III. ГЕОМОРФОМЕТРИЯ И СОВРЕМЕННЫЕ ПОДХОДЫ К ЛАНДШАФТНОМУ СИНТЕЗУ
9. ГЕОГРАФИЧЕСКАЯ РЕАЛЬНОСТЬ: О СЛОЖНОСТЯХ ГИС-МОДЕЛИРОВАНИЯ
9.1. Место географических объектов в мире моделей
9. ГЕОГРАФИЧЕСКАЯ РЕАЛЬНОСТЬ: О СЛОЖНОСТЯХ ГИС-МОДЕЛИРОВАНИЯ
9.1. Место географических объектов в мире моделей
Одна из интереснейших статей, посвященных особенностям научного познания вообще, и географического - в частности, имеет весьма интригующее название "Do Mountains Exist?", что может быть переведено как "Действительно ли горы существуют?" [Smith, David, 2003]. Авторы, разумеется, не сомневаются в реальности гор, но задаются непростым (и существенным для моделирования) вопросом: может ли быть указан некий исчерпывающий набор условий, позволяющий однозначно отнести те или иные формы рельефа Земли к "горам"?
Поиск ответа на этот вопрос заставляет обратиться к когнитологическим основам научной методологии и более пристально присмотреться к обычным географическим объектам (формам рельефа, рекам и озерам, ландшафтам, городам и т.д.) как к предметам моделирования.
С позиций когнитологии все объекты, которые мы пытаемся моделировать, делятся на две большие категории. Первую можно условно назвать "настоящие" вещи и организмы, которые имеют в наших глазах понятные очертания и "твердые" границы, отделяющие их от окружающей среды. Психолог Дж. Гибсон, разработавший проект так называемой экологической психологии [Gibson, 2015], называл такие вещи обособленными объектами ; к ним без сомнения каждый отнесет такие повседневные объекты как "кошка", "дерево" или "Луна на небе" (если верить, что Луна - это твердое небесное тело).
Ко второй категории относятся объекты, которые можно называть продуктами осмысления. Так "горы" не существуют в виде "обособленных" предметов: в их подножье нет однозначно воспринимаемых границ, наконец, их сложно представить "отдельностями", перемещаемыми в пространстве. Как следствие мы не можем легко решить задачи дефиниции и классификации, т.е., отделить объект "гора" от прочих положительных форм рельефа и разделить множество "горы" на классы (например, "высокие горы", "низкие горы" и т.д.).
Для объектов-продуктов осмысления характерно, что они с трудом поддаются научному определению и варьируются в значительной степени в общепринятом восприятии: понятие "гора" различаются в языке не только у равнинных и горных народов, но даже и между разными горными этносами. В данном случае лексема "гора" - как абстрактная единица естественного языка и как простое отражение человеческих привычек восприятия и поведения будут больше походить на лексемы информатики, где под ними понимают "последовательность допустимых символов языка программирования, имеющая смысл для транслятора".
И здесь география отчасти заходит на территорию философской онтологии, рассматривающей специфику существования различных объектов окружающего нас мира. В основе современных онтологических концепций лежит признание действительного существования атомов и электронов, клеток и организмов, планет и солнечных систем, а также чисел, множеств и абстрактных математических сущностей ими образуемых. Далее все несколько усложняется - если существуют обособленные истинные сущности, то существуют ли категории, их описывающие? С позиций онтологии утвердительный ответ на этот вопрос возможен только при разработке релевантной количественной оценки и предсказания (т.е., моделирования) таких категорий. Продолжая пример с кошками, можно утверждать, что существуют как отдельные реальные кошки, так и виды (породы) кошек, потому что мы в состоянии описать категорию "порода" (короткие загнутые ушки, серо-голубой окрас, белые "носочки" на лапах и т.д.).
Если переиначить наш вопрос о реальности географических объектов ("Do Mountains Exist?") мы должны задать его следующим образом: является ли возможность однозначного моделирования объектов ("горы", "ландшафты") обязательным условием признания реальности их существования? Общепризнанного ответа на этот вопрос мы не обнаружим: в отечественном естествознании объективность существования объектов не ставится в прямую зависимость от возможности их строгого описания и/или моделирования (классический пример - "природные ландшафты"); в зарубежной, особенно англоязычной географии, напротив, не принято утверждать что объект (тот же природный ландшафт) действительно существует, если наука не способна однозначно задать условия его существования [Kirchhoff et al., 2013].
Подобный вывод противоречит нашему повседневному опыту: с позиций обычного человека горы, безусловно, существуют, в том числе и как категории: "сегодня мы прошли по пологой тропе поднявшись на свод невысокой горы, а завтра нам предстоит совершить восхождение по крутым скальным стенкам высокой горы". Однако, означает ли это, что, нарисовав график с двумя осями (скажем, ось Y - крутизна, а ось X - высота) и нанеся на него значения для тысячи земных гор мы сможем ответить на два вопроса:
1) что такое "гора", т.е., какие пороговые значения высоты и крутизны (или иных привлеченных для характеристики параметров) отделяют эту форму от любой другой положительной формы рельефа (например,"холмы", "сопки" или "плато");2) если множество гор представлено различными "типами" (классами, таксонами), то каковы граничные значения этих таксонов?
Онтологические основания и концепции необходимы в геоинформатике для постановки и формулировки задач определения используемых понятий, прежде всего путем их формализации в рамках некоторой области с хорошо понимаемой логической и семантической структурой [Smith, David, 2003]. Возвращаясь к нашему случаю, современное ГИС-моделирование не занимается такими вопросами, как "существуют ли горы?", скорее побуждает ставить другие вопросы: должна ли гора быть категорией в нашей системе знаний, и если да, то как следует определять категорию "гора?" и какие параметры пригодны для презентации отдельных гор в некоей общей базе данных? Как мы увидим далее - сама попытка получить ответы средствами геоинформационного моделирования, с одной стороны, позволяет добыть новое знание о реальной действительности, с другой - ставит перед нами новые вопросы.
