V. ДИАГНОСТИКА СЕЛЬСКОЙ МЕСТНОСТИ С ИСПОЛЬЗОВАНИЕМ ГИС-МОДЕЛИРОВАНИЯ
19. СОЦИАЛЬНО-ГЕОГРАФИЧЕСКИЙ АНАЛИЗ СЕЛЬСКОЙ МЕСТНОСТИ С ИСПОЛЬЗОВАНИЕМ ФЕНОМЕНА БЛИЗОСТИ
19.1. Постановка проблем: исчезающие деревни
Утверждение о том, что сельская местность подвержена депопуляции, забросу и запустению давно уже стало общим местом в работах по в социально-экономической географии. Понятно, что причины этого явления кроются в самых разных аспектах реальной действительности и инструментарий ГИС-моделирования тут не «всесилен». Однако можно предположить, что какие-то факторы, вполне поддающиеся измерению, играют свою роль в этом процессе, например такие как близость к крупным и малым городам, расстояние до железнодорожных платформ и автодорог, доступность образовательных учреждений и т.д. Попробуем выстроить исследовательскую модель, которая поможет хотя бы в самом первом приближении оценить роль тех или иных факторов в сохранении обитаемости (людности) сельских населенных пунктов (НП). Выстраивая модель важно задаваться правильными вопросами, что не всегда просто (Таблица 19.1).
Какие пространственные закономерности свойственны локализации населенных пунктов? Является ли их распространение случайным, дисперсным или кластерным?
Характеристика точек населенных пунктов через параметры центрографической статистики и переменные автокорреляции
Выявление медианных центров, определение паттерна распространения населенных пунктов, принятие или отклонение "нулевой гипотезы" автокорреляции
Как разделить множество населенных пунктов по природным свойствам?
Характеристика НП через набор природных факторов с последующей классификацией
Формирование растров морфометрических переменных на основе ЦМР, расчет близости по отношению к природным объектам, анализ группирования и кластерный анализ
Как разделить множество населенных пунктов по признакам социально-географического положения?
Моделирование доступности через расчет близости к социальным объектам-аттракторам, таким как крупные города, центры муниципальных районов, автодороги
Анализ главных компонент и определение коэффициентов корреляции и ковариации для независимых переменных
Отбор переменных
Как выбранные факторы влияют на исследуемый процесс?
Построение модели с использованием объясняющего (Exploratory) регрессионного анализа
Отбор переменных и избавление от избыточности модели
Насколько корректны выбранные переменные и существует ли возможность их более "тонкой" настройки?
Построение модели с использованием скорректированных переменных
Повторный регрессионный анализ с новым набором переменных
Насколько пространственная локализация НП влияет на результаты регрессионного анализа?
Проверка распределения точек НП на "нулевую гипотезу" и случайное распределение, построение матрицы весов
Построение географически взвешенной регрессии
В данной модели мы будем рассматривать сельские населенные пункты как «объект», обладающий свойствами, отражающими депопуляцию через параметр людности, позволяющий разделить деревни и села на нежилые и жилые, а последние классифицировать количеству зарегистрированных жителей. В качестве факторов, тем или иным образом влияющих на людность сельских населенных пунктов, можно привлечь как социально-географические, так и природные условия, в первую очередь такие, которые можно извлечь из доступных источников и подвергнуть моделированию в ГИС. Последним обстоятельством объясняется заведомая упрощенность используемой здесь модели, очевидно, что настоящая модель потребует привлечения многих данных из разных источников (количество непрописанных, но поддерживающих обитаемость населенного пункта городских рекреантов, категории и качество дорог, обеспеченность коммунальной и инженерной инфраструктурой, локальный рынок труда, состояние жилого фонда и т.д.).
В качестве факторов локализации и близости в модели людности сельских населенных пунктов рассмотрим следующие группы признаков.
Группа факторов локализации на рельефе:
относительная высота,
положение на форме мезорельефе.
Группа факторов ландшафтного местоположения:
близость к лесным массивам,
близость к рекам и озерам,
близость к болотам и т.д.
Группа социально-географических факторов:
удаленность от центров районов,
удаленность от границ района,
близость к автодорогам с твердым покрытием,
близость к железнодорожным платформам,
близость к вышкам сотовой связи,
близость к учреждениям среднего образования.
Моделирование каждой группы факторов можно рассматривать как отдельный блок модели. Блок локализации сельских населенных пунктов (далее – НП) включает:
построение тематических (геоморфометрических) растров – производных от цифровой модели рельефа,
извлечение значения растров в полигоны НП инструментами зональной статистики,
кластерный анализ (анализ группирования) с целью выявления типологии НП по признакам положения на рельефе.
19.2. Статистики пространственного паттерна
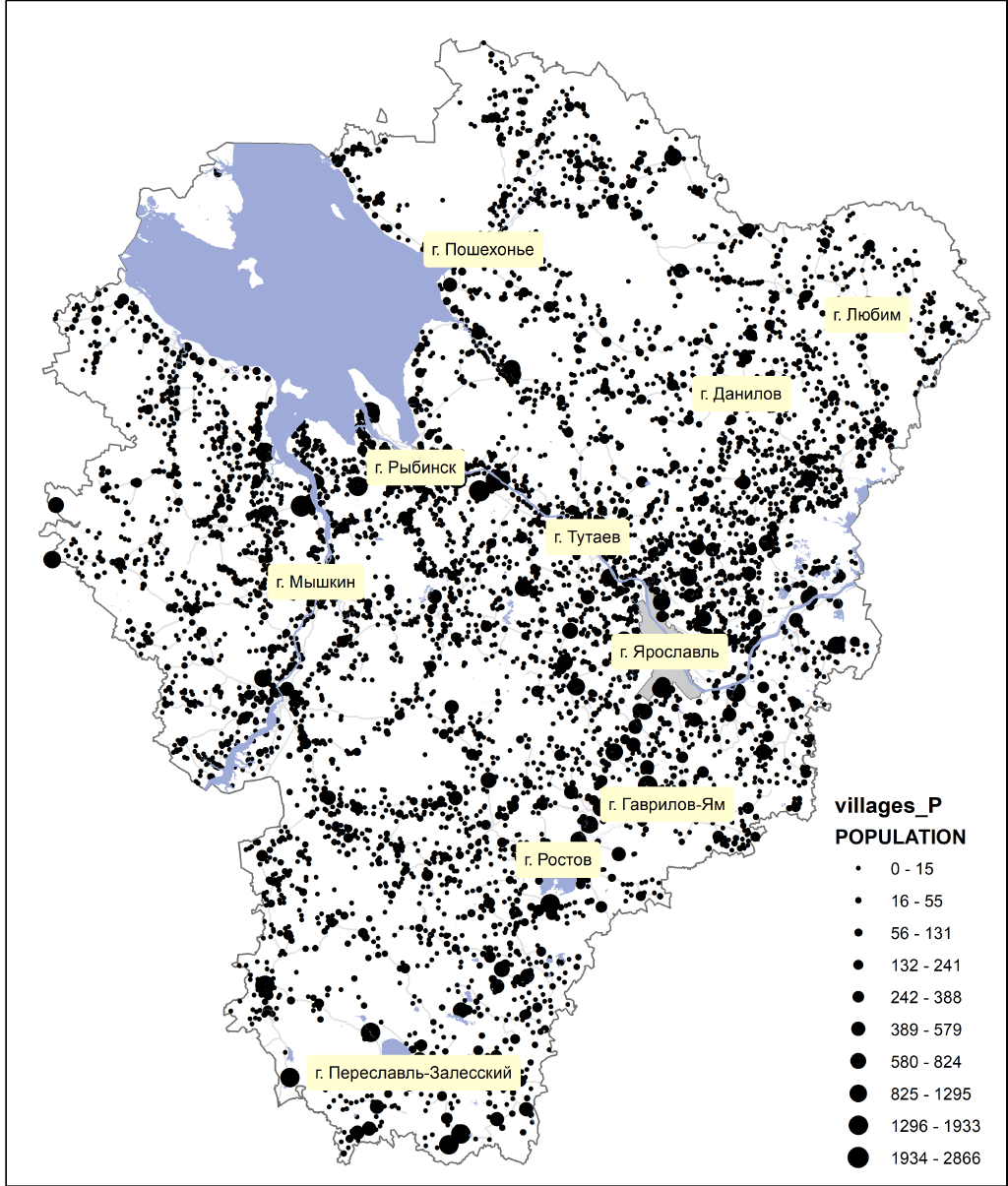
Базовый слой модели, содержащий независимую переменную - людность населенных пунктов - слой Village. В ArcMAP10.x чтобы получить векторный слой сельских населенных пунктов из исходного стандартного слоя OSMSettlement (неважно полигонального, или точечного) можно выбрать по полю PLACE объекты со значением village и hamlet, затем - сохранить выборку в качестве нового слоя Data >> Export>.
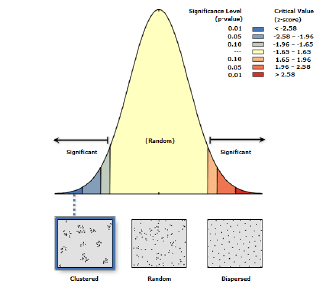
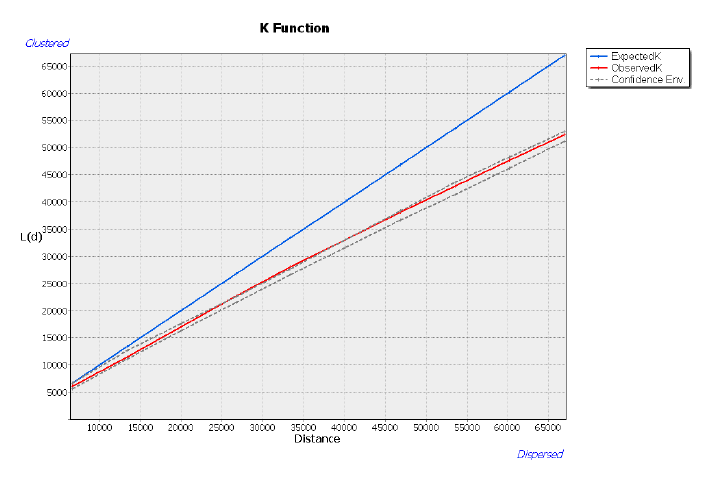
Z-оценка-43,06 располагается (Рис. 19.3.) в отрицательной области шкалы и значительно ниже пограничного значения -2,58. P-значение0,0000, свидетельствует, что наблюдаемый кластерный паттерн не может быть результатом полной пространственной случайности. Коэффициент Ближайших Соседей|Nearest Neighbor Ratio составляет 0,69 т.е., значительно меньше 1 и статистически значим на данном уровне 0,000P-значения, что также указывает на процесс кластеризации. Наблюдаемое среднее расстояние 1101,6 м ниже ожидаемого 1596,4 почти в полтора раза, что также свидетельствует о неслучайном размещении точек населенных пунктов (расстояние между ними в кластерах - "кустах" населенных пунктов ниже, чем если бы деревни были разбросаны дисперсно).
