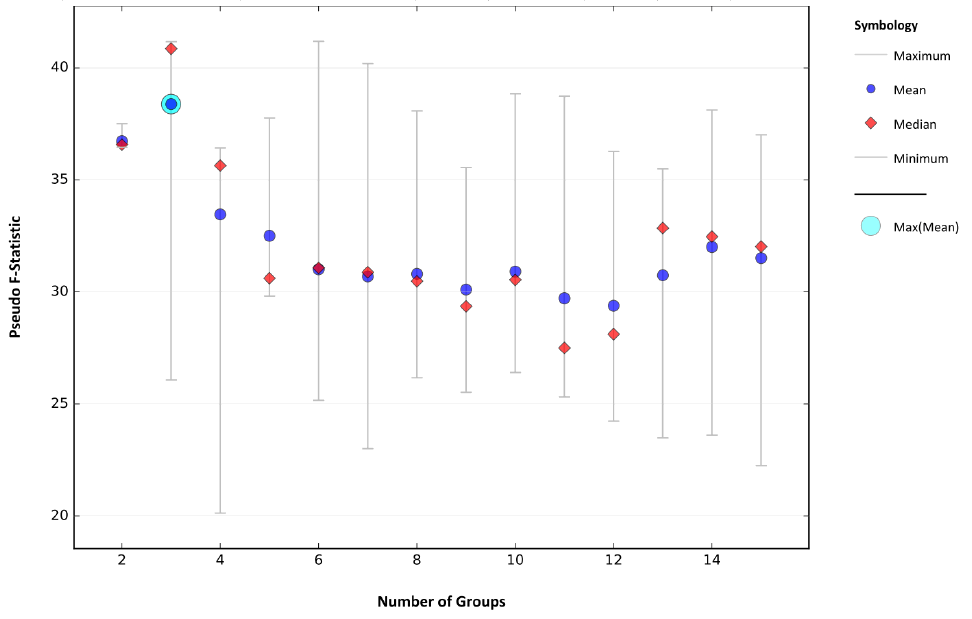
Рис.8.8 График Pseudo F-statistic в файле PDF-отчета
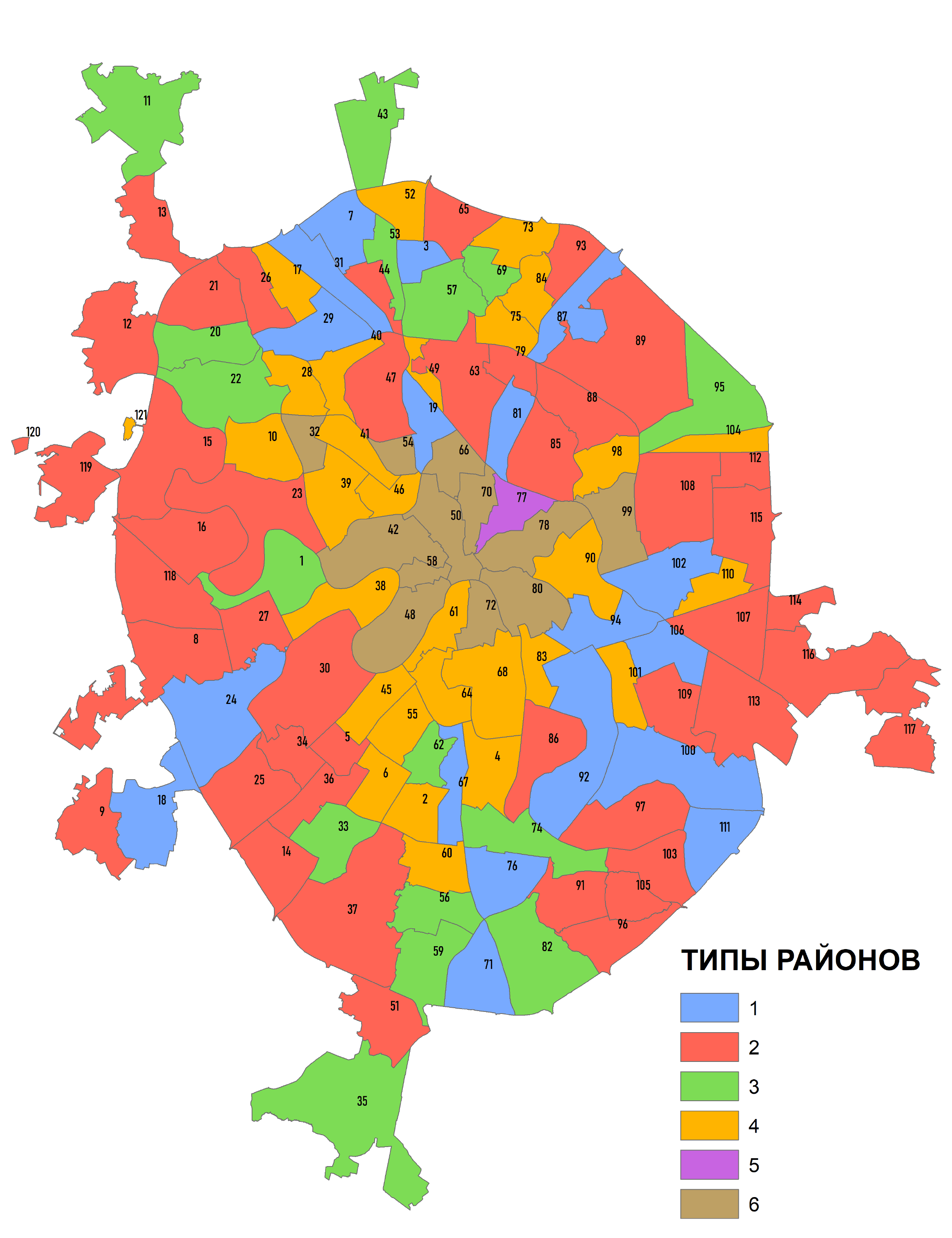
В подобной ситуации расхождения результатов группирования с ожиданиями (и здравым смыслом) необходимо прибегнуть к экспертной оценке, т.е., подключить исходный слой геоморфологических поверхностей и наложить сверху прозрачный слой районов Москвы. Внимательно анализируя (Рис. 8.2) данные несложно прийти к заключению, что классов районов по "спектру" типов рельефа все же больше чем три. Можно выделить районы следующих типов:
1) с преобладанием акватории и поймы,2) с преобладанием акватории, поймы и первой надпойменной террасы,
3) с абсолютным доминированием надпойменной террасы,
4) с преобладанием первой и второй надпойменной террас,
5) с абсолютным доминированием третьей надпойменной террасой,
6) с преобладанием третьей террасы и флювиогляциальной равнины,
7) с преобладанием гляциально-аккумулятивной моренной возвышенности,
8) с сочетанием флювиогляциальной и гляциально-аккумулятивной поверхностей.