9.2 Научные категории как прототипы здравого смысла
Роберт Хортон [Horton, 1982] полагал, что повседневный человеческий опыт существования и перемещения в мире "подлинных сущностей" (объектов первой категории по Гибсону) заставляет нас формулировать "первичные теории", ориентированные на так называемую мезоскопическую, т.е., соразмерную с нашими телами и масштабом ежедневных перемещений реальность. Первичные теории, называемые еще здравым смыслом (common sense), легко переводятся с одного языка на другой, а суждения, выражающие их суть, характеризуются конвенциональностью - широко распространенным непринужденным согласием.
Здравый смысл по большей части оперирует с объектами, относящимися к первичным категориям (такими, как "кошка" или "дерево") и характеризующимися свойством прототипичности, узнаваемости и репрезентативности. Иными словами, они являются лучшими образцами своих множеств. В обычных обстоятельствах люди легко различают прототипические примеры, лежащие в основе категорий здравого смысла, и периферийные примеры, существующие как бы в "полутени" прототипов. Так, гора Ма́ттерхорн (Рис. 9.1) не случайно изображена на упаковке плитки шоколада Toblerone - это типичный трехгранный карлинг Пеннинских Альп с вершиной типа пик и острыми гребнями (гранями контрфорсов); как прототип она признавалась "горой" горцами Швейцарии и Италии, и этот образ перешел как символ достижения в современный альпинизм, а потом уже был растиражирован как рекламный знак.

Рис. 9.1 Карлинг Маттернхорн - типичная "гора", с выраженным свойством прототипа
Каждое семейство категорий здравого смысла может быть изображено в виде дерева с более общими категориями у корня и более конкретными - ближе к вершинам ветвей. Где-то по протяжению "ствола" находится "базовый уровень", который в "когнитивной экономике" характеризуют как компромисс между двумя противоположными целями: информативностью, с одной стороны, и минимизацией категорий, основанных на нерелевантных различиях, - с другой [Smith, David, 2003]. Иными словами, это компромисс между недостаточной конкретностью "нижних" категорий (высокие горы вообще) и когнитивной стоимостью усилий, затрачиваемых для определения "верхних" (пики-карлинги альпийского выше 3500 м крутизной склонов более 18o с выраженными гребнями и контрфорсами). В этом смысле общегеографические понятия - такие как гора, остров, озеро и т.д., попавшие в науку непосредственно из области здравого смысла, являются категориями базового уровня. Их дальнейшее уточнение в качестве научных понятий неизбежно сопряжено с выходом за пределы обыденных представлений, потому что реальное множество географических объектов не может быть задано простыми установками типа: "эта форма рельефа выше 500 м и поэтому она, несомненно, гора".
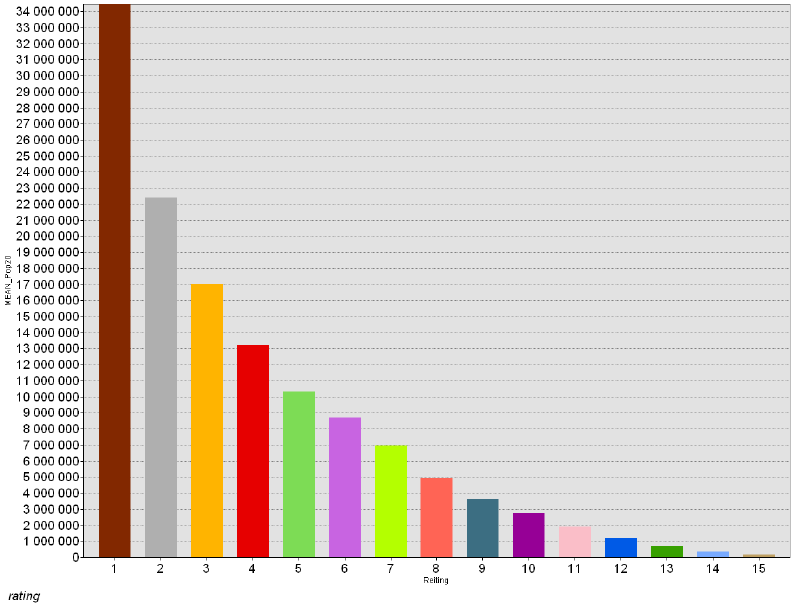
С позиций информационной онтологии неверными являются не только бытовые представления о географических объектах, но и значительная часть квазинаучных понятий и классификаций, приводимых, обычно, в учебниках в качестве твердо установленных истин. Таковы классы гор разделенных по высоте, или классы городов разделенных по численности населения, поскольку на самом деле (и в случае с горами, и в случае с городами) они не соответствуют граничным значениям, получаемых при любом способе классифицирования нормально распределенных множеств соответствующих объектов (высот, или людности), не говоря уже о том, что на самом деле эти множества распределены, как правило, не нормально, [Jiang, 2015]. К сожалению, эти представления выполняют не только дидактическую роль (т.е., составляют содержание учебников), но и "встроены" во многие разработанные к настоящему времени алгоритмы ГИС-моделирования, и это доминирование представляет собой отдельную (не всегда осознаваемую пользователями ГИС) проблему методологического свойства.
9.3. Географические объекты как "поля" и ограничения традиционного категориального картографирования
Другая, не менее серьезная методологическая проблема, связана с тем, что географические объекты долгое время воспринимались (и продолжают восприниматься) как объекты первого когнитологического типа - т.е., истинные объекты-отдельности с безусловно существующими физическими границами [Колбовский, 2013]. Эта унаследованная традиция повлекла за собой совершенно определенные тренды в развитии ГИС-моделей, направленных в значительной степени на воспроизводство разного рода тематических карт, например, геоморфологических, почвенных, геоботанических или ландшафтных, основными элементами которых являются "отдельные сущности": мезоформы рельефа, почвенные разности, растительные ассоциации и отдельные ландшафты, разделенные границами. Такое "объектное" моделирование в значительной степени основано на всей предшествующей истории восприятия природы человеком, восприятии, которое всегда содержало оценочную, утилитарную или эстетическую характеристику, и которое поневоле вынуждало наблюдателя делить воспринимаемое на "составные" части - элементы.