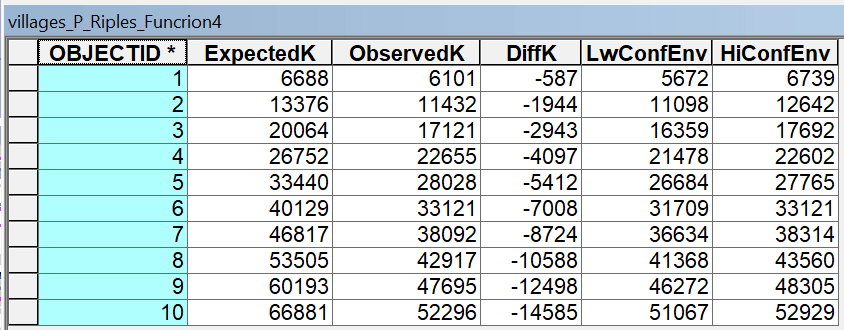
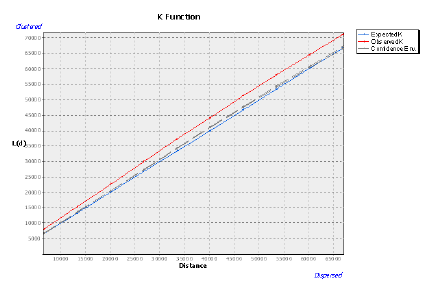
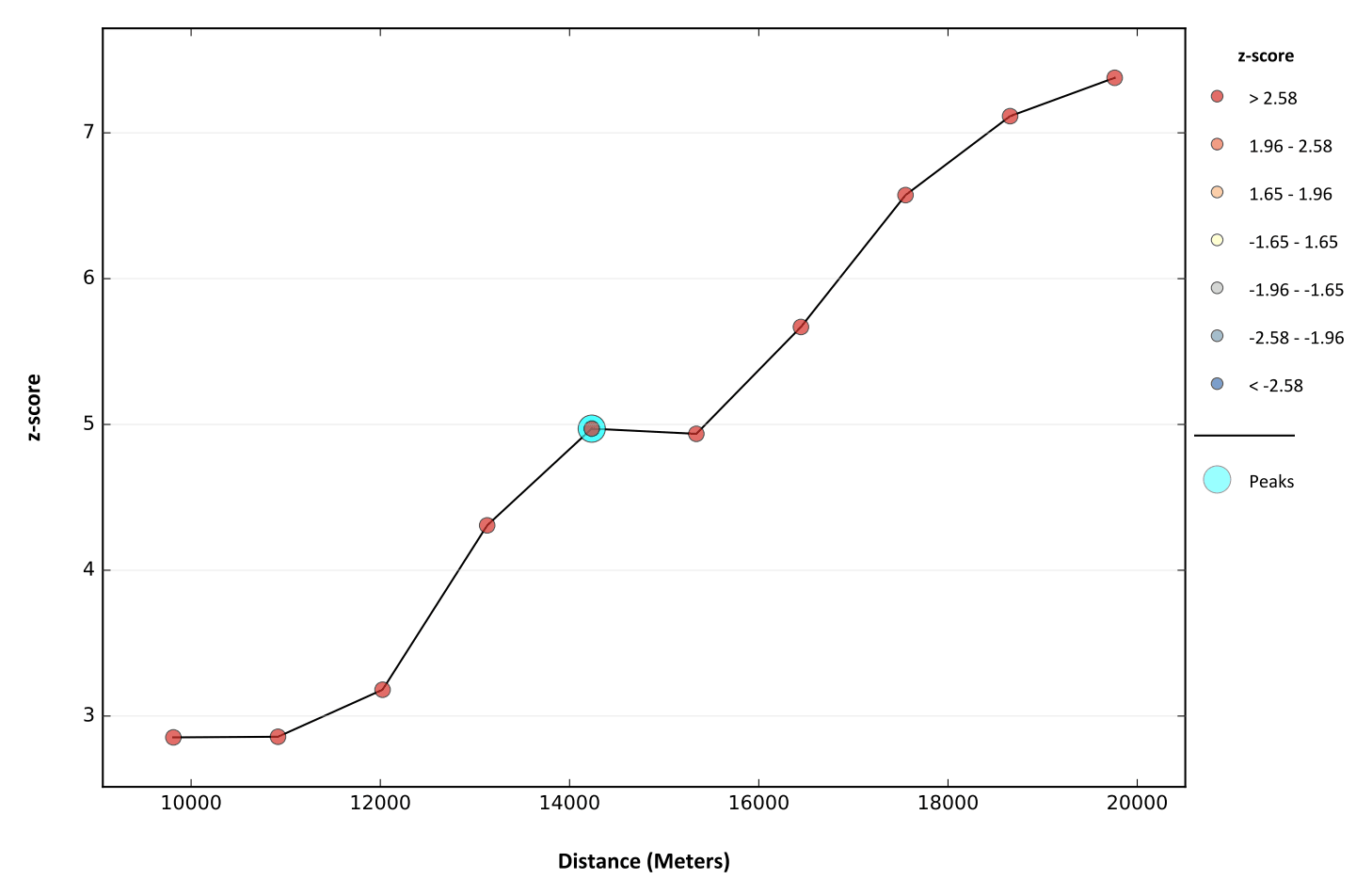
Построим Ripleys K Function|Функцию К. Рипли для набора точек НП, позволяющую выявить характерные дистанции, на которых происходит кластеризация объектов и/или их значений - в данном случае деревень c показателями людности в качестве весовой характеристики: ArcToolBox >> Spatial Statistics Tools >> Analyzing Patterns >> MultiDistance Spatial Cluster Analysis.
Input Feature Class: villages_P
Output Table: villages_P_Riples_Funcrion
Number of Distance Bands: 10
Compute Confidence Envelope: 9_PERMUTATIONS|9 наборов точек, от которых будут строиться окружности, размещаются случайным образом,
Weight Field: Population
Beginning Distance : blanc
Boundary Correction Methods: SIMULATE_OUTER_BOUNDARY_VALUES|условие для учета точек за пределами исследуемой области, если таковые имеются, чтобы не недооценивать количество соседей, для точек близких к границам,
Study Area Method: USER_PROVIDED_STUDY_AREA_FEATURE_CLASS|условие отнесения совокупности точек к изучаемому ареалу,
Study Area Feature Class: Oblast_Boundaries|указывается полигональный файл границ исследуемого ареала.
Рассмотрим результаты - график функции и таблицу расстояний Results >> Messages >> LC >> Result image; LC >> Output Table >> Open:
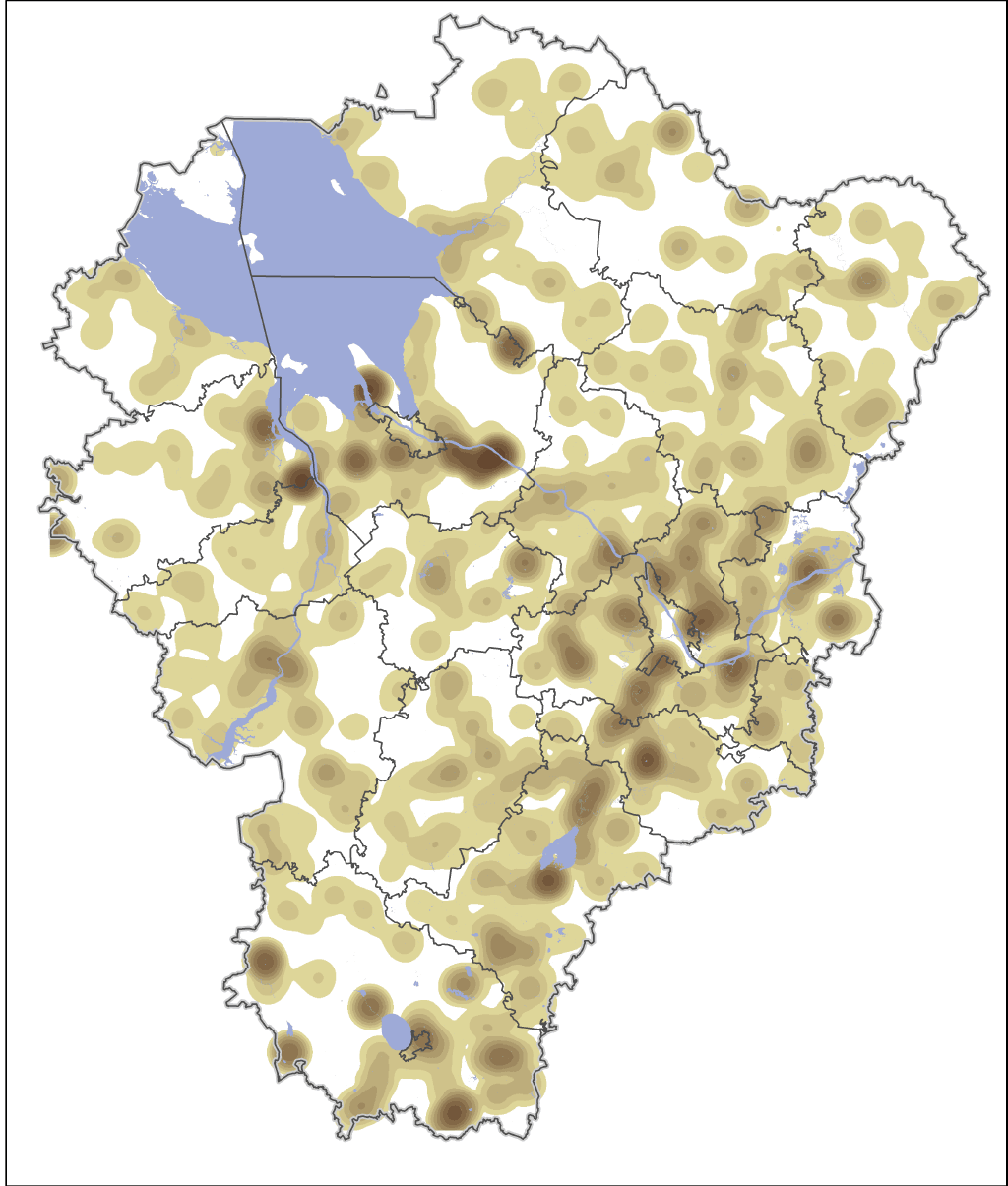
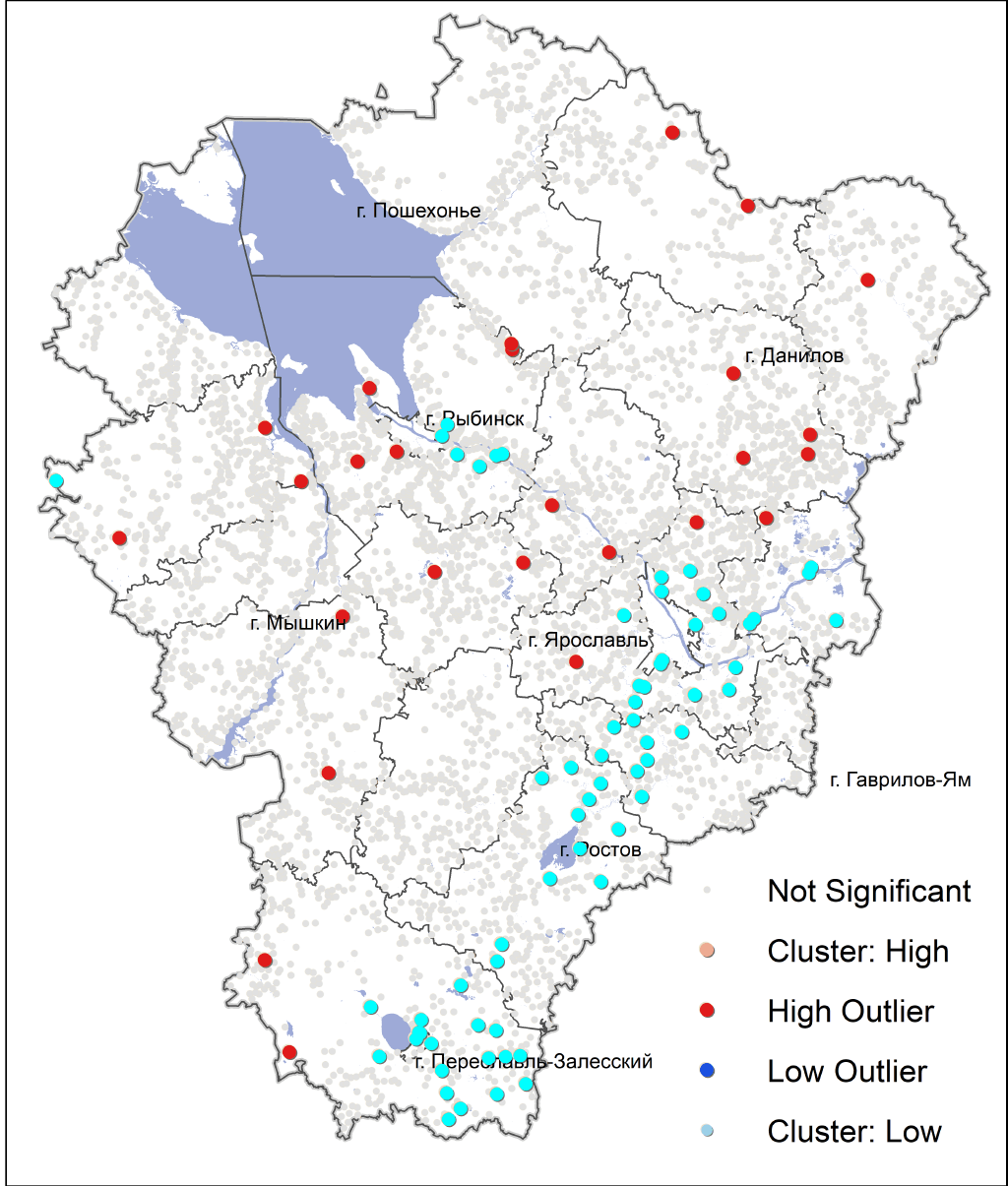
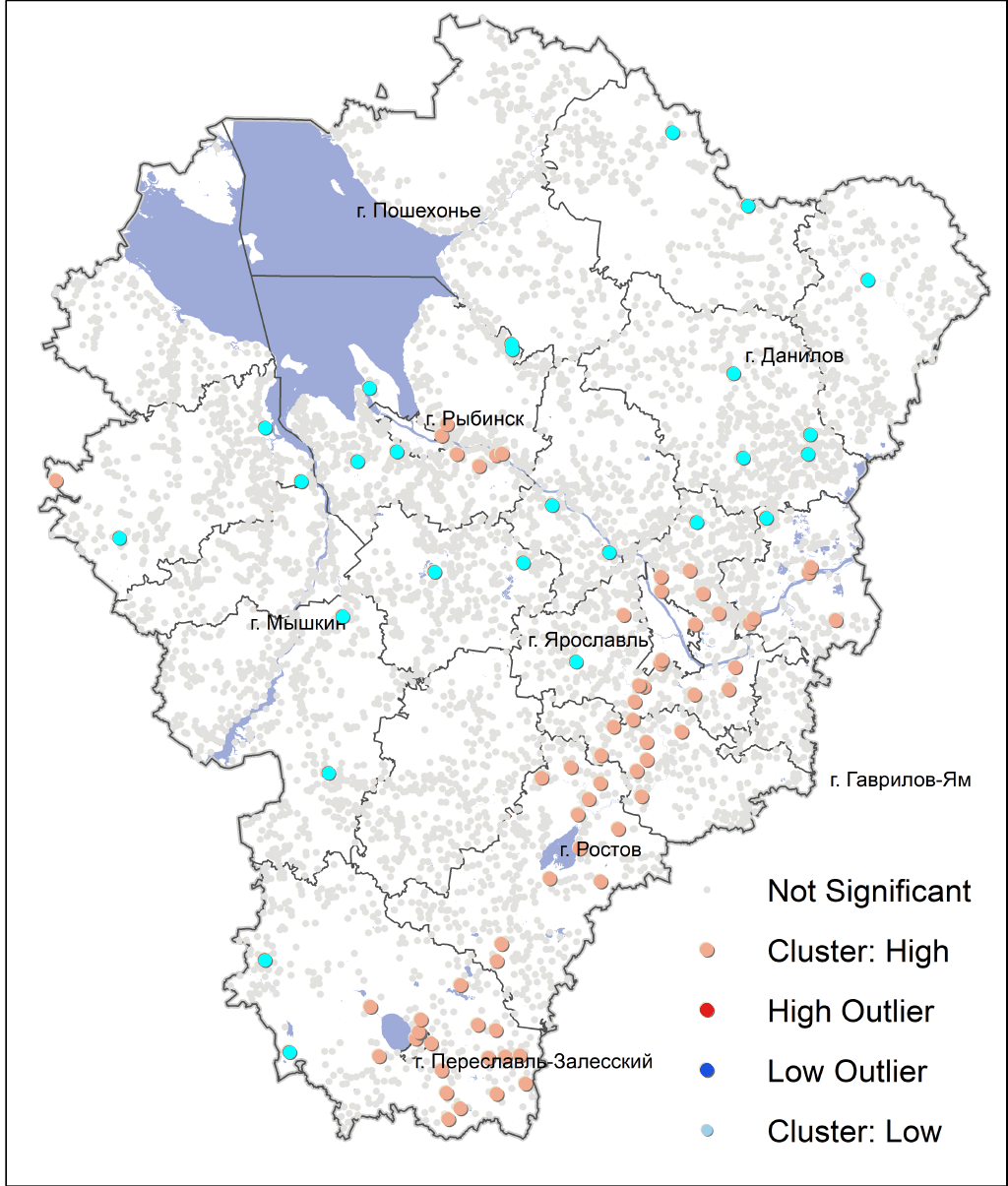
Распределение кластеров HighHigh и HighLow также выглядит закономерным (Рис. 19.12.): первые "привязаны" к федеральной трассе Москва-Ярославль и долине Волги в предместьях Рыбинска, вторые более-менее хаотично разбросаны в границах сельских муниципальных округов и действительно окружены полупустующими или малонаселенными деревнями.
19.3. Деревни на рельефе: размещение в пространстве мезоформ
Базовый слой ЦМР - модель ASTER GDEM2 90 m в пикселе;
служит основой для получения необходимых производных тематик:
нормализованная высота (показатель, переводящий абсолютные значения в значения шкалы от 0 до 1, что необходимо для последующего кластерного анализа);