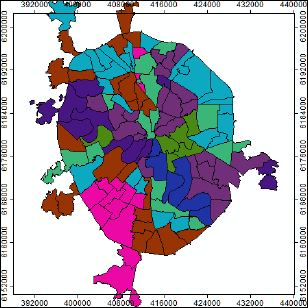
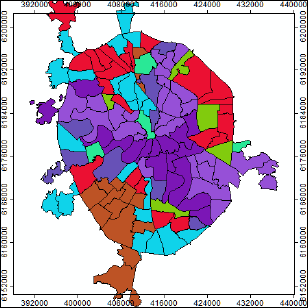
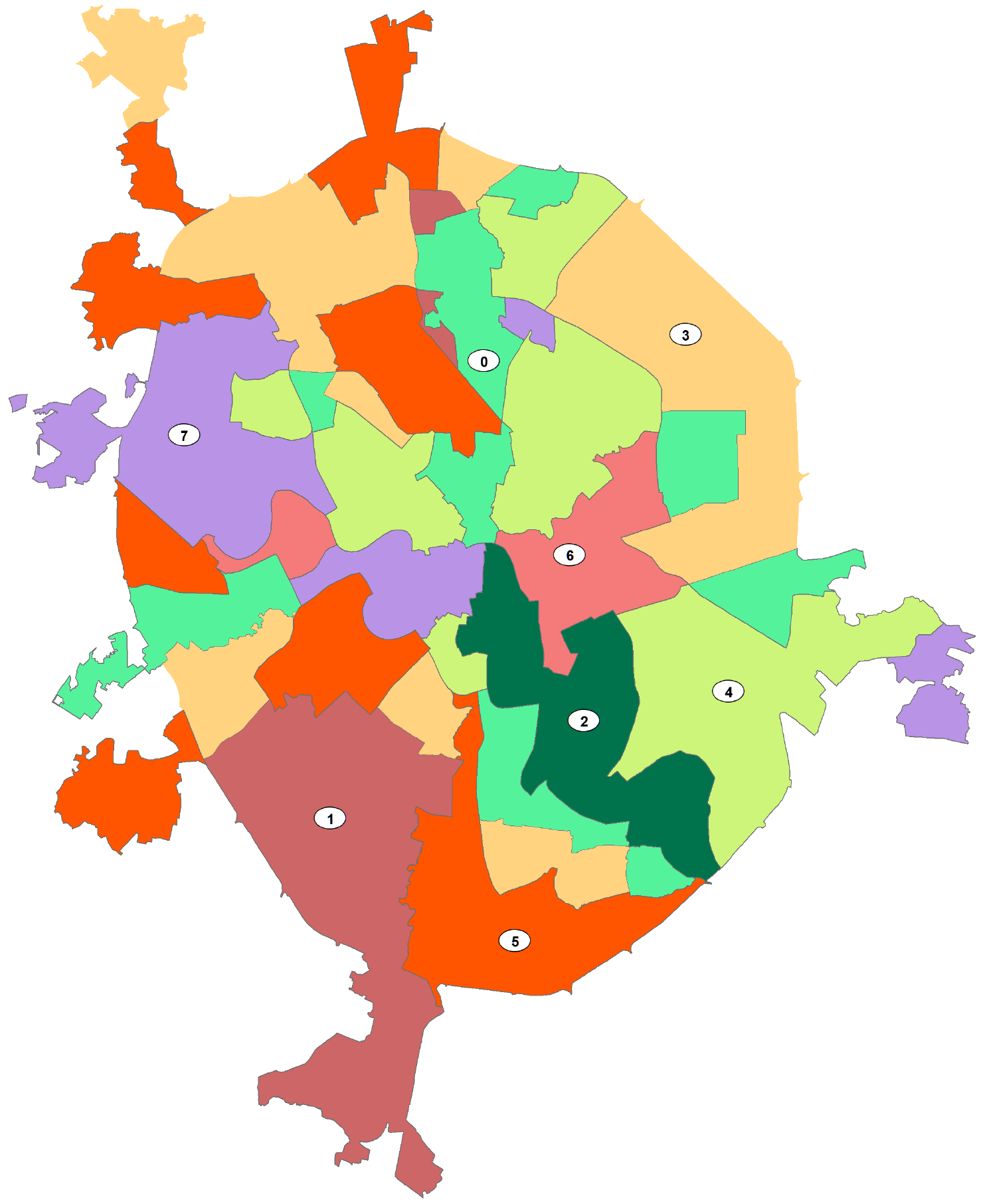
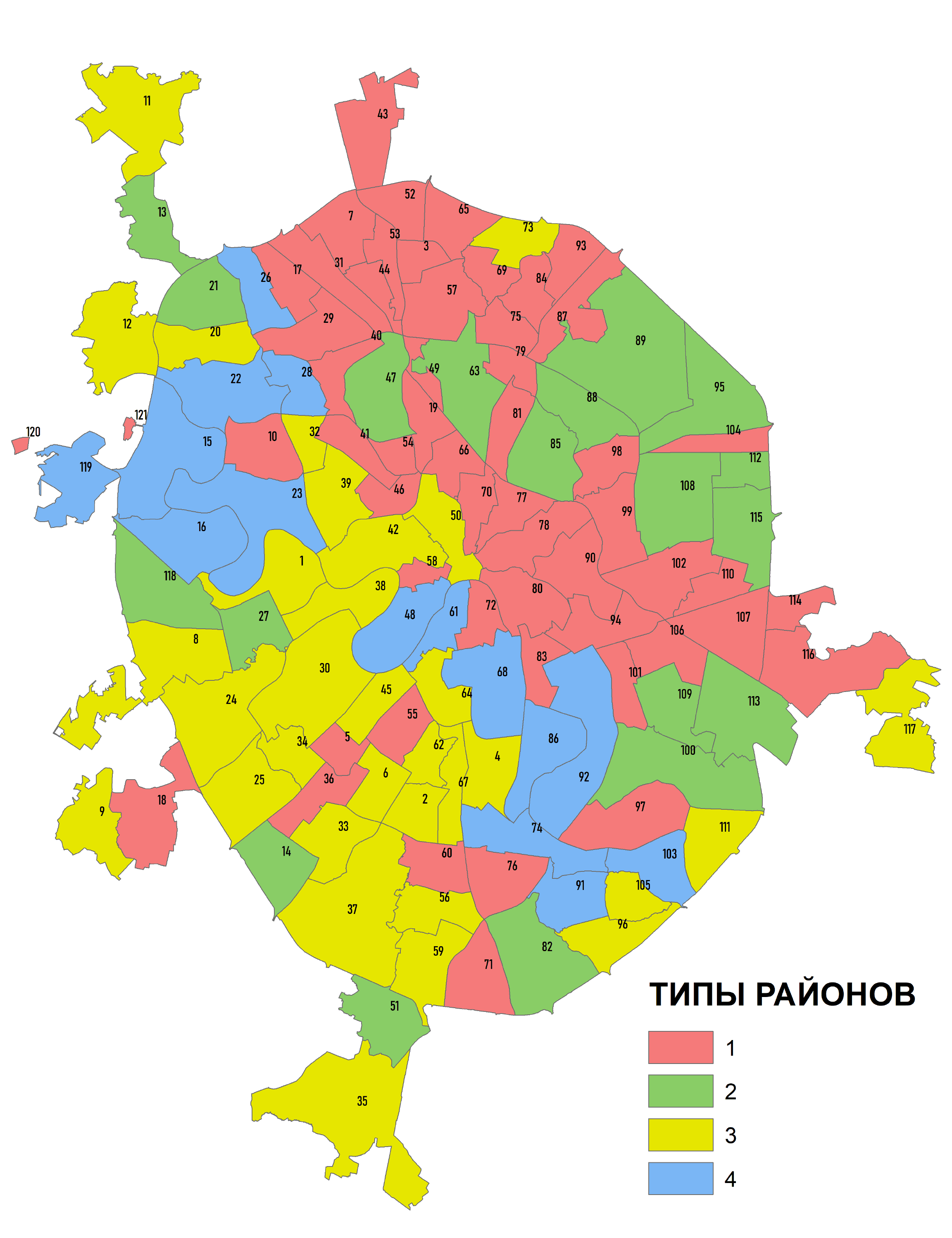
Экспертный выбор оптимального числа классов (8) не так уж и плох: обратим внимание на обстоятельство близкого расположения на графике Pseudo F-statistic при числе групп от 6 - 8 синего пунсона Среднее и красного ромбика Медианное. Попытаемся реализовать различные варианты группирования, запустив инструмент с одинаковым числом ожидаемых классов (8) дважды: сначала без пространственный ограничений NO_SPATIAL_CONSTRAINT, затем – с ограничениями CONTIGUITY_EDGES_ONLY - условие, при котором класс формируется смежными полигонами, имеющими общее ребро.