Но здесь, опять-таки, проходит рубеж между бытовым представлением и научным объяснением: четкие границы могут восприниматься наблюдателем и там, где на самом деле они не существуют. Именно по этой причине, уже на заре развития геоинформационного моделирования "объектные" модели столкнулись с серьезными трудностями [Cushman et al., 2007] в самых разных разделах физической географии и ландшафтной экологии.
Для ГИС-моделирования как ни для какого другого раздела географии важен переход от объектно-ориентированной методологии к методологии "полей", основанной на непрерывных функциях, аргументами которых являются позиции в некоторой пространственной области, и параметрами которых являются атрибуты. Одна из естественно-научных теорий "полей" - теория рельеф-поля была разработана в геоморфологии практически одновременно как отечественными [Ласточкин, 1987; Степанов, 2006], так и зарубежными исследователями [Evans, 1980; Wilson, Gallant, 2000], еще до появления действительно Больших Данных и Цифровых Моделей Рельефа.
В геоморфологическом моделировании ("геоморфометрии" - в традиции зарубежной географии) теория "рельеф-поля" постулировала два важнейших обстоятельства:
1) различия в выраженности так называемых характеристических линий рельефа (линий вогнутых и выпуклых перегибов профильной и плановой кривизны), которые могут изменяться от четко выраженных граней между элементарными топологическими поверхностями (уступ между поверхностью и склоном террасы) до плавных переходов, когда сама зона перехода по сути может трактоваться как самостоятельная элементарная поверхность (полого-выпуклая верхняя часть склона террасы);2) критическая значимость соседних элементарных поверхностей для определения границ и типологии данной конкретной элементарной поверхности - ровная площадка может быть и привершинной поверхностью и днищем котловины - в зависимости от граничащих с нею склонов.
Современное геоморфометрическое ГИС-моделирование позволяет учитывать оба этих обстоятельства посредством введения различных (производных от поля высот) переменных, однако в других областях географии, которые имеют дело с разными сущностями, (не только с рельефом, но и с почвами и/или растительным покровом) проблемы корректного отображения континуальности объектов реального мира еще не решены.
Непрерывность изменения атрибутов сложных феноменов, также как и наличие постепенных переходов от неких ядер типичности к постепенным (иногда довольно протяженным) переходам-экотонам между ядрами доказана в почвоведении, в биоценологии и ландшафтоведении. Комплексные сущности - такие как природные ландшафты формируются в многомерном пространстве признаков, неопределенность которых с неизбежностью должна приводить к континуальности как системному свойству, при котором резкие границы будут являться скорее редким исключением из правил, чем правилом. Однако современные ГИС-алгоритмы до сих пор не слишком приспособлены для отображения этих аспектов концептуализации окружающего нас реального мира и, в значительной степени, воспроизводят существовавшие ранее традиционные экспертно-мануальные подходы, направленные либо на моделирование объектов с четкими "краями" (векторная графика полигонов с их границами), либо на моделирование растровых мозаик, состоящих из отдельных "патчей".
Многие методы картографирования и ГИС-моделирования в ландшафтоведении и ландшафтной экологии берут свое начало в классическом Categorical Mapping|Категориальном картографировании, разбивающем реальное пространство на непересекающиеся ареалы, или полигоны [Cushman et al., 2009]. Отдадим этим методам должное - традиционное категориальное картографирование сыграло огромную роль в практиках различных отраслей (сельского и лесного хозяйства, градостроительного и регионального планирования) а также в рационализации природопользования и охране природы; с его помощью были разработаны практически все виды современного геоэкологического моделирования и основанные на них подходы к правовому экологическому зонированию и нормированию.
Однако, нельзя забывать, что в основе концептуализация пространства при категориальном картографировании лежит предположение о дискретности природы, получившее воплощение как в векторных (с геометрическими примитивами в виде полигонов, точек и полилиний), так и в растровых (с ячейками, составляющими "патчи") моделях. В современной ландшафтной экологии традиционное картографирование подвергается критике по трем основаниям [MacGarigal, Cushman, 2004].
Во-первых, выбор параметров картографирования и граничных значений для них оказывает существенное воздействие на то, какие именно структуры и процессы выявляются и получают отражение в конкретной модели. Во-вторых, так называемая субъектность (или "антропоморфизм") моделирования, заключающиеся в том, что отбираемые параметры всегда оцениваются с позиции наблюдателя, т.е., человека, но фиксируемые при этом границы могут не играть никакой роли в жизненном цикле большинства представителей фауны и флоры (аргумент, особенно сильный в науке о "природном ландшафте"). Наконец, в третьих - создаваемые в этой же технике патчевые и полигональные структуры, по сути, игнорируют любые различия внутри однотипных фрагментов растра или векторного ареала. Эта проблема усугубляется при отсутствии у моделируемого феномена признаков нормального распределения. Совокупный эффект, генерируемый этими тремя особенностями традиционной картографии и воспроизводимый в ГИС-моделировании, может приводить к существенным искажениям реальности.
Первые попытки ГИС-моделирования сложных объектов использовали картографический прием наложения категориальных карт (Overlay), но очень скоро выяснилось, что при строгом алгоритмическом исполнении соответствующих операций комбинирования матриц - Combine (для растров) и пересечения - Intersect (для векторных полигонов) выявляются глубинные дефекты категориальной дифференциации: возникновение значительного количества избыточных плохо интерпретируемых классов (возрастающее экспоненциально при увеличении числа накладываемых карт) и некорректная проработка общих границ ("эффект пилы") вдоль краев. Неудивительно, что в "многослойных" (т.е., мультифакторных) моделях после каждой новой комбинации категориальных данных возрастал "информационный шум" и одновременно умножались потери тематической информации, вызванные избыточностью частных тематических классификаций, использованных "как есть" [Колбовский, 2020].