геоморфоны – дифференциация мезоформ рельефа с использованием «машинного обучения» и «плавающего окна».
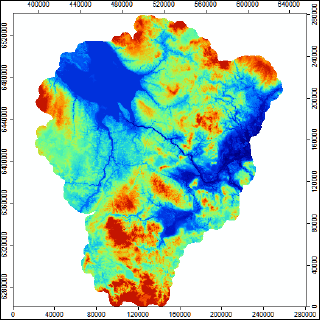
Поскольку ArcMAP10.x не богат собственными инструментами работы с рельефом откроем SAGA GIS загрузим файл ЦМР Ярославской области.
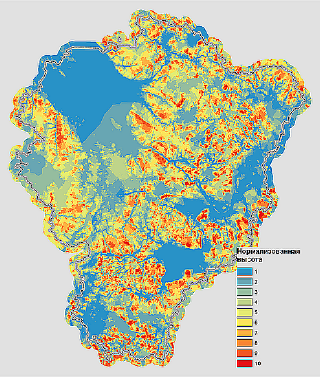
Рис. 19.13. Цифровая модель рельефа территории Ярославской области ASTER GDEM2
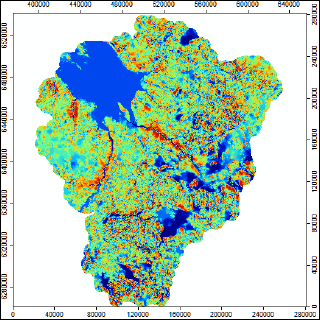
Для получения необходимых геоморфометрических тематик мы будем использовать две утилиты.: Relative Heights and Slope Positions (Terrain Analysis >> Morphometry), для расчета пяти метрик, из которых нам потребуется нормализованная высота Normalized Height.
Результат отличается от исходной ЦМР, поскольку нормализация шкалы обеспечивает более локальную проработку деталей рельефа.
Рис. 19.14. Нормализованная высота Normalized Height SAGA
Инструмент Geomorphons имеет непростой интерфейс с несколькими опциями, т.к., по сути, это довольно сложная модель. Опции инструмента, которые придется поменять при его запуске:
Threshold Angle – пороговое значение уклона, отделяющее плоский рельеф от склонов; оставляем без изменений;
Radial Limit– максимальный радиус «окна»; по умолчанию 10000, но для условия равнины выставляем 5000;
Method – по умолчанию «line tracing» - не меняем.
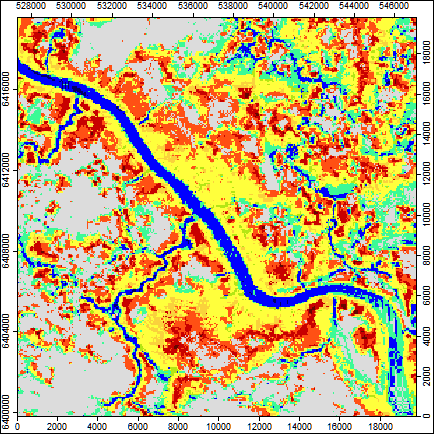
Итогом работы инструмента является атрибутированный растр, который в SAGA GIS сопровождается семантической легендой, однако при импорте растра в ArcMAP10.x мы сможем открыть таблицу слой и увидим значения Value (Long) от 1 до 10, которые расшифровываются следующим образом (рис. 19.15):
Рис. 19.15 Геоморфоны: фрагмент карты и расшифровка значений атрибутов растра
Чтобы как-то уравнять «в правах» две метрики рельефа, классифицируем в ArcMAP10.x растр Normalized Height на 10 классов способом Natural breaks (Jenks): (Spatial Analyst Tools >> Reclassify). Для удаления возможных «шумов» применим к классифицированному растру инструмент генерализации Boundary clean|Удаление границ, опция Descent.