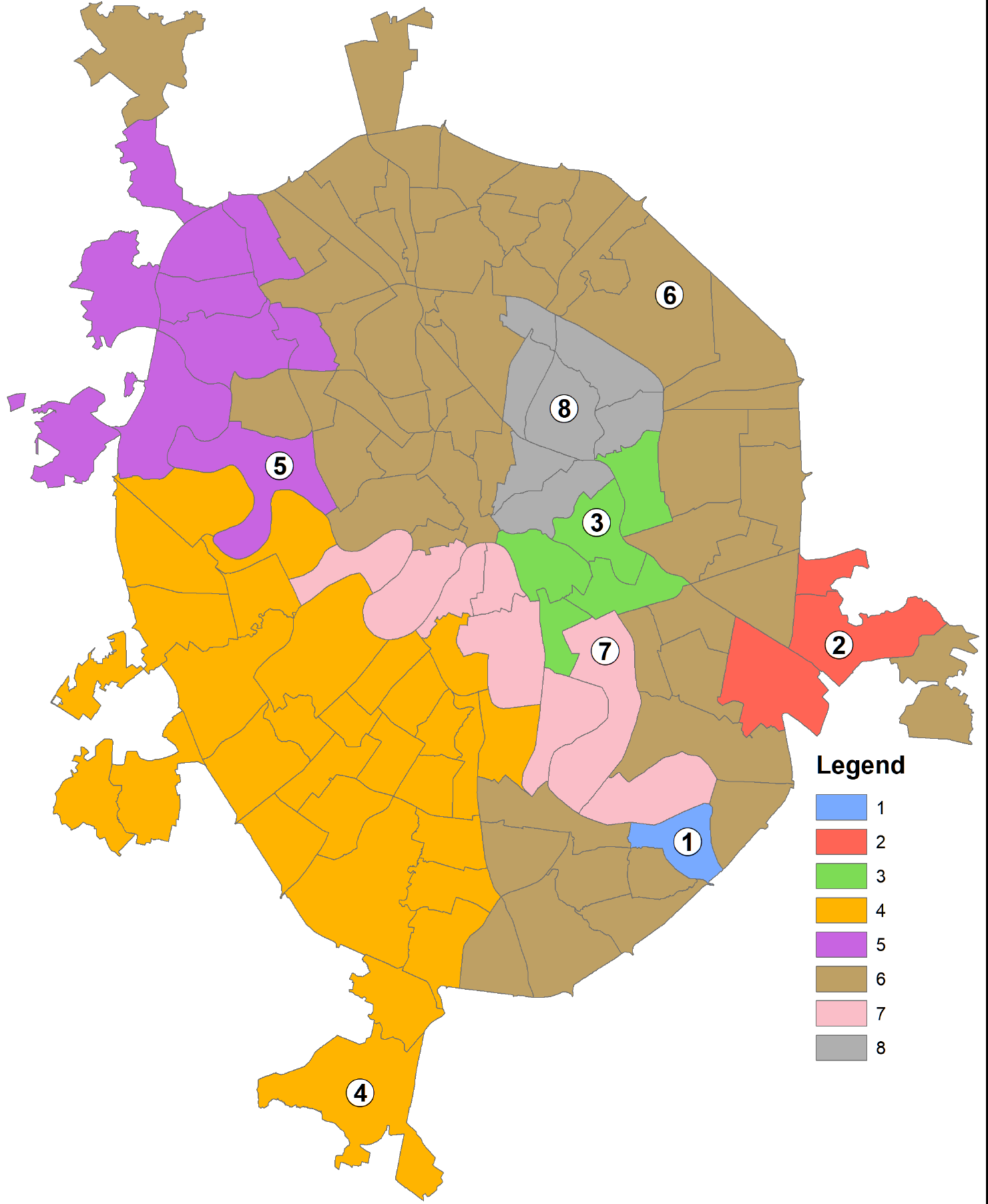
Рис. 8.9 a) результаты Grouping Analysis для восьми классов без пространственный ограничений, b) результаты Grouping Analysis для восьми классов с ограничениями по соседству с условием общего ребра смежных полигонов
Как и ожидалось, введение условий соседства для группируемых районов переводит всю процедуру с языка типологического районирования (районы, принадлежащие к одному из восьми типов, могут встречаться в разных частях города) на язык индивидуального районирования (когда все районы-полигоны данного типа граничат друг с другом и составляют один общий ареал). Таковы результаты с формально-логической точки зрения. Однако содержательно (с экспертных позиций) они далеко не равнозначны: вариант типологической классификации (Рис. 8.9a) в значительно большей степени соответствует нашим представлениям о доминировании и сочетании тех или иных форм рельефа в пределах районов АТД Москвы. Введенное условие соседства привело к неоправданно широкому обобщению, сформировались классы (например, 6 и 4), которые объединили совсем непохожие районы с преобладанием в одним случаях - аккумулятивных гляциальных равнин, в других - террасового комплекса (Рис. 8.9b).
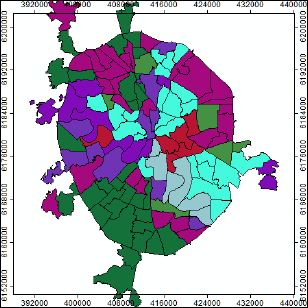
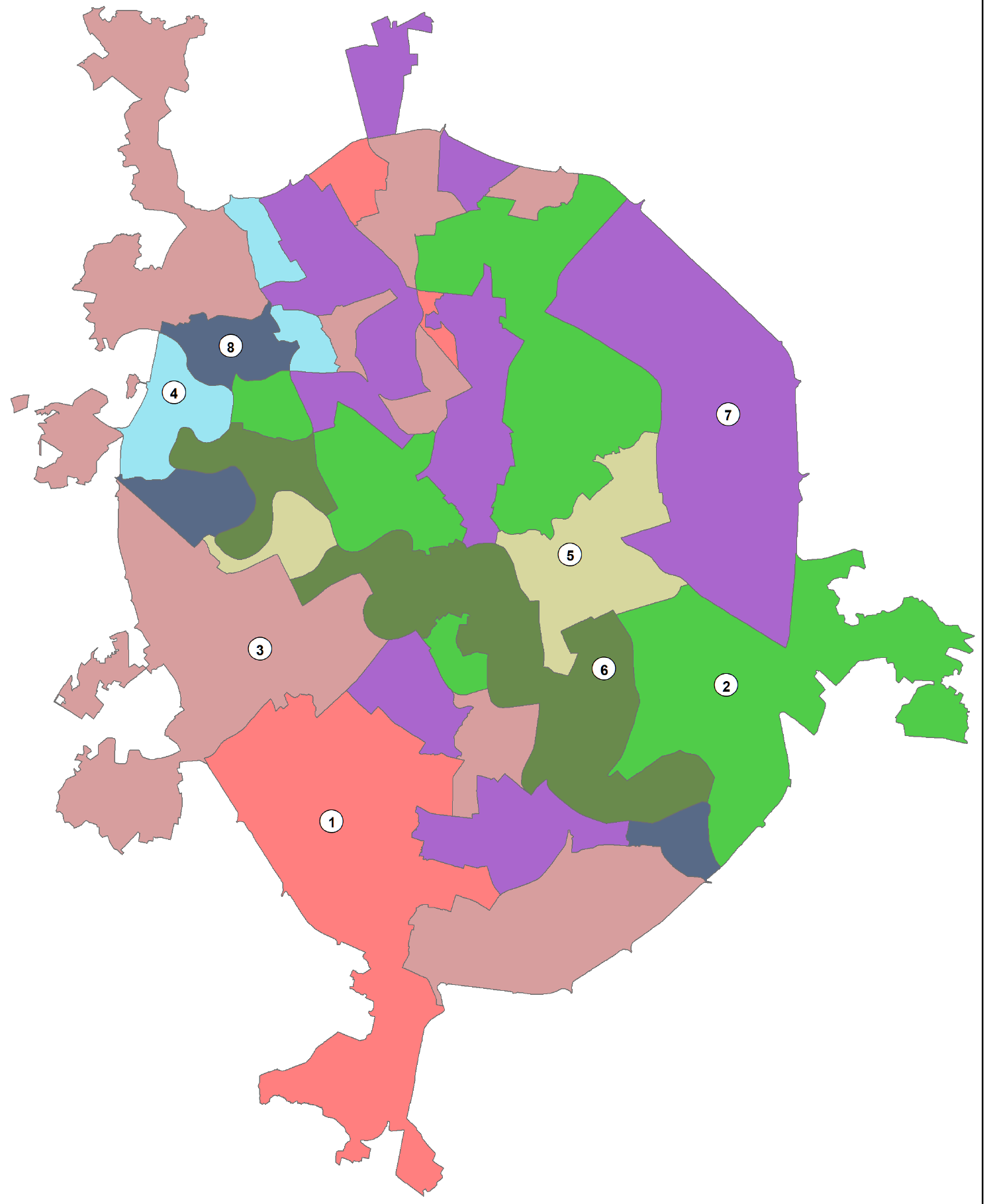
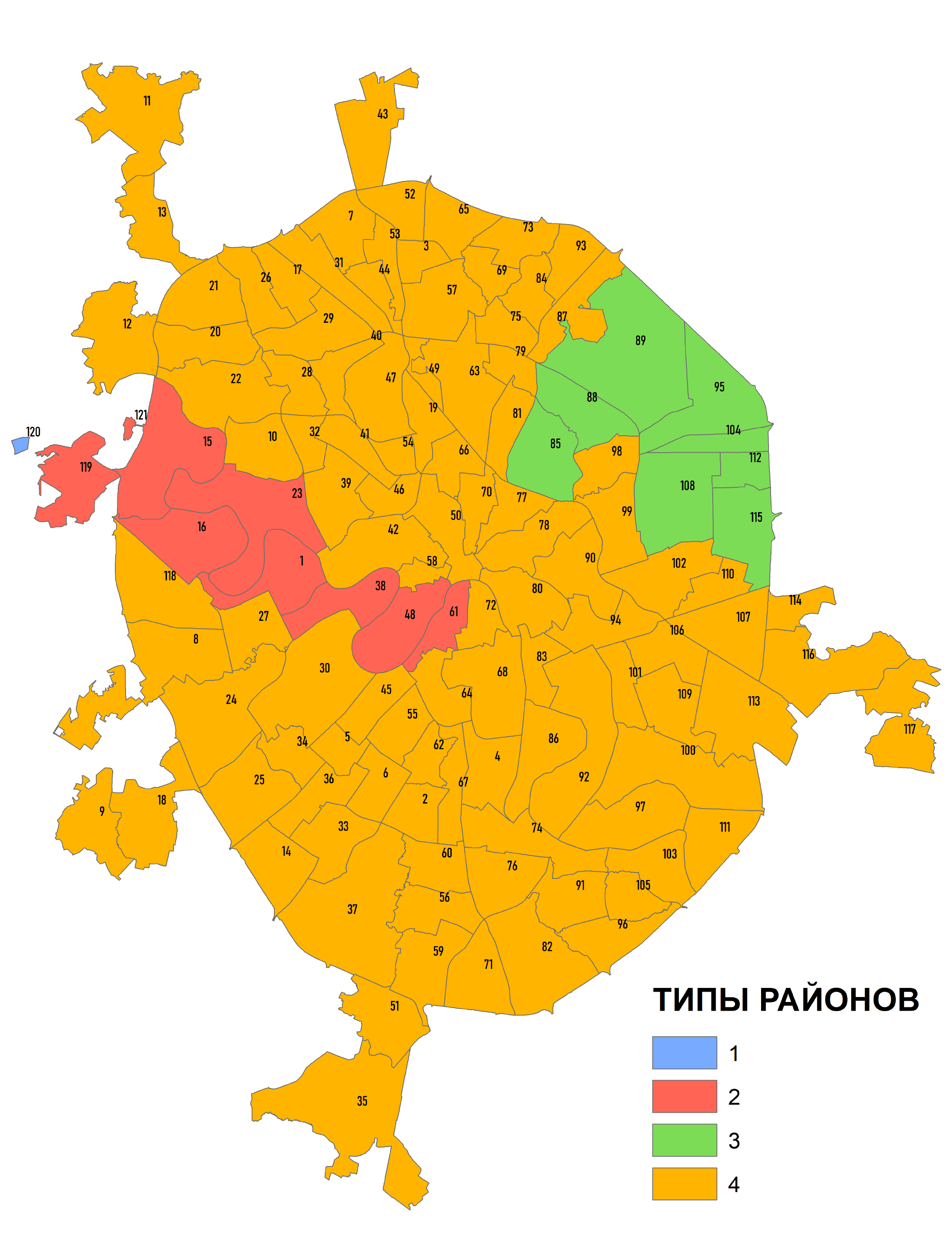
Оптимизировать результат для индивидуального районирования возможно увеличивая число классов и меняя условия соседства (например введя условие K_NEAREST_NEIGHBORS соседства), но в этом случае следует быть готовым и к более детальной содержательной интерпретации итоговых классов (Рис. 8.10).
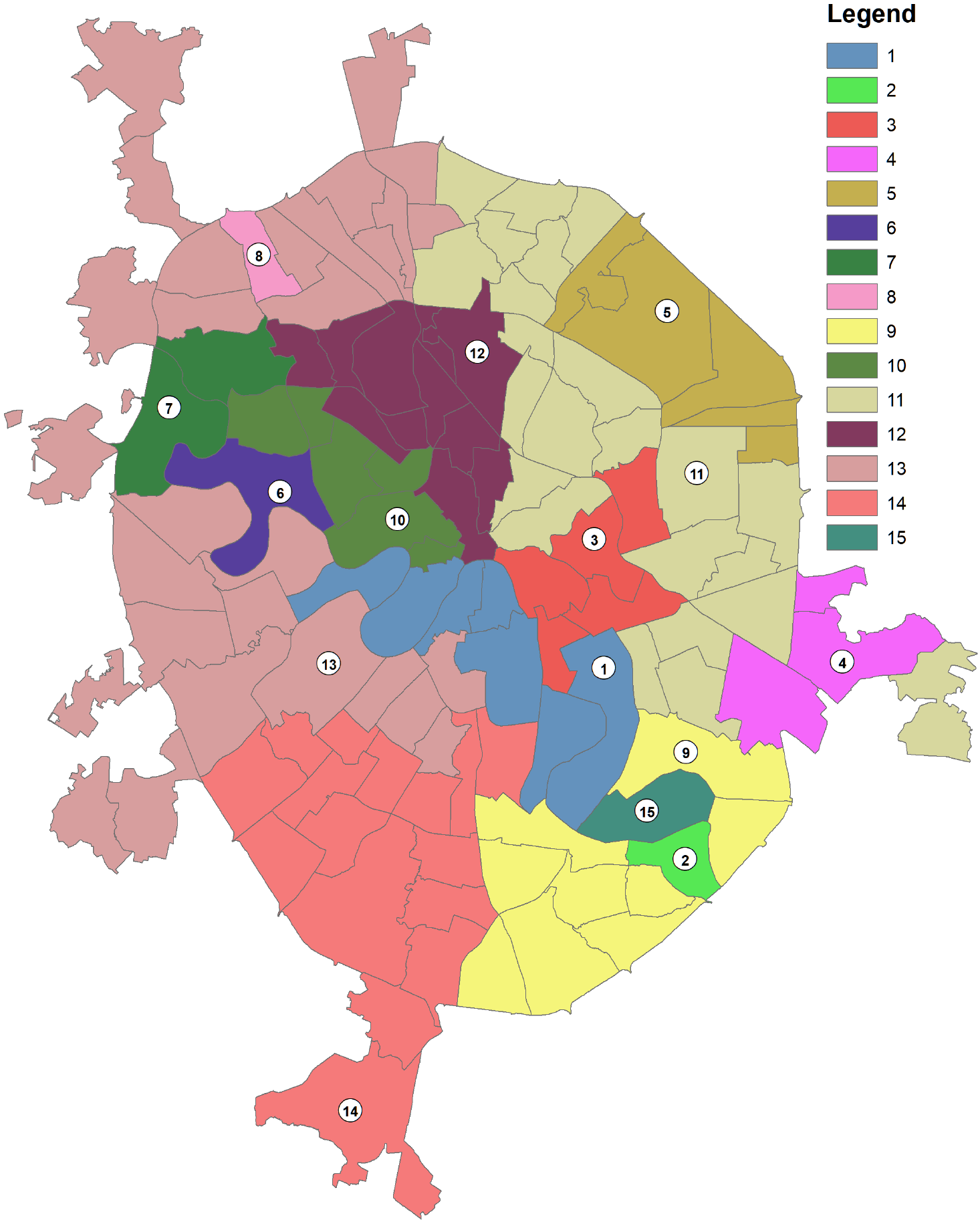
Рис. 8.10 Результаты Grouping Analysis для 15 классов с пространственными ограничениями и K_NEAREST_NEIGHBORS условием смежности (соседства) отдельных районов значительно лучше отражают реальные сочетания типов рельефа в районах "Старой" Москвы
Таким образом, успех и корректность классификации и районирования средствами ГИС-анализа тесно связаны с внимательным отношением к деталям, т.е., опциям построения модели: "дьявол кроется в мелочах". Важно помнить три несложных правила:
- При классифицировании (районировании) без пространственных ограничений результат будет варьировать в зависимости от метода оценки дистанции Distance Method.
- В случае включения опции Spatial Constraints результат может изменяться (или не изменяться!) при выборе разных условий смежности-соседства.
- Группирование радикально трансформируется в зависимости от числа конечных классов - в общем случае меньшее число классов формирует более обширные ареалы объединенных полигонов, принадлежащих к одному типу, и наоборот, большее число классов создает "островные" кластеры из двух-трех-четырех полигонов, при этом фрагментированность общей мозаики районов всегда будет возрастать с увеличением числа классов.
Резюме: если инструмент Grouping Analysis используется для исследовательских целей, то целесообразно попробовать запускать его с разными опциями. Об этом говорится и в соответствующем разделе (справки АркГИС), которую всегда полезно изучить до запуска алгоритма.
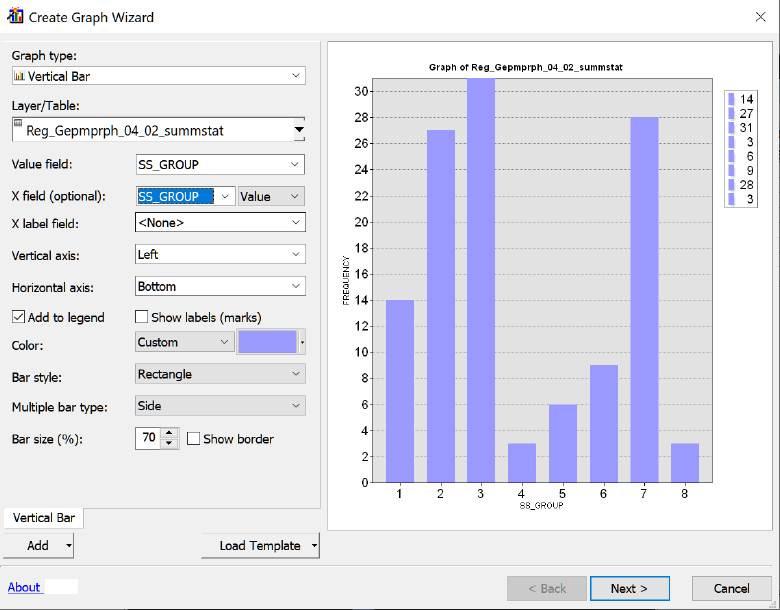
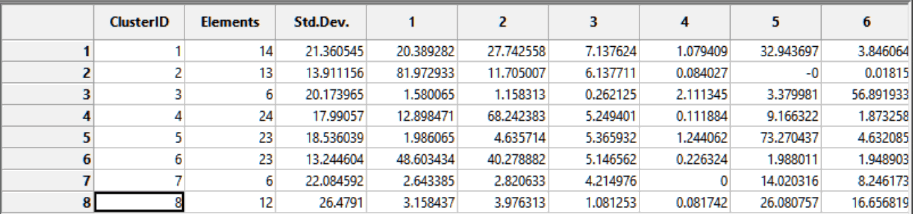
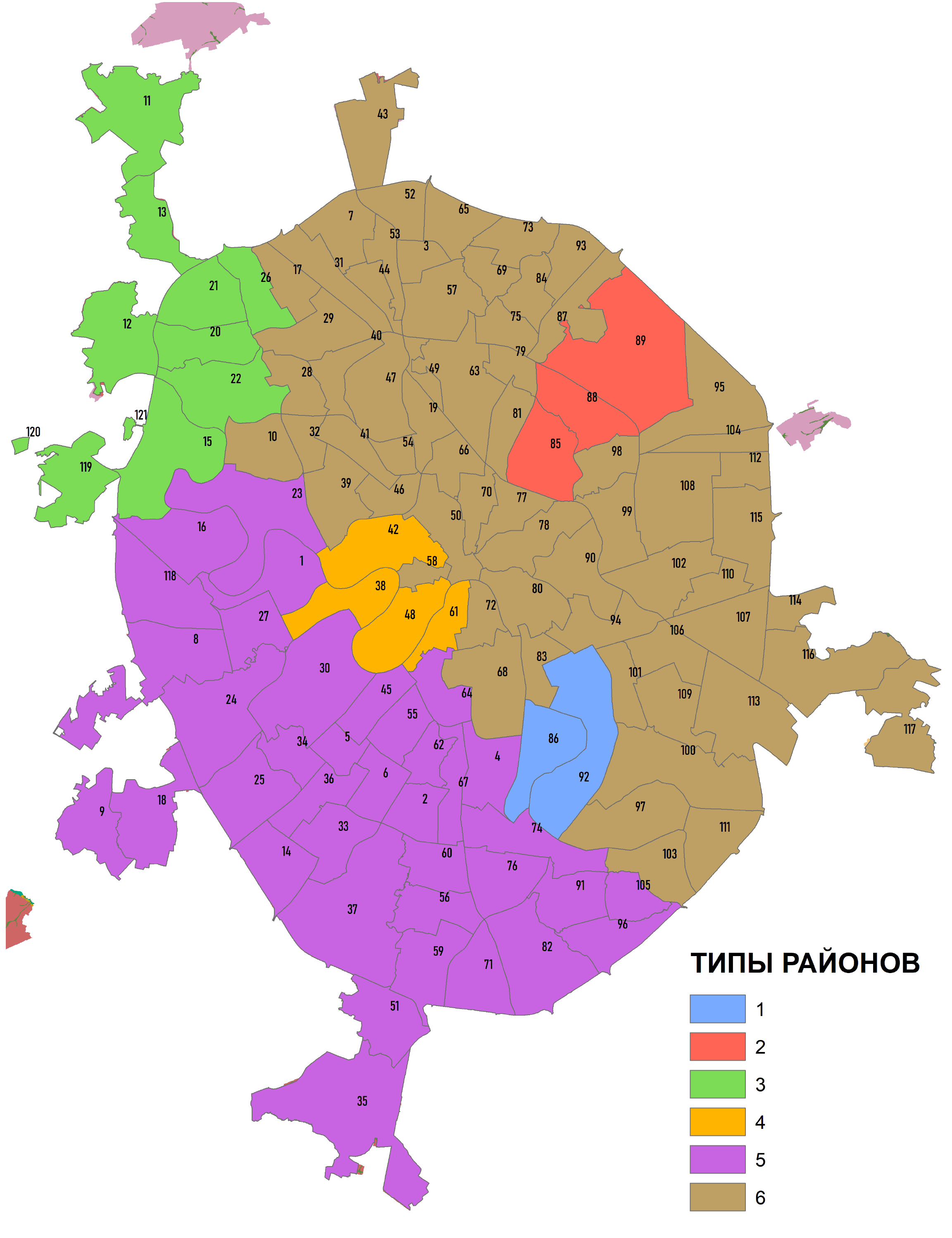
Интерпретация результатов Анализа Группирования связана с дополнительной необходимостью изучения таблицы выходного шейп-файла "групп" Reg_Old_Moscow (Рис. 8.11), где номер группы указан в поле SS_Group.
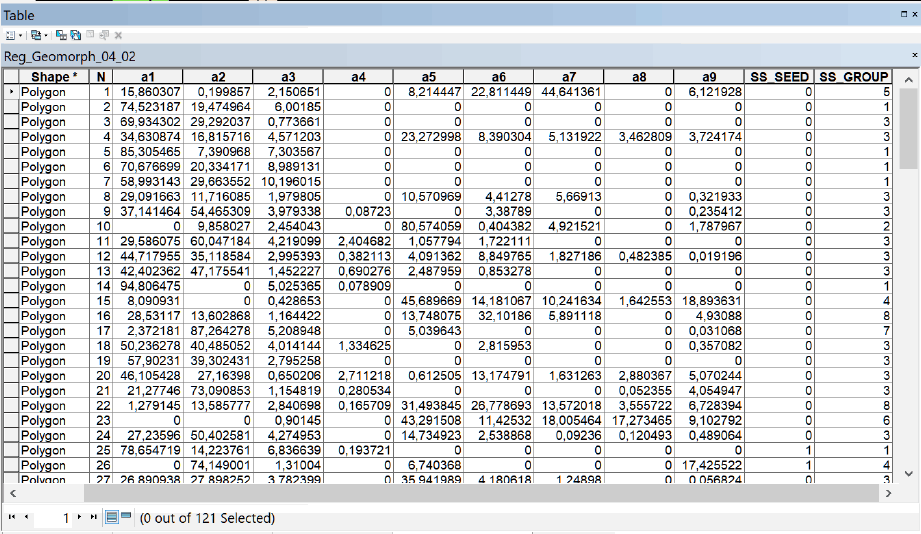
Рис. 8.11 Таблица шейп-файла групп - значения классов в поле SS_Group.
Для обобщения параметров и получения представлений о специфике групп можно прибегнуть к одному из трех способов:
- использовать инструмент Summary Statistics набора Statistics группы Analysis Tools;
- использовать инструмент Dissolve|Слияние - по признаку SS_Group;
- перебросить таблицу шейпа в Excel (Table to Excel) и воспользоваться опцией Cводная Таблица.
Интерфейс утилиты Summary Statistics|Суммарная Статистика несложен: перечисляем поля расчета средних (в нашем случае это средняя площадь ареалов типов рельефа) и указываем номер группы (кластера) поля SS GROUP – в качестве Case field.
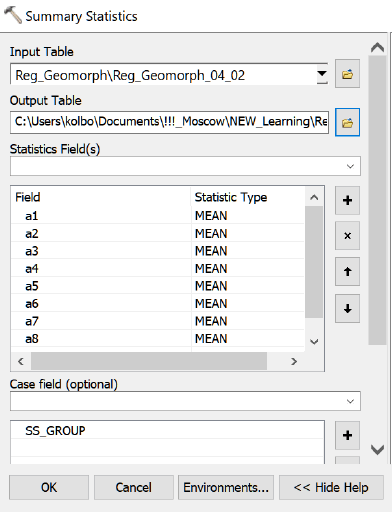
Рис. 8.12 Интерфейс утилиты Summary Statistics
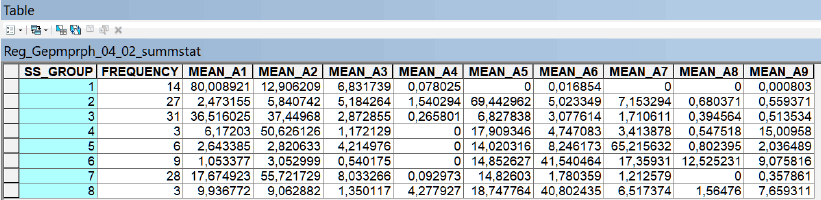
В выходной таблице Summary Statistics в строке номера каждой группы мы увидим параметр Frequency, указывающий сколько административных районов попало в данный тип и далее, по столбцам – среднюю (для типа) долю всех мезоформ рельефа. Таблица позволят нам интерпретировать типы кластеров (если вспомнить значения переменных в исходном растре геоморфологических поверхностей). Так очевидно, что тип 1 - отличается господством гляциально-аккумулятивных равнин (моренных холмов), а тип 6 - это пойма в сочетании с террасами…

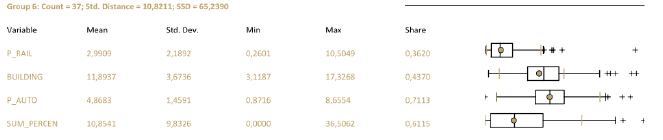

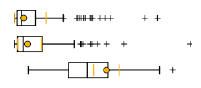

{kind=link}
{kind=link}