9.4. "Патчевые модели" как упрощение непрерывных полей
Подавляющее большинство свойств, феноменов и явлений, моделируемых средствами ГИС, на самом деле описываются непрерывными параметрами: так свойство "высота местоположения" принадлежит непрерывному полю высот земной поверхности. Сведение этой поверхности к мозаике полигональных векторов или патчей ячеек грида вызывает проблемы представления и интерпретации из-за неточностей в размещении границ и разделении классов, а также потому, что вариации параметра высоты различаются в разных масштабах [Wu, 2007].
Неслучайно исследователи из разных областей географии и геоэкологии отмечают два существенных преимущества моделирования окружающей среды с привлечением набора параметров в виде индивидуально изменяющихся градиентов. Таким образом сохраняется неоднородность значений переменных в пространствах разных иерархических уровней и соответствующих им масштабов. При привлечении разных переменных мы сохраняем разнообразие каждой, не сводя их на предварительных этапах в категории с определенными границами; одновременно исключается субъективность назначения пороговых значений. Эти обстоятельства делают более объективным многомерный анализ, включающий множество переменных, в особенности - моделирование сложных географических объектов "второй категории", таких как "почвы", "эколого-ценотические группы" или "природные ландшафты".
Потребность в разработке методов градиентного анализа непрерывных полей возрастает по мере появления и накопления Big Data - высокоточных и объемных по размерам данных. Казалось бы, современные лидарные съемки древесного полога с возможностью различения крон отдельных деревьев должны "работать" на моделирование природных ландшафтов в локальных масштабах на самых нижних иерархических уровнях ландшафтной дифференциации (фации или урочища). Однако ГИС-моделирование показывает, что традиционные категориальные карты, построенные по таким данным с целью отображения даже только одного параметрам "плотности" полога не являются корректными, т.к., полученные полигональные ареалы не отвечают полностью ни одному из трех требований: не являются внутренне более гомогенными по сравнению с соседними, их границы не отражают реальных перемен значений, а граничные значения не лучшим образом дифференцируют классы [Evans, Cushman, 2009]. Данное затруднение является одной из причин того, что поступление в распоряжение исследователей год от года все более точных данных (с размерностью, которая менялась от многих сотен метров до первых дециметров в пикселе) не сопровождается соответствующим процессом усовершенствования LULC покрытий, ландшафтных карт или карт почвенного или растительного покрова.
Эта проблема заставляет вспомнить о значительных усилиях и средствах, затрачиваемых десятилетиями по всему миру на составление и воспроизводство категориальных карт отраслевого и экологического содержания (экосистемы и ландшафты, почвы и леса) и ГИС-моделей специальной тематики, например, моделей фрагментированности и "связности" природных экосистем и ландшафтов [Cushman et al., 2007]. Один из авторов методологии FRAGSTAT-анализа Кевин МакГаригал признавал, что даже если классификация на уровне типов патчей была максимально точной, она все равно искажает структуру реальности за счет искусственного определения границ в непрерывном ландшафте, затушевывания внутренней изменчивости и преуменьшения размеров и функциональной роли экотонов разного рода [McGarigal, Marks, 1995].
Другое непреодоленное противоречие категориальных моделей - их неспособность отражать изменчивость параметра (или набора параметров) в различных пространственных масштабах. Базовое понятие ландшафтной экологии - экологическая ниша характеризуется как n-мерная функция множества условий, каждое из которых действует в определенных пространственных масштабах [Бигон, Харпер, Таунсенд, 1989]. Иными словами значения n-мерной функции могут изменяться вдоль континуума пространственного масштаба, отражающего как иерархию отдельных переменных, так и иерархический характер ландшафтной структуры и вложенных в эту структуру отдельных ниш. Экологические градиенты, конфигурирующие нишу, являются клинами в n-мерном экологическом пространстве, в географическом пространстве эти же градиенты часто образуют сложные разномасштабные структуры [Cushman et al., 2007]. Так, например, дифференциация горной области на макросклоны и разделяющие их гребне-килевые элементы (хребты и распадки) определяет (до известной степени) границы кормового ареала хищника, и мы можем моделировать эти особенности с использованием разных геоморфометрических переменных; но наличие конкретных вогнутых микропонижений на тех же склонах, предоставляющих хищнику убежище (не менее важные для его жизненного цикла) не выявятся при анализе в единственном ("оптимальном") масштабе, который в каждом конкретном случае будет задаваться размером "окна" и дистанцией поиска.
В более широком смысле можно говорить о кризисе "ландшафтно-мозаичного" подхода, предполагающего возможность отображения окружающей среды в виде дискретных пятен, представляемых как "типы" (типы растительности, типы ландшафтов, типы почв), которые затем в прикладных целях реклассифицируются на различные типы ландшафтно-земельного покрова (LandUse/LandCover), либо, в бинарной логике - на "местообитания" (habitat) и враждебное окружение. Таким образом, создаваемые в специальных программах (Fragstat) или приложениях к ГИС (Patch Analyst) "патчевые модели" является упрощением, допустимость которого весьма относительна.
Например, лесные опушки, рассматриваемые в этой парадигме как "буферные" зоны враждебного внешнего воздействия зачастую демонстрируют более высокое биоразнообразие в отношении, например, орнитофауны, чем внутренние "ядерные" части лесных массивов, при этом сопряженный анализ популяций разных видов птиц с мозаикой растительных сообществ показал, что большая часть дисперсии в численности видов не может быть объяснена картографированными типами сообществ [Cushman, McGarigal, 2004].
Все эти соображения выводят на первый план сложную фундаментальную задача развития градиентного моделирования, решение которой связано, во-первых, с разработкой ГИС-моделей оценки нечеткой принадлежности значений к таксонам внутри привлекаемых для модели параметров и в их сопряженных наборах, во-вторых - с предсказанием вероятности проявления тех или иных свойств ландшафта [Evans, Cushman, 2009]. Возможно, что на выходе таких моделей мы увидим не знакомые нам "категориальные карты", а "пулы возможностей" с диапазонами ресурсов и условий. Тогда привычное понятие "экологическая ниша" конкретного вида будет выглядеть как n-мерный гиперэллипсоид с внутренней оптимальной областью существования и "облачностью" уменьшающихся вероятностей по периферии. Такой гиперэллипсоид будет отражать градиентные, соседские и категориальные качества среды обитания, причем последние будут скорее частным случаем общей закономерности [Cushman, McGarigal, 2004].
9.5. Сложность в исходных данных: "гауссово" и "паретианское" восприятие в геопространственном моделировании
Многие исследователи полагают, что в геоинформационном моделировании (вслед за традициями "бумажной" картографии) до сих пор продолжает доминировать "гауссовский" способ восприятия реальной действительности [Jiang, Brandt, 2016]. Иными словами, мы предполагаем, что множества различных географических объектов в окружающем нас мире могут быть удовлетворительно охарактеризованы корректно определенным средним значением.
В свою очередь это предположение зиждется на здравом смысле и ощущении, что "все сосны в бору одинаковы", то есть изучаемые нами предметы более или менее похожи по размеру... И действительно, оказавшись в городском лесопарке и измерив высоту нескольких десятков сосен, мы может прийти к выводу, что средняя высота древостоя зрелого сосняка, скажем, 28 м - неплохо описывает всю совокупность, при том, что есть чуть более высокие и чуть более низкие экземпляры. Однако подобный вывод, скорее всего, окажется правильным только для "культуры сосны" - одновозрастных посадок, каковые составляют основную площадь многих пригородных лесничеств России. Проведя аналогичные замеры для деревьев естественного ("условно-коренного") разновозрастного леса, мы обнаружим немногие "акцентные" деревья-старожилы, на другом конце шкалы - угнетенные низкорослые и сухие "фаутные" экземпляры, некоторое количество средних экземпляров и огромную совокупность низких сосенок, относящихся к подросту и/или подлеску.
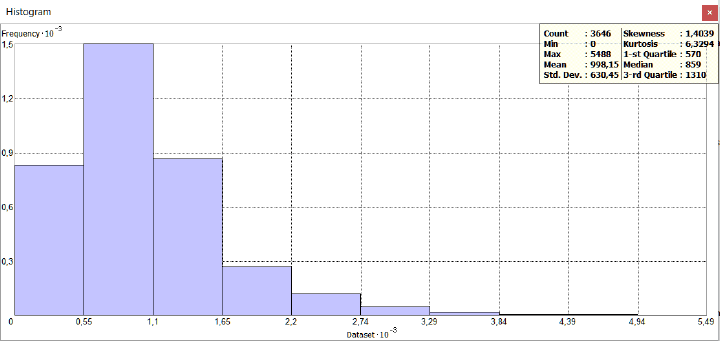
На самом деле многие объекта реального мира распределены таким образом, что небольшие и мелкие экземпляры распространены в гораздо большем количестве чем крупные. При изображении на графике частот (гистограмме) такое распределение выглядит как кривая с высоко "задранным" и прижатым к оси ординат уровнем высоких значений - эту часть образно называют Head|Голова, и удлиненным вытянутым вдоль оси абсцисс множеством низких значений, именуемых Tail|Хвост.
Head-and-Tail распределение было обнаружено в разных дисциплинах, но история науки чаще всего связывает этот феномен с именами трех человек: француза стенографиста Жана-Батиста Эсту, описавшего эффект в 1908 г., итальянца Парето, указавшего на то, что бедных людей гораздо больше, чем богатых, (а обычных людей гораздо больше, чем экстраординарных), и американского лингвиста Джорджа Ципфа установившего в 1949 г. что маленьких по численности населения и площади городов гораздо больше чем крупных.
В научно-популярной литературе распределение Парето было популяризировано как принцип 80/20 или теория "длинного хвоста" [Koch, 1999]. В статистике распределение Парето получило наименование степенного распределения, поскольку в этом случае относительное изменение переменной приводит к изменению зависимой величины по степенной формуле: например, при увеличении стороны квадрата вдвое его площадь возрастает в четыре раза.
Проблема, однако, заключается в том, что многие инструменты ГИС-моделирования и связанные с ними исследовательские алгоритмы, изначально "настроены" на нормальное распределение и подпитываются убеждением, что характер многих объектов, явлений и феноменов окружающей действительности может быть удовлетворительно описан с использованием некоей "средней" величины. Бин Сянг (Bin Jiang) полагает, что такой подход отражает системное господство "гауссова" (или "линейного") мышления, согласно которому всякое "малое" влечет за собой лишь "малое" следствие, а "большое" вызывает "большое следствие", что "целое равно сумме его частей", а мир достаточно хорошо предсказуем благодаря линейным зависимостям [Jiang, 2013a; Jiang, 2015; Jiang, Brandt, 2016].
9.6. Паретианское распределение и проблема классификации
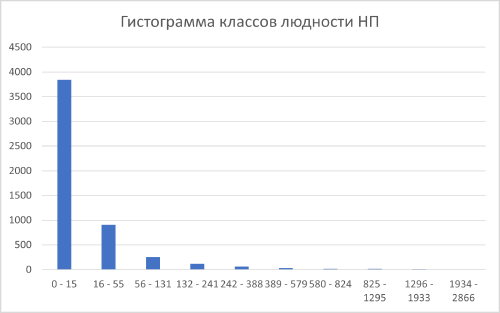
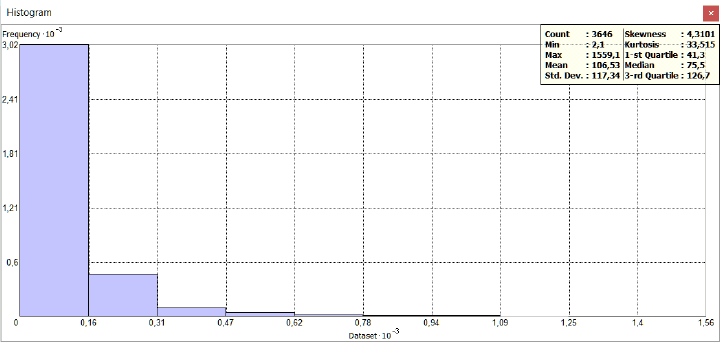
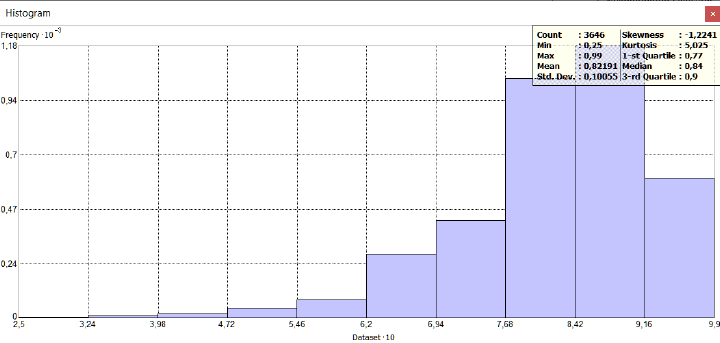
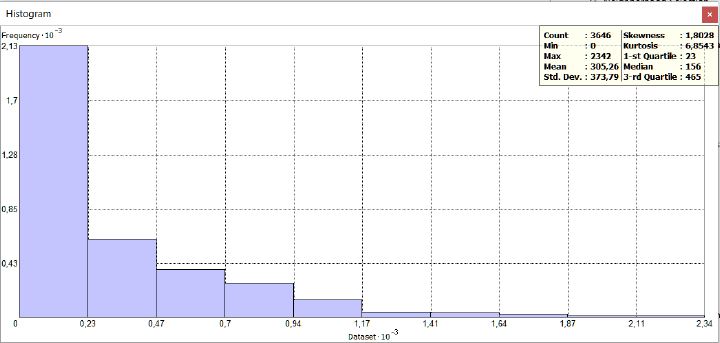
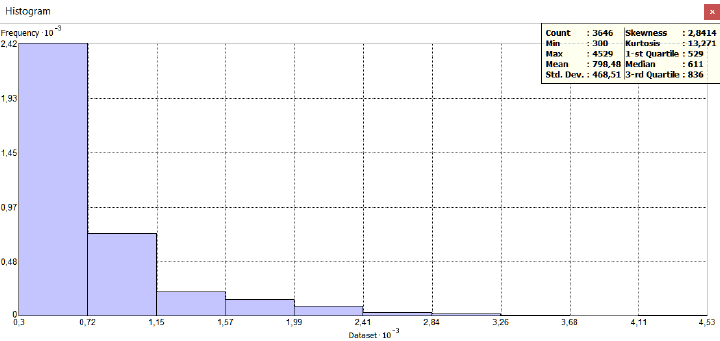
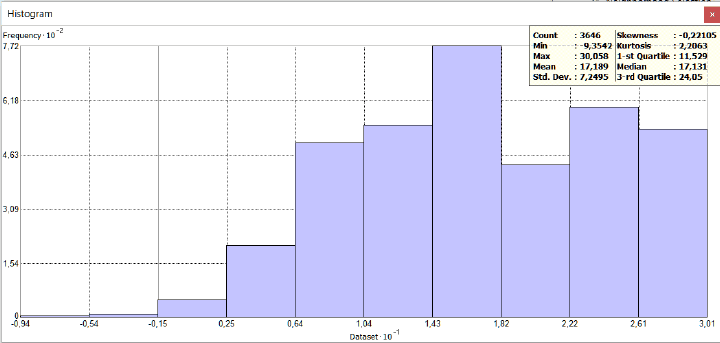
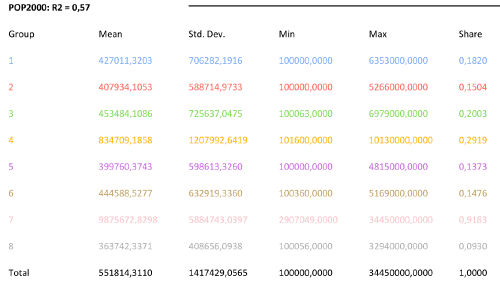
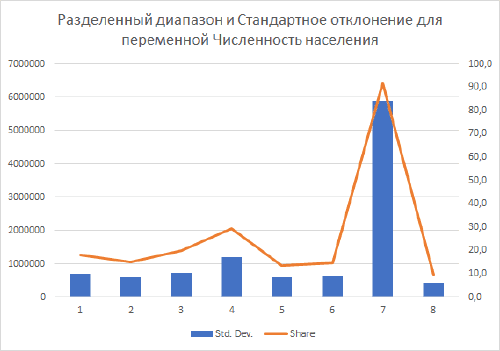
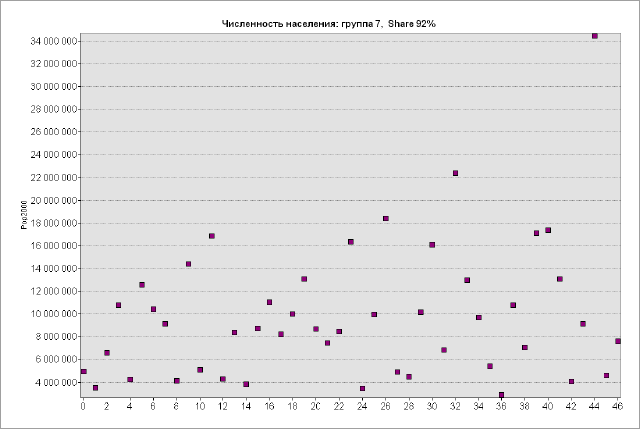
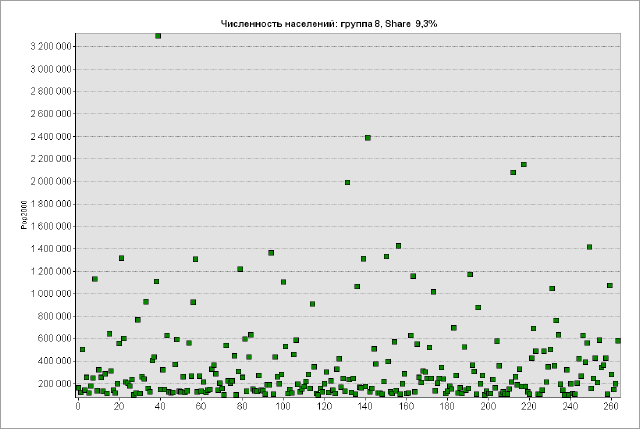
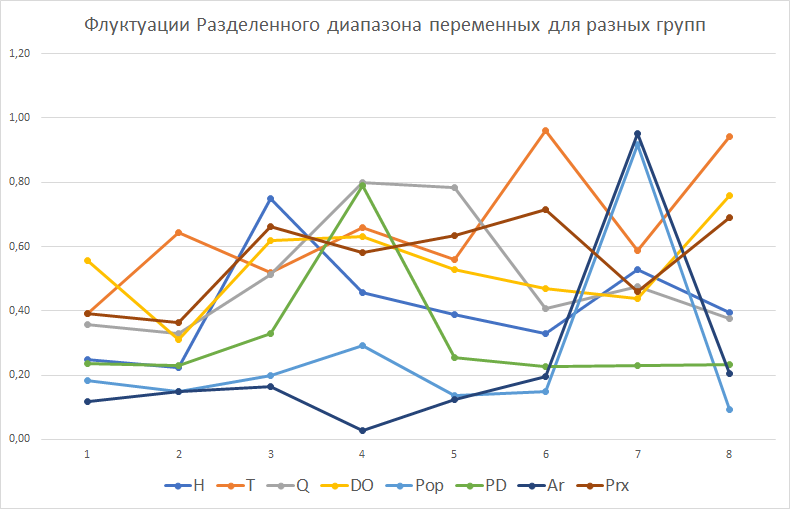
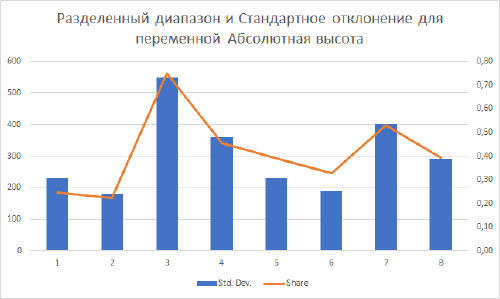
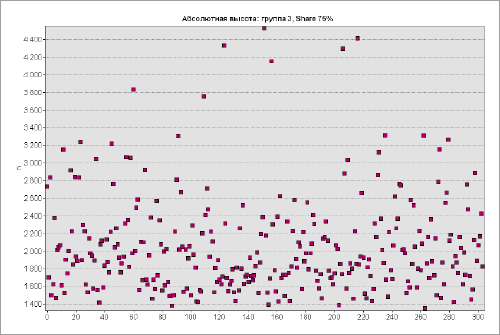
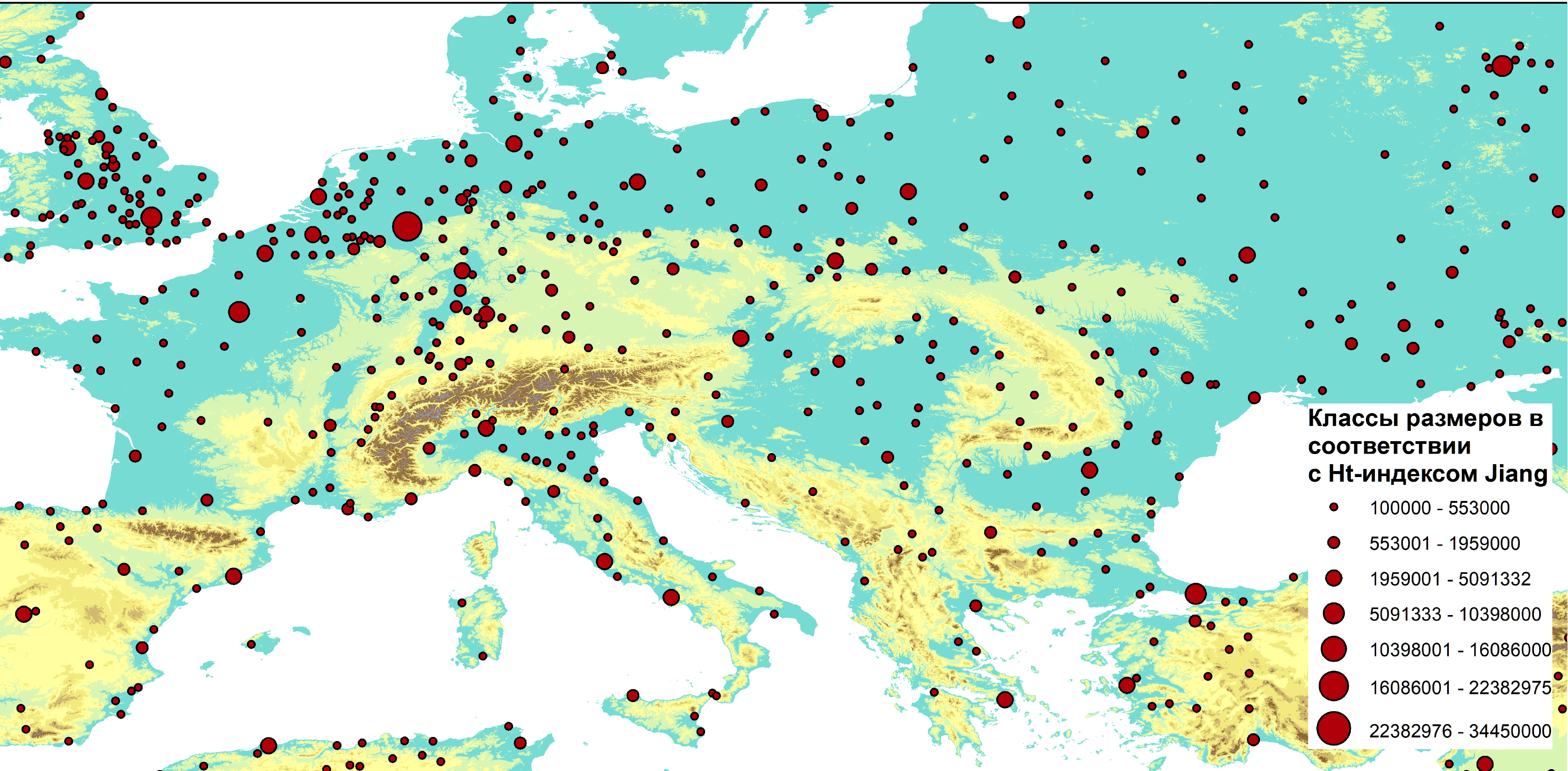
Для понимания отличий между гауссовым и паретианским распределением рассмотрим два относительно простых "классических" примера с объектами-множествами в разных масштабах. В качестве первого множества возьмем сельские населенные пункты Ярославской области с параметром людности, т.е., - численностью населения в существующих деревнях, селах и поселках городского типа (Рис. 9.2).
Как разбить это множество на классы? Метод естественных границ, пользоваться которым рекомендуют руководства и учебные пособия по ГИС [Лурье, Самсонов, 2016], использует такую группировку данных, которая позволяет достичь минимизации дисперсии переменной внутри классов и максимизации отличий между классами; таким образом выделяются естественные переломы в распределении значений, которые заметны на столбчатых гистограммах.

Рис. 9.2 Людность сельских населенных пунктов Ярославской области, 10 классов, способ natural break|естественные границы (фрагмент)
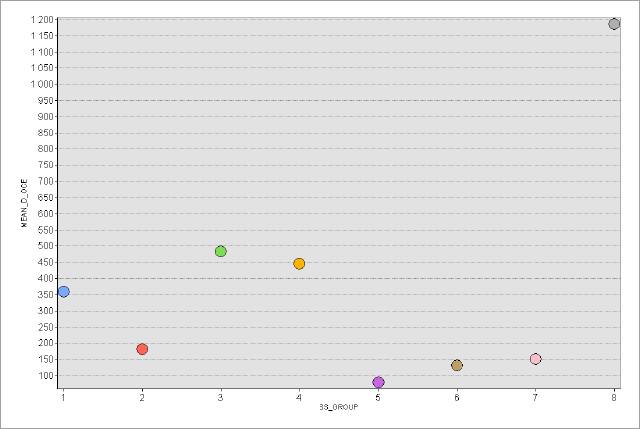
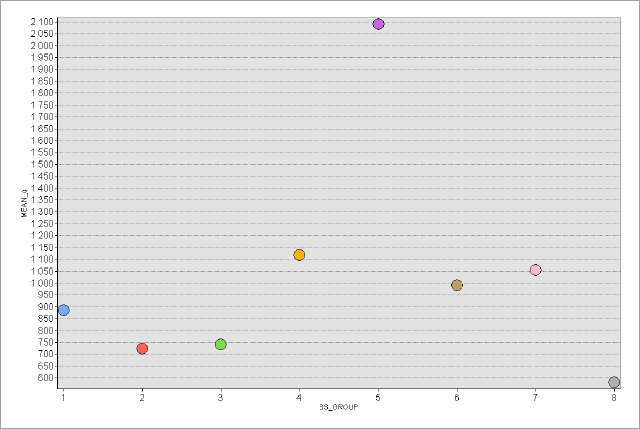
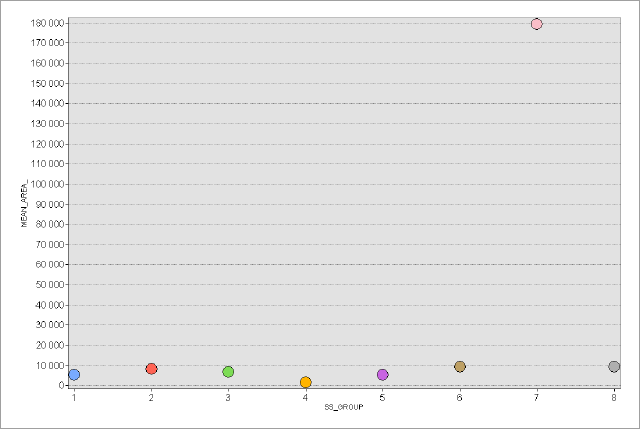
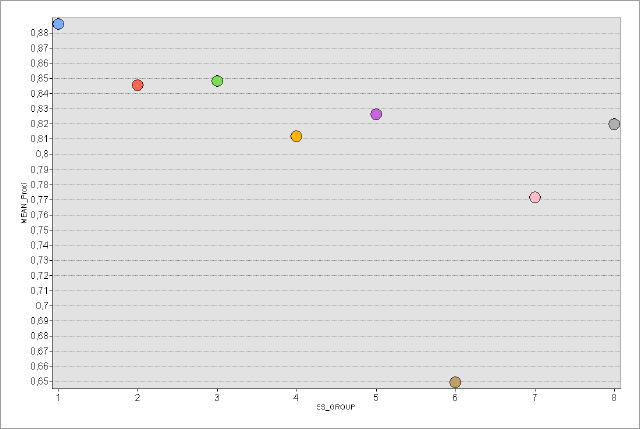
В ArcMAP10.x можно воспользоваться еще несколькими полуавтоматическими (т.е., эксперт задает число классов, остальное делает "машина") способами разбиения. Сравним пороговые значения при одинаковом числе классов (10) для трех разных способов разбиения множества: естественные границы, квантили и геометрические интервалы (Таблица 9.1).
Таблица 9.1 Пороговые значения таксонов (классов) людности при разных способах классификации