Следующая задача – извлечь значения обеих тематик (факторов рельефа) в shape-слой населенных пунктов. В ArcMAP10.x это удобнее всего сделать с помощью инструмента Extract Multi Values to Points|Извлечь значения многих растров в точки(Spatial Analyst >> Extraction); в SAGA GIS - Add Grid Values to Points(Shapes >> Shape-Grid Tolls). Интерфейс инструментов аналогичен, на выходе получаем новые поля в таблице шейпа НП с извлеченными значениями геоморфонов и нормализованной высоты.
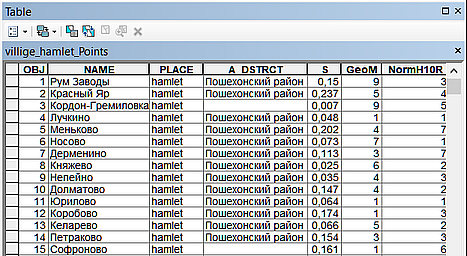
Рис. 19.17 Новые поля с извлеченными значениями геоморфонов и нормализованной высоты в таблице НП
Чтобы получить начальное представление о типах локализации населенных пунктов относительно условий рельефа проведем кластеризацию в ArcMAP10.x используя инструмент Анализ группирования ((Spatial Statistic Tools Mapping >> Clusters >> Grouping Analysis), опция without spatial restrictions) и с возможностью определения оптимального числа групп. Результат группирования (кластеризации) подвергнем слиянию (Dissolve), предварительно определим необходимые виды статистик, которые дают нам общую характеристику полученных кластеров.
Рис. 19.18 Кластеры НП, полученные Анализом Группирования по типу рельефа и классам нормализованной высоты места (фрагмент)
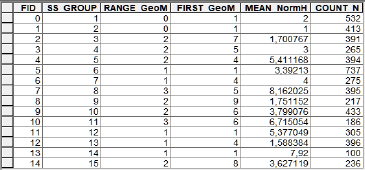
Для параметра нормализованной высоты логично вычислить среднее значение группы MEAN, а вот для десяти категорий мезорельефа (геоморфонов) «среднее» не имеет смысла, поэтому определяем диапазон RANGE чтобы представлять однородность значений в группе. Для общей ориентировки закажем еще FIRST (т.е., первое конкретное значение); тогда при минимальном 1 или нулевом значении диапазон, FIRST, по сути, и будет формой мезорельефа в данном кластере.
Рис. 19.19 Скриншот таблицы с характеристиками кластеров, полученными в результате Слияние (Dissolve)
Объединенная таблица дает нам возможность судить о типах локализации сельских населенных пунктов Ярославской области на рельефе. Так очевидно, что НП кластеров 1 и 2 находятся в самых низких местоположениях – на дне тектонически обусловленных лимно-аллювиальных котловин, при этом кластер 2 – это локальные превышения (супесчаные материковые дюны и гривы) озерных пойм и террас: достаточно характерные местоположения для всего региона Верхней Волги (число населенных пунктов - 532 и 413 соответственно). В совершенно иных условиях НП кластера 8, приуроченные к вершинам водоразделов с истоками рек; в данном классе наблюдается разнообразие форм мезорельефа (вершины и склоны холмов), в том числе – хорошо дренированные контрфорсы локальных склонов (мезоформа 5).
Кластеризацию, как мы уже знаем, можно провести и в SAGA GIS. Шейп точек Villige_points с извлеченными параметрами рельефа отправляем в Cluster Analysis (Shapes) (Table >> Calculus), опция combined method). Результат, полученный в SAGA GIS даже с тем же числом кластеров (9), будет несколько отличаться от Анализа Группирования в ArcMAP10.x, хотя мы легко сможем обнаружить здесь те же типы локализаций. Выбор инструмента, как обычно, остается за экспертом.
19.4. Поселения в ландшафте: моделирование расположения и параметров близости
Следующий блок моделирования – определение близости населенных пунктов к различным физико-географических объектам.
Сначала необходимо подготовить слои с выбранными для анализа объектами. Природные объекты, относительно которых будет измеряться расстояния, извлекаются (Select by attributes) запросом из таблиц соответствующих стандартных слоев карт OSM:
- леса из слоя vegetation-polygon.shp запросом "NATURAL"='wood’;
- болота из слоя water-polygon запросом "NATURAL"='wetland’;
- озера и водохранилища из слоя water-polygon запросом "NATURAL"='water’;
- реки из слоя water-line запросом "WATERWAY"='river' OR "WATERWAY"='stream’.
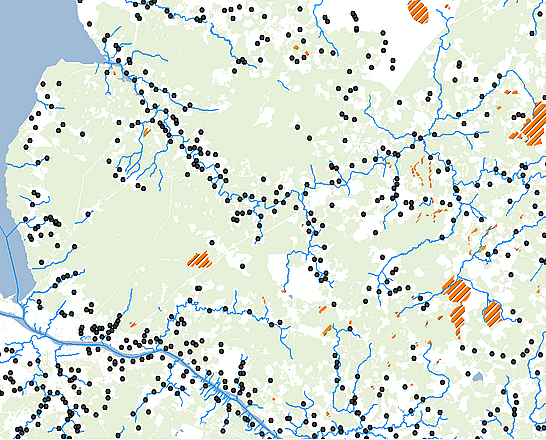
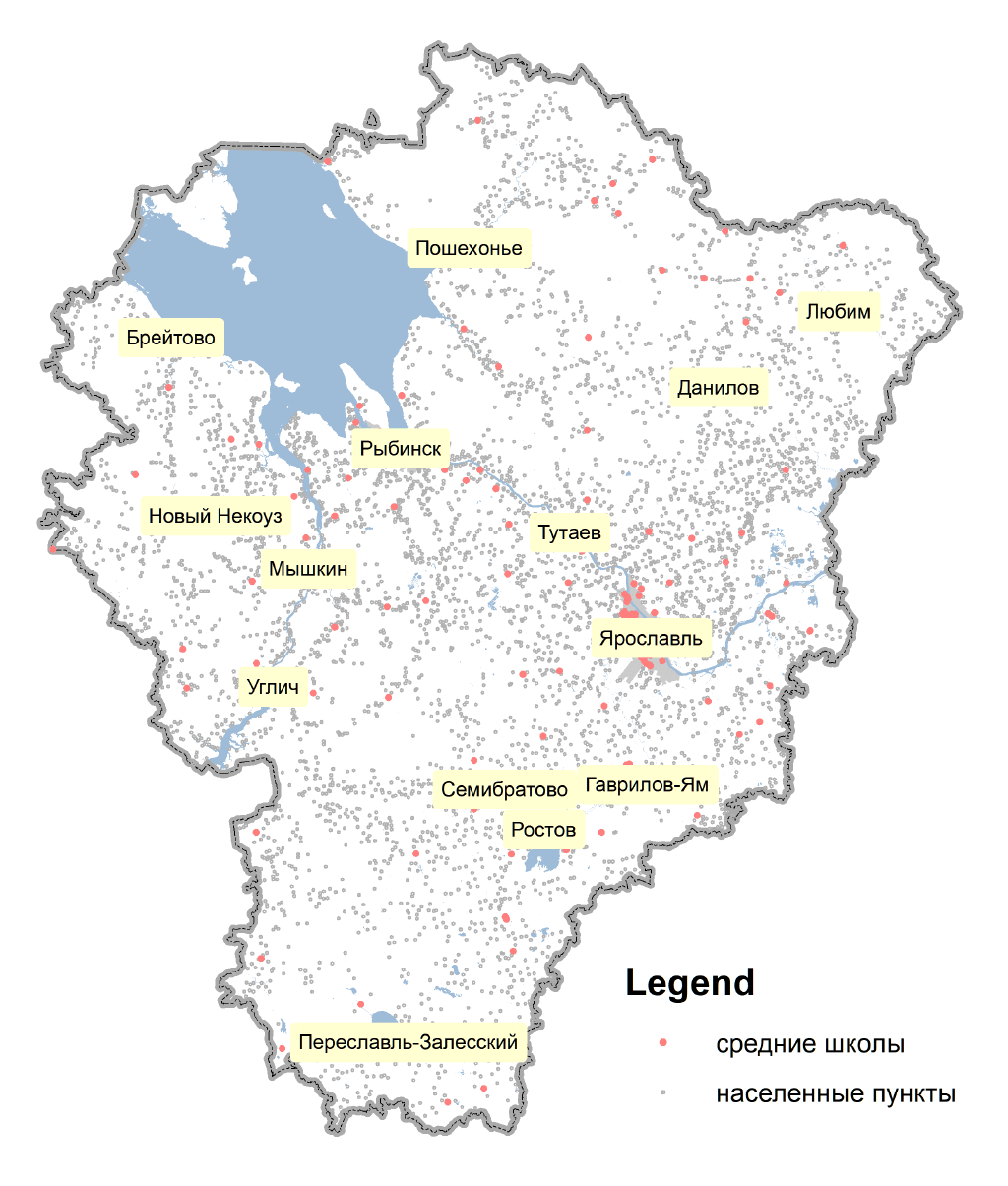
Рис. 19.20 Фрагменты исходных векторных слоев для анализа близости: реки, болота и центроиды населенных пунктов
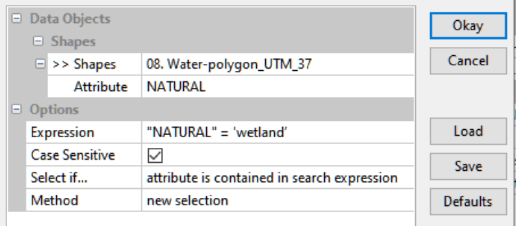
Создание новых слоев выборкой в SAGA GIS проводится аналогичными способом с помощью инструмента Select by String Expression (группа Shapes, набор Tools). Опции: Attribute, поле выбора – Expression|Выражение. Единственное отличие – выражение придется составлять самостоятельно без «подсказки», например: "NATURAL"='wetland’; синтаксис SQL работает и в SAGA GIS; важно выбрать опцию Select if... attribute is contained in search expression. Корректность выборки можно проверить открыв таблицу атрибутов слоя (Attributes >> Show).
Рис. 19.21 Выбор по атрибутам поля в ГИС SAGA
Следующее действие (после выборки): запуск инструмента Copy Selection to New Shapes Layer|Копировать Выборку в Слой из того же набора Tools с опцией Create|Создать слой. Образуется новый слой water-polygon [Selection], который необходимо переименовать (например, Wetland), используя диалог Setting поля Name и после этого сохранить. Не забывайте снять выборку в исходном слое (SAGA GIS не делает это автоматически) по правой кнопке мыши Edit >> Clear Selection.
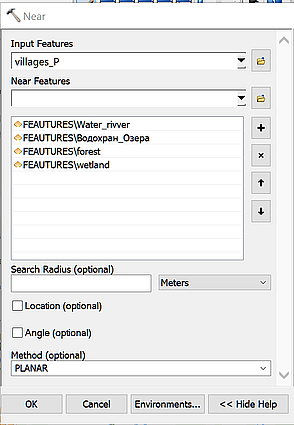
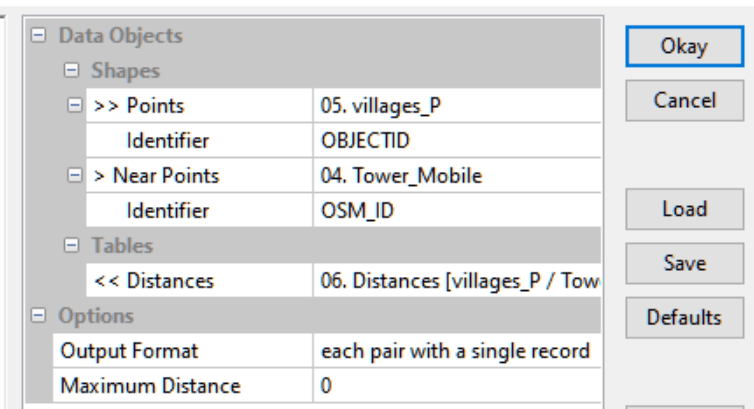
Определение близости относительно любых географических факторов, содержащихся в векторных слоях любого вида – точечных, полилинейных, полигональных - может быть произведено в ArcMAP10.x инструментом Near группы Proximity набора Analysis Tools; для полигонов в большинстве случаев справедливо измерять близость от центроида НП.
Рис. 19.22 Интерфейс инструмента Near в ArcMAP10.x
Инструмент Near лучше отработает с файлами Базы Данных поэтому имеет смысл сначала перевести шейп-файл утилитой Conversion в Feature Class to Geodatadbase. Запускаем инструмент Near – если в качестве объектов поместить в Near Features сразу все четыре слоя, то в выходном файле мы получим две колонки – тип ближайшего объекта и расстояние до этого объекта.
Рис. 19.23 Результат расчета близости по четырем слоям одновременно
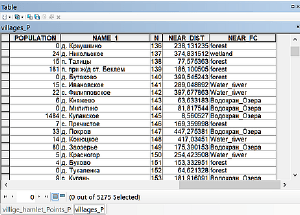
Если измерять расстояние до объектов одного слоя, то результатом работы инструмента NEAR является добавление двух колонок к исходной таблице населенных пунктов, в первой записывается FID ближайшего к данной точке (деревне) объекта-фактора (города, реки, леса), во второй колонке NEAR_Dist – расстояние до этого объекта.
Рис. 19.24 Результат расчета близости по единственному слою реки (полилинии)
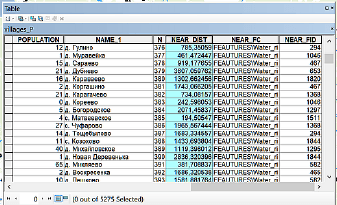
При каждом запуске алгоритма эти две строчки переписываются, поэтому для того, чтобы их сохранить лучше создать колонки с другим именем, введя в название полей имя фактора (например, RIVER_D) и перекопировать туда значения NEAR_DIST; заодно можно просто удалить ненужные поля (NEAR_FC и NEAR_FID, обозначающее идентификатор ближайшего объекта, например – реки).
Рис. 19.25 Измененная таблица близости рек
Социальные объекты, относительно которых мы должны измерить расстояния также извлекаются запросом из слоев карт OSM:
- города из слоя settlement-polygon.shp запросом select from WHERE "PLACE" IN ('city', 'town');
- дороги с твердым покрытием из слоя highway-line запросом select from WHERE "HIGHWAY" IN ('primary',
'primary_link', 'secondary', 'secondary_link', 'tertiary', 'tertiary_link', 'residential', 'trunk', 'trunk_link');
- железнодорожные станции и платформы - слой railway-platform-polygon;
- границы районов из слоя boundary-polygon запросом "ADMIN_LVL": ‘6’ и последующим превращением полигонов в полилинии (Data Management Tools >> Feature >> Feature To Line).
С помощью инструмента NEAR рассчитываем параметры близости поочередно для всех выбранных факторов, преобразуя полученные колонки значений как показано выше.
Результирующая таблица может выглядеть следующим образом (рис. 19.26)
Рис. 19.26 Результирующая таблица с извлеченными характеристиками расстояний от НП до ближайших объектов транспортной и социальной инфраструктуры
В SAGA GIS аналогичный инструмент определения расстояния до ближайшего объекта Point Distances принадлежит набору Points группы Shapes и работает только с векторными файлами точек. Чтобы получить значение минимального расстояния для каждой точки необходимо включить опцию Each pair with a single records. На выходе инструмента таблица с тремя значимыми полями: ID POINT - идентификатор точки базового слоя, ID NEAR - идентификатор точки объекта, до которого определяется расстояние, DiSTANCE – собственно расстояние.
Рис. 19.27 Диалоговое окно инструмента Point Distances SAGA
Далее алгоритм действий в SAGA GIS аналогичен описанному выше: оставляем два поля переименовав их понятным образом: идентификатор точки населенного пункта и расстояние до объекта, по полю ID привязываем таблицу к базовому файлу населенных пунктов утилитой Append Fields from another Table из набора Tools группы Table.
19.5. Кластеризация населенных пунктов по расположению
Для начала проведем Анализ Группирования (ArcMAP10.x) по близости населенных пунктов к природным и социально-инфраструктурным объектам, добавив к переменны близости два параметра рельефа. Определяем оптимальное число классов (без пространственных ограничений), оцениваем его с позиций здравого смысла и нашей интуиции: соглашаемся с предложенным числом классов или придумываем свое заветное число и затем получаем окончательный результат с новым значением.
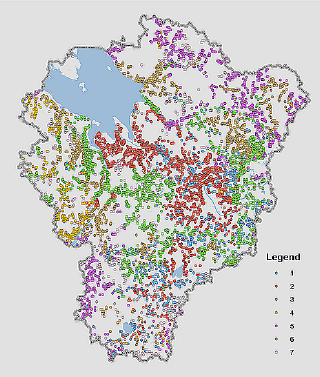
Полученные результат объединяем (DISSOLVE) но номеру кластера SS Group. При слиянии для параметра Типов рельефа|Geomorphones имеет смысл в качестве статистики использовать RANGE и FIRST. Проведенная таким образом кластеризация (в более привычном понимании - классификация) "выдает" семь неплохо интерпретируемых кластеров (Рис. 19.28).
Рис. 19.28 Итоговая типология населенных пунктов по совокупности природных и социальных факторов расположения
Первый класс (голубые пунсоны) - это прежде всего высоко расположенные НП (7,5 - среднее значение нормализованной высоты) в отдалении от рек, но при этом близко к водораздельным озерам и окружающим их, как правило, болотным массивам; далеко от городов, но в сравнительно неплохих транспортных условиях (автодороги и железнодорожные платформы).
Близок к первому седьмой класс (бледно-желтые пунсоны) тоже водораздельные населенные пункты, но уже расположенные на более низком уровне с усредненными прочими показателями.
Второй класс (красные пунсоны) – это в основном пригородные деревни (самая короткая средняя дистанция до центров) с наилучшим транспортным (близость к дорогам и ж/д платформам) положением, при этом находящиеся на низком уровне тектонически обусловленных низин (озерные и речные террасы) и, соответственно, близко к озерам и рекам.
Третий класс (зеленые пунсоны) выделились как «приречные» НП, разместившиеся вдоль средних и, частично, крупных рек (первая позиция близости) на низком топографическом уровне (Hnorm 2,9) в залесенных и плохо дренированных (близость к болотам) ареалах на периферии сельских районов.
Пятый класс (фиолетовые пунсоны) выделился по отдаленности от районных центров, максимальной отдаленности от автодорог и железнодорожных платформ, а также близости к границам районов, таким образом это населенные пункты своего рода "медвежьих углов".
Четвертый класс (желтые пунсоны) – это деревни на хорошо дренированных средневысотных водоразделах в аграрно освоенных ареалах, что определяется по максимальной дальности от лесов и болот.
Шестой класс (оливковые пунсоны) – могут быть отнесены к приречным, но при этом расположены на более высоком (Hnorm3,3) уровне унаследованных надпойменных речных и озерных (вдоль Рыбинского водохранилища) террас в залесенных местностях по близости от районных центров (следовательно – далеко от границ).
Таким образом, поскольку по меньшей мере пять из семи классов выделились по наличию двух ярко выраженных признаков (по которым они занимают первую или вторую позицию в соответствующих полях значений) классификация в цело можно считать удовлетворительной и подлежащей содержательной классификации.
19.6 Оценка веса и значимости факторов расположения
До сих пор мы исходили из предположения, что все рассматриваемые в модели факторы (независимые переменные) равны по влиянию на изучаемый феномен людности НП. Однако так ли это на самом деле? Разумеется, нет, поскольку навряд ли близость к железнодорожной платформе или к районному центру это равнозначные факторы. Вес факторов можно определять разными (совсем не обязательно - альтернативными) способами:
полагаясь на экспертное мнение и/или интуицию;
"взвешивая" факторы разными способами (обычно этот подход выливается в самостоятельное исследование);
изучая гистограммы или графики распределения каждого фактора в отдельности.
Последний способ (не предполагающий дополнительных исследований) может быть использован в нашем случае. Мы располагаем данными о близости каждого населенных пунктов региона к объектам, представляющим конкретный фактор (реке, озеру, районному центру и т.д.). Если классифицировать параметр близости, скажем, на пять классов способом естественные границы, то можно определить какой процент деревень попадает в первый класс. Далее логично предположить, что если в первый класс близости попадает существенная доля населенных пунктов, то этот фактор - значительный аттрактор.
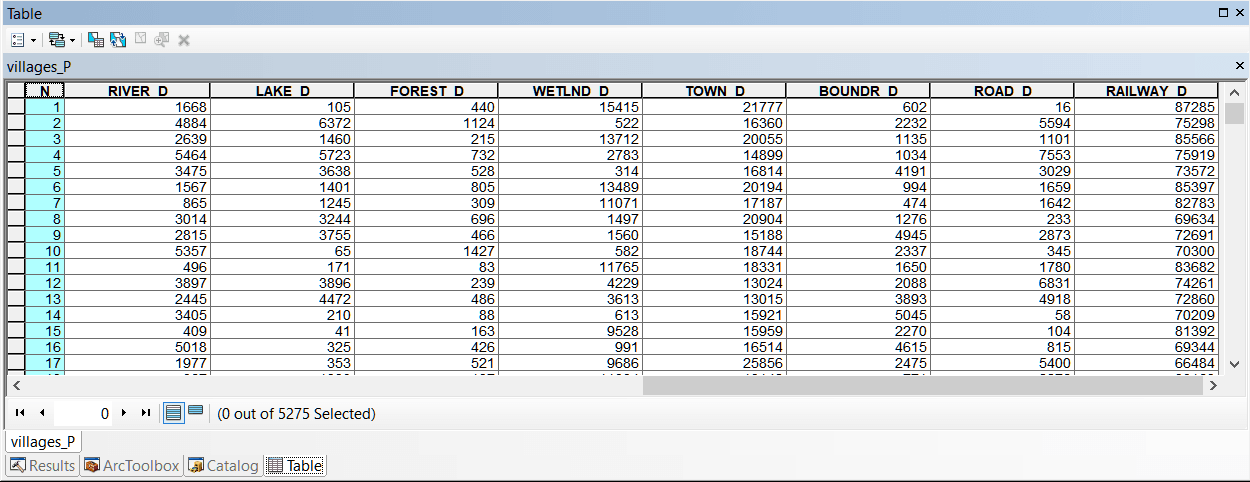
Посмотрим более внимательно на нашу базовую таблицу файла точек-центроидов населенных пунктов, содержащую поля расстояний до 8 различных типов природных и социально-инфраструктурных факторов (Рис. 19.29).
Рис. 19.29 Общий вид таблицы базового точечного слоя населенных пунктов с полями дистанций до различных объектов
Если классифицировать множество населенных пунктов по близости к рекам на пять классов, получится следующая гистограмма, фиксирующая граничные значения между классами (Рис. 19.30): 1-й класс - в пределах 802 м (от реки), 2-й класс - от 803 м до 1343 м, 3-й класс - от 1344 м до 2262 м, 4-й класс - от 2263 м до 3555 м, 5-й класс - от 3556 м до 8269м.
Рис. 19.30 Гистограмма распределения значений близости НП к малым и средним рекам
Таким образом можно получить представление о граничных значениях между классами близости/удаленности НП, далее можно произвести последовательную выборку каждого класса и вычислить долю (%) населенных пунктов, в каждом классе: чем выше доля объектов в первых двух классах близости к конкретному типу объектов (автодорога или река), тем большую роль играл этот тип в локализации сел и деревень.
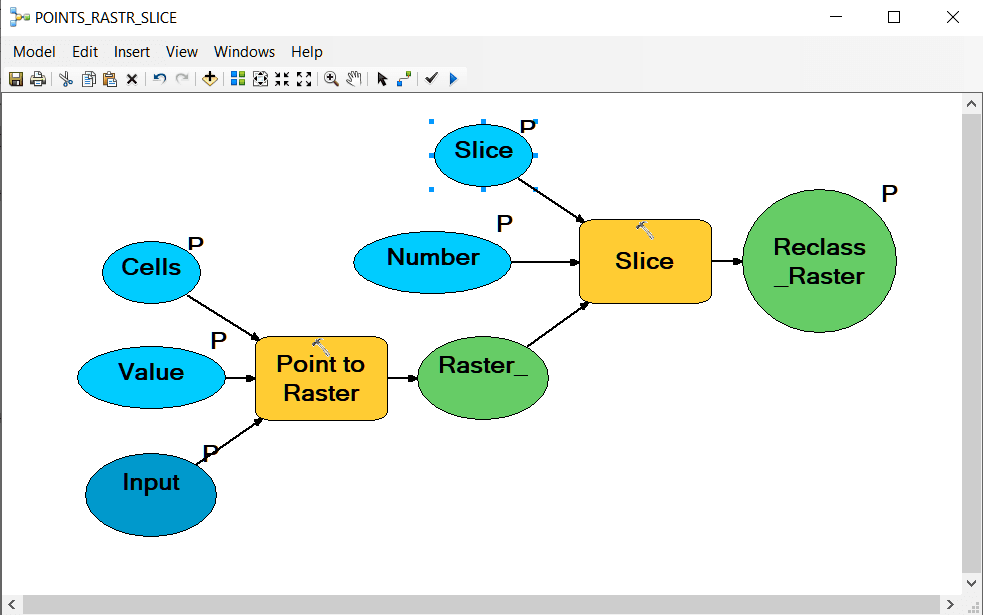
Возможно, наиболее простым способом определения "веса" признака является создание растров для каждого фактора близости с одновременной классификацией получаемых растров на пять классов способом natural breaks. Для экономии усилий составляем простенький "двухходовый"" алгоритм в Model BuilderArcMAP10.x:
Рис. 19.31 Структура модели для получения классифицированных растровых значений близости
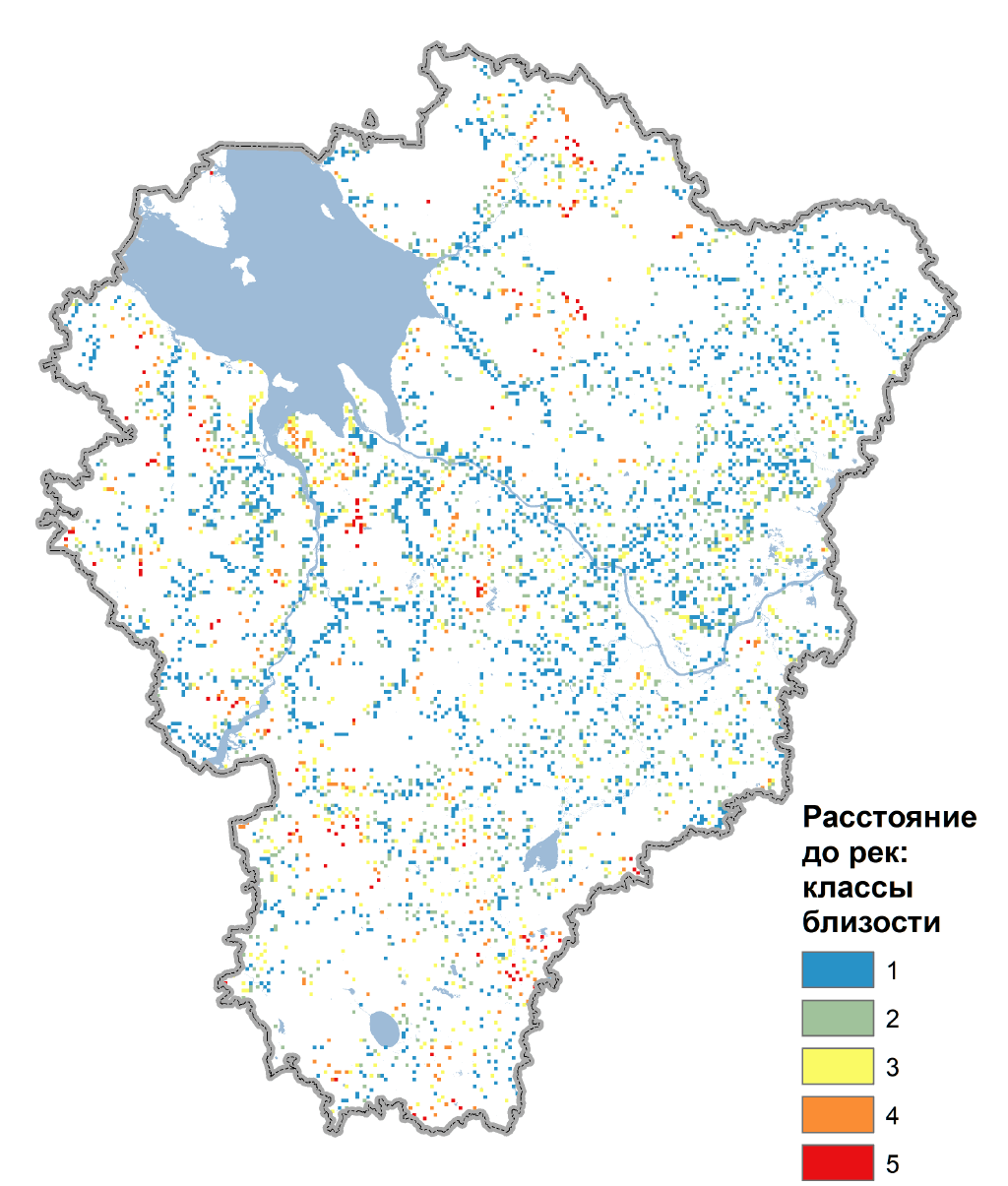
На вход инструмента Points to Raster подаем поочередно поля значений Value близости к объектам (рекам, лесам, дорогам и т.д.) базового файла центроидов НП. Опция Cell определяет размер ячейки растра - в нашем случае он может быть достаточно "грубым" (250 или даже 500) чтобы не увеличивать размер растра; далее полученный растр классифицируем на 5 таксонов инструментом Slice (Number - число классов, опция Slice определяет метод - здесь выбираем Natural Breaks; результат записываем как атрибутированный растр с соответствующим названием (например, River_D).
Рис. 19.32 Растровый слой пяти классов близости НП к малым и средним рекам
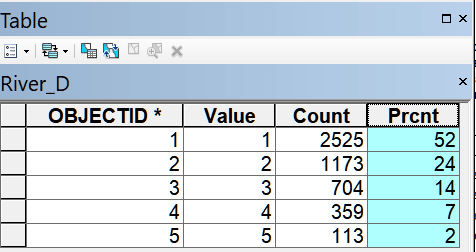
Теперь используя поле Count (предварительно скопировав статистку Summ) атрибутированного растра мы можем подсчитать в калькуляторе растра для специально введенного нового поля Prcnt сколько процентов попадает в каждый из классов близости:
[Count] / 5263 *100)
Рис. 19.33 Расчет доли (%) объектов, попадающих в различные классы близости для параметра расстояния до малых и средних рек
Очевидно, что в первые два класса близости к рекам попадают 76% (52% 1-й класс плюс 24% 2-й класс), что безусловно свидетельствует о существенном весе данного фактора. Теперь необходимо повторить эту процедуру (меняя только значение Value и имя выходного атрибутированного растра для остальных семи факторов. Сравним полученные таблицы долевого соотношения принадлежности к классам близости для разных факторов.
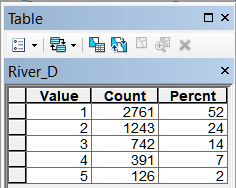
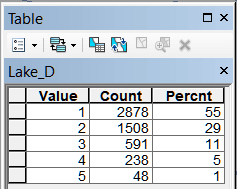
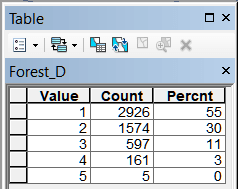
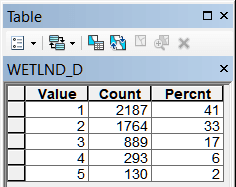
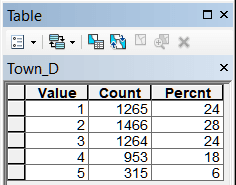
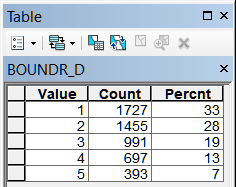
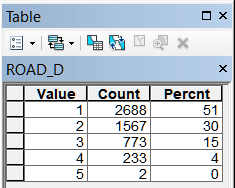
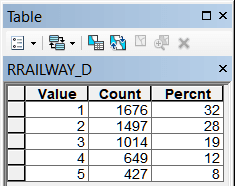
Рис. 19.34 Таблицы классов близости для различных объектов модели, слева-направо в верхнем ряду: River_D - расстояние до малых и средних рек, Lake_D - расстояние до крупных рек, озер и водохранилищ, Forest_D - до лесных массивов, Wetland_D - до болот; в нижнем ряду: Town_D - расстояние до города, BOUNDR_D - расстояние до границ района, ROAD_D - расстояние до автомобильных дорог с твердым покрытием, RAILWAY_D - расстояние до ж/д платформ
Легко заметить, что "сильными" аттракторами являются три из четырех природных (близость к малым и средним рекам, близость к крупным рекам, озерам и водохранилищам и близость к лесным массивам), для которых первые два класса охватывают более 75% всей совокупности сельских НП.
Близость к центру района и близость к границам района - это, по сути, два фактора антипода: иными словами, чем ближе к центру, тем одновременно дальше от границ. Кривая распределения для этих факторов сглажена и первые три класса почти равны между собой. То же относится и к расстоянию до железных дорог. Объяснить это обстоятельство можно разными причинами, но, в первую очередь тем, что возникновение большей части НП относятся к периоду, когда границы соответствующих административных образований были иными, и часть нынешних центров не выполняла соответствующих функций, поскольку уездов XIX века было почти вдвое меньше, чем нынешних районов.
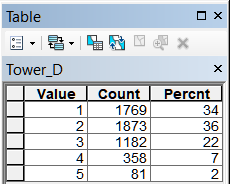
Для приближения состава модели к сегодняшней реальности пробуем добавить дополнительный фактор, который в нашем представлении может оказывать воздействие на людность населенных пунктов - расстояние до вышек сотовой связи. Используя слой poi-point набора OSM, выбираем вышки запросом Select By Atribut: "MAN_MADE": 'tower'. Далее по уже известному алгоритму определим расстояния от НП до вышек мобильной связи и дополним базовый слой villages_P еще одним полем Tower_D, по которому построим классифицированный на пять таксонов растр близости-удаленности (Рис. 19.35).
Рис. 19.35 Пять классов НП Ярославской области по близости к вышкам сотовой связи
Если "взвесить" этот фактор уже апробированным способом, то окажется, что он "безразличен" как бы сказали философы - вышки ставятся в основном не для удовлетворения потребностей жителей сельской местности, что подтверждается характером распределения - первый класс оказывается не самым многочисленным, и это при том, что абсолютные расстояния начиная с третьего класса (7615-2158 м) уже не обеспечивают надежного приема.
Рис. 19.36 Таблица классов классифицированного растра удаленности вышек сотовой связи
Наконец, рассчитаем еще один фактор, который не так просто извлечь из слоев OSM, поэтому он прилагается здесь уже в готовом виде - сеть образовательных учреждений (школ). Известно, что закрытие школ приводит к "отмиранию" сети населенных пунктов, по той простой причине, что молодые люди не видят перспективы для образования своих детей. В этой связи доступность школ давно уже стала важным фактором людности населенных пунктов. Определим расстояние до ближайшего образовательного учреждения, добавим это поле в базовый шейп НП и построим по полю School_D классифицированный растр близости.
Рис. 19.37 Один из дополнительных факторов модели - школы
19.7 Регрессионный анализ феномена людности сельских населенных пунктов
Итак зависимая переменная в нашей модели (т.е., - исследуемый феномен) - людность населенных пунктов, а факторы на него влияющие - независимые переменные или так называемые "предикторы" в количестве 11 выглядят следующим образом.
близость к малым и средним рекам;
близость к крупным рекам, озерам и водохранилищам;
близость к лесным массивам;
удаленность от ветлендов;
близость к малым и средним рекам;
удаленность от центров районов;
удаленность от границ районов;
близость к автомобильным дорогам с улучшенным покрытием;
близость к железнодорожным платформам;
удаленность от вышек мобильной связи;
близость к средним школам.
Мы располагаем также данными о положении населенного пункта на рельефе, которые можно включить в модель "просто из любопытства", хотя с позиции того, что называется common sense здесь не должно быть каких-то зависимостей, но - почему бы не попробовать, ведь за нас считает компьютер...
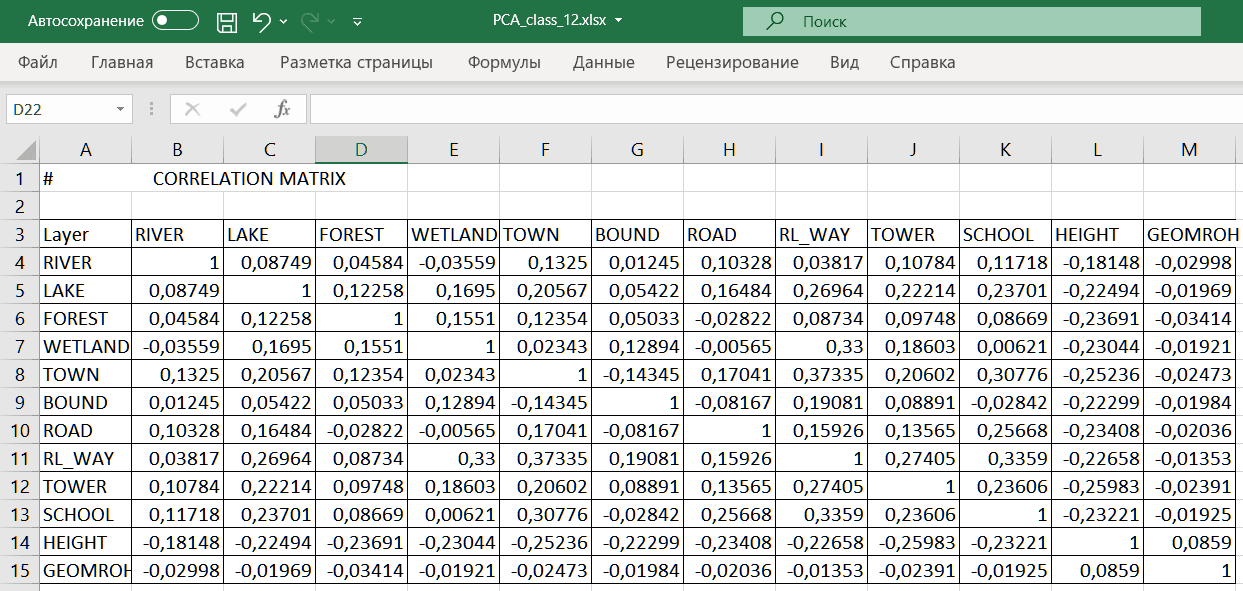
По идее Построение "объясняющей" регрессионной модели «феномен в многомерном пространстве факторов» должно предваряться проверкой совокупности предикторов на возможную корреляцию. Используем Principal Components Analysis|Метод Главных Компонент (Spatial Analyst >> Multivariate) пакета ArcMAP10.x для построения Correlation Matrix|Матрицы корреляции, показывающее возможные взаимосвязи между привлеченными переменными. Выходной композитный растр в нашем случае не будет представлять особого интереса, важнее содержание текстового TXT файла, в который записываются корреляционные и ковариационные матрицы, а также собственные векторы, процентная дисперсия, и накопительная дисперсия.
ArcMAP10.x выходные таблицы отображаются во вкладке List By Source >> Layer table |таблица слоев. Можно просмотреть файл через Блокнот просто нажав F4 на клавиатуре, но "сыром" виде файл мало информативен,
поэтому придется преобразовать его, скопировав и вставив в предварительно открытый лист Excel таблицу CORRELATION MATRIX. Все данные окажутся "смятыми" в одну колонку, чтобы их разделить, выделяем колонку с записями (если вы вставляли у левого края листа это будет колонка A, далее идем в Данные >> Текст по столбцам, в строке Укажите формат данных выбираем опцию фиксированной ширины, нажимаем Готово и таблица приобретает нормальный вид . Подглядывая в начало файла TXT, где наши переменные перечислены ровно в том порядке, в котором мы забрасывали их в "топку" PCA заменяем номера в строках и столбцах матрицы на факторы (Рис. 19.38).
Рис. 19.38 Преобразованная в формат Excel таблица CORRELATION MATRIX для 11 независимых переменных модели людности НП
В матрице корреляции связанными считаются переменные со значением коэффициента более 0,75; очевидно, что в нашей таблице таких пар факторов нет, сколь-нибудь значимую положительную связь демонстрируют только расстояния до железнодорожных платформ и до центров районов.
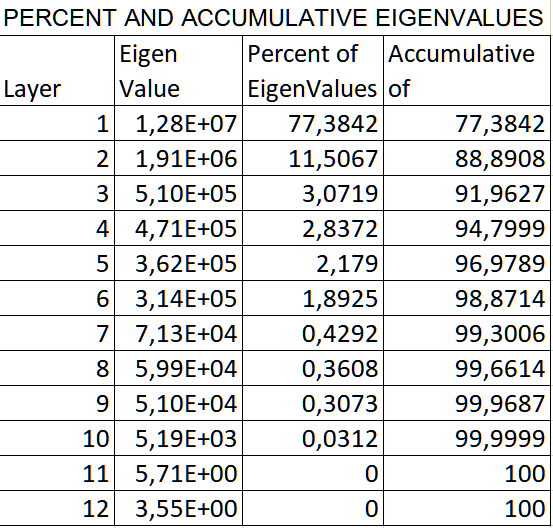
Обработаем в Excel подобным образом заключительную таблицу текстового файла отчета PCAPERCENT AND ACCUMULATIVE EIGENVALUES|Проценты и накопительные значения дисперсии - в зависимости от числа учтенных факторов.
Рис. 19.39 Преобразованная в формат Excel таблица PERCENT AND ACCUMULATIVE EIGENVALUES
Очевидно, что первые 5-6 переменных нашей модели определили 98% дисперсии, вспомним, что для этих же факторов характерно попадание более половины выборки населенных пунктов в первые два класса близости. Геоморфологические факторы мы можем оставить за пределами модели людности, они, что называется, "не про это"
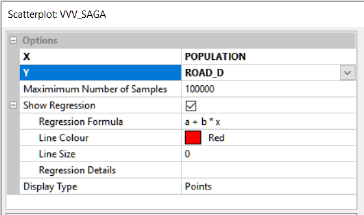
Мы можем также провести предварительную оценку эффективности регрессионного анализа между зависимой переменной и каждым предиктором используя прогнозный инструмент ГИС - scatterplot|точечные графики, который, на наш взгляд в SAGA GIS реализован наиболее удобным для пользователя образом, поскольку не просто визуализирует зависимости между двумя переменными, но и позволяет видеть вычисленное значение коэффициента детерминации R2, показывающего сколько процентов зависимой переменной может быть объяснено поведением "независимой переменной" в рамках модели линейной регрессии.
Загрузим в SAGA GIS базовый шейп village_p, далее в DATA подсветив название файла по правой кнопке мыши переходим: Attributes >> Scatterplot, выбираем интересующие нас переменные.
Рис. 19.40 Диалоговое окно инструмента Scatterplot в SAGA
Результат - наглядное изображение характера зависимости (линейная - нелинейная, простая - сложная, прямая - обратная).
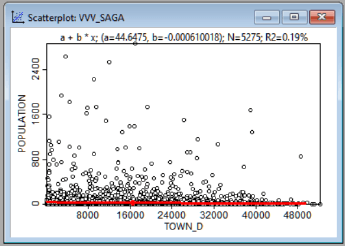
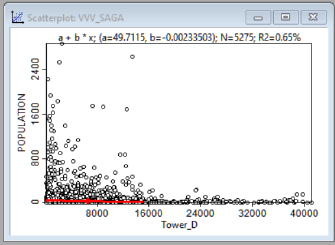
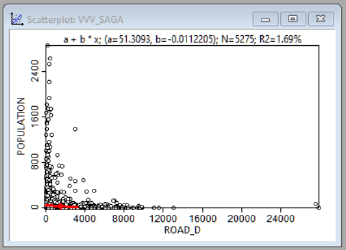
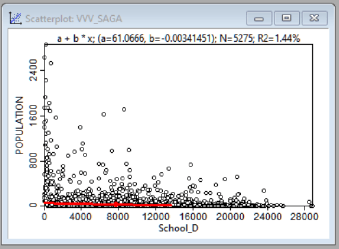
Рис. 19.41 Графики зависимости между людностью НП (population) и различными факторами, в верхнем ряду (слева-направо) - расстояние до центра муниципального района, расстояние до вышек сотовой связи; в нижнем ряду - расстояние до автодорог, расстояние до школы
Как можно судить по приведенным графикам зависимость между людностью НП и всеми четырьмя переменными имеет сложный характер (причем в случае с близостью к автодорогам и вышкам сотовой связи - явно нелинейный), кроме того значения коэффициента детерминации R2 ничтожно малы (в диапазоне от 0,19 до 1,69%: эти обстоятельства плохо совместимы с возможностью получения достоверной модели.
Целесообразно начать регрессионный анализ с использования инструмента Ordinary Least Squares|Метод наименьших квадратов, обеспечивающего своего рода диагностическую проверку нашей модели и отвечающему на вопрос "Найдены ли действительно важные переменные для объяснения изучаемого феномена", т.е., в нашем случае - насколько реально подходят привлеченные факторы для выявления причин заброса и запустения сельских населенных пунктов.
Предметом анализа OLS является базовый шейп-файл центроидов населенных пунктов village_P с полями значения близости-удаленности объектов факторов.
Input Id: ID *поле уникального идентификатора объектов (населенных пунктов),
Output File: место сохранения выходного файла "карты невязок",
Dependent Variables: Population *зависимые переменные в данной модели это число жителей НП,
Explanatory Variables: *объясняющие" независимые переменные-предикторы, 9 полей - LAKE_D, FOREST_D, WETLAND_D, TOWN_D, BOUNDR_D, ROAD_D, RAILVAY_D, TOWER_D, SCOOL_D,
Output Report File: - выходной файл отчета включающий диагностику модели, графики и примечания, которые позволяют интерпретировать результаты OLS.
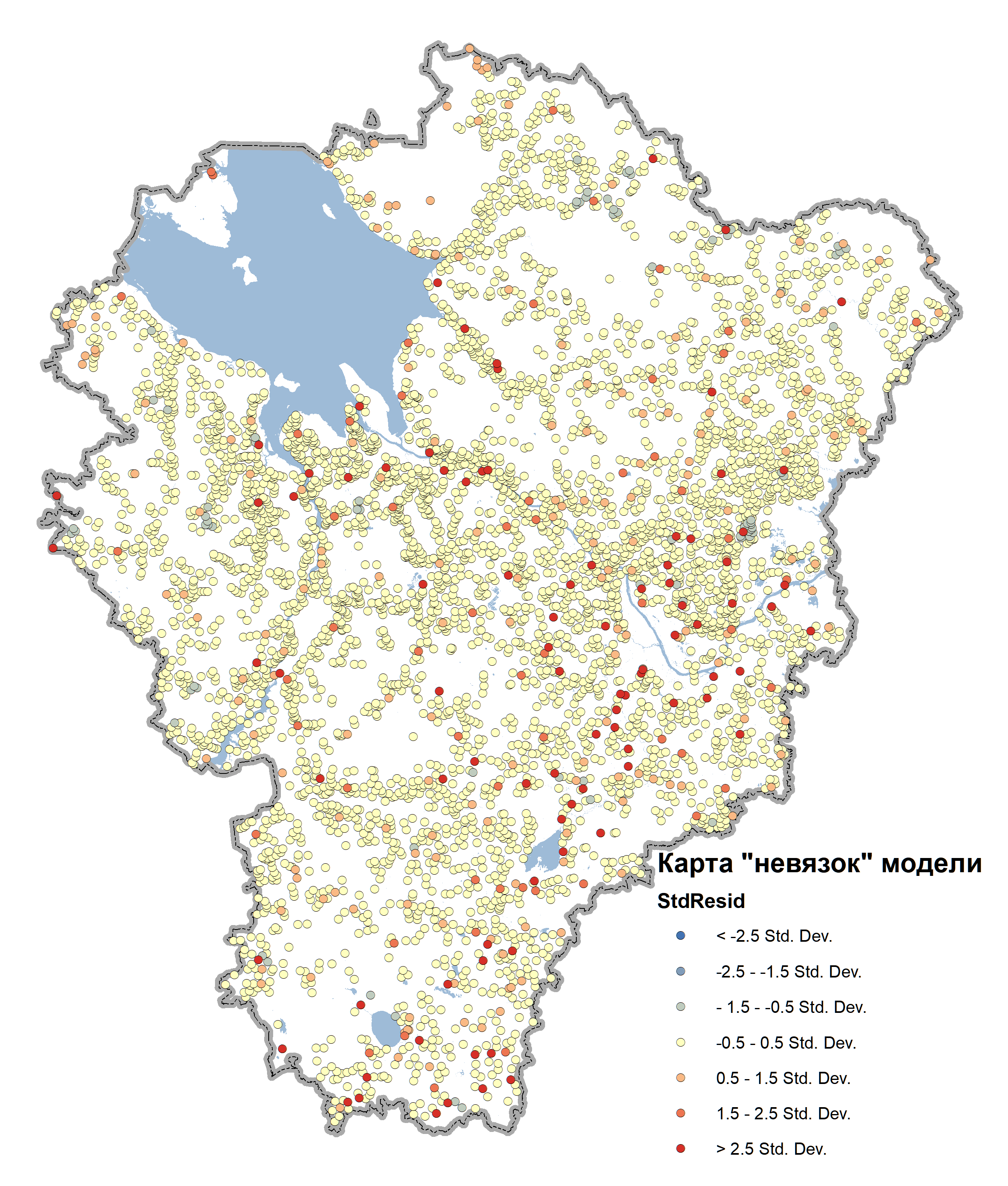
Стандартным результатом работы инструмента OLS является Карта невязок модели. Разработчики ArcMAP10.x в своем "идеальном мире" полагают, что "... иногда просто посмотрев на карту невязок, можно понять, какой переменной не достает" Справка по ArcMAP 10.5. Но на самом деле - это не так уж и просто.
Рис. 19.42 Карта невязок - выходной шейп инструмента Ordinary Least Squares в ArcMAP 10.x
Красные области – местоположения, где реальные значения (зависимые переменные) больше оцененных в модели, соответственно синие области – местоположения, где реальные значения меньше оцененных в модели. Судя по явному преобладанию желтых пунсонов невязок в нашей модели (т.е., пере- и недооценок по отношению к прогнозированию значений зависимой переменной - людности населенных пунктов) не так много. Далее обратимся к выходному файлу отчета, сохраненному в формате PDF.
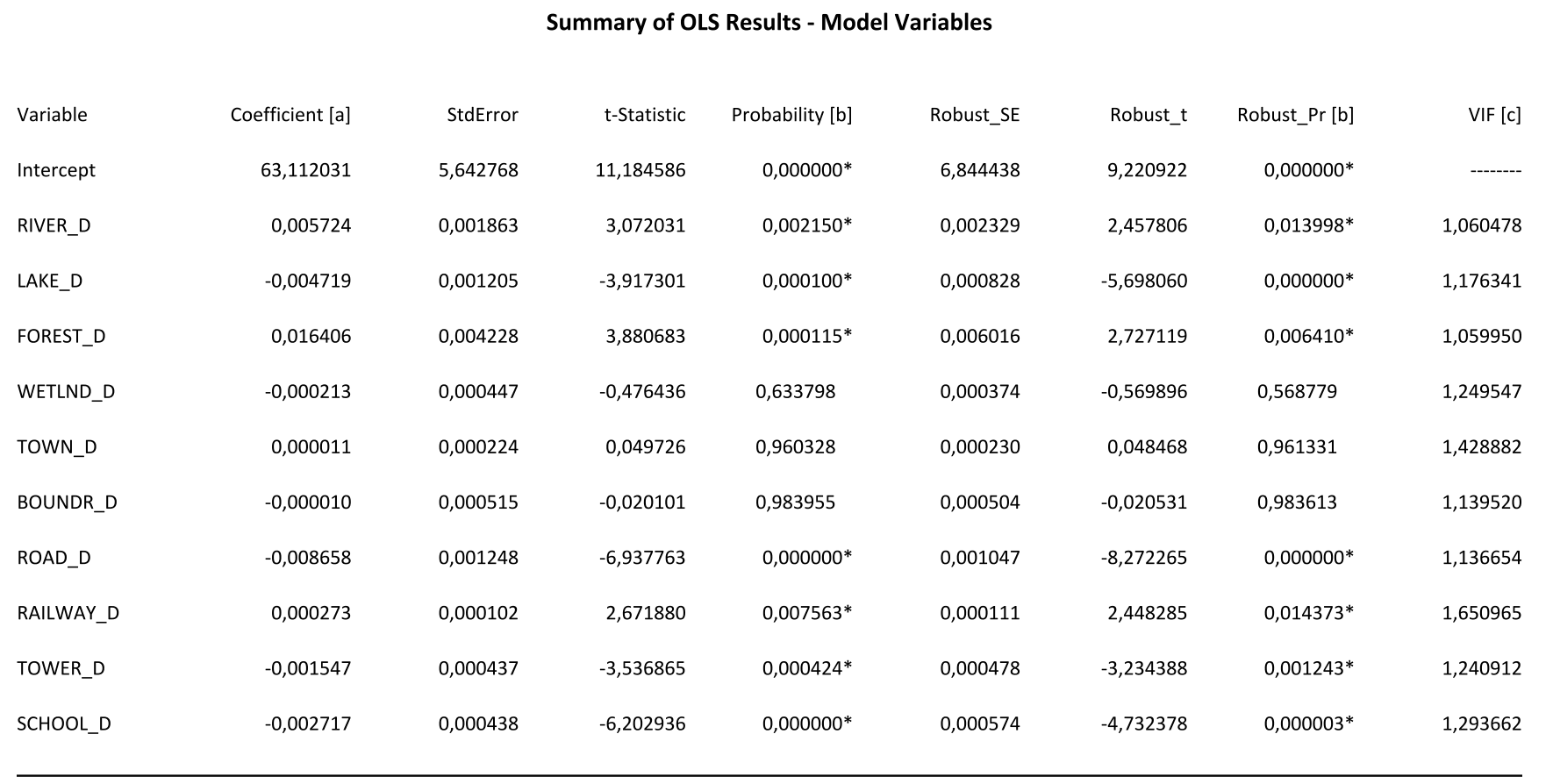
Отчет включает несколько таблиц. Первая таблица Summary of OLS Results - Model Variables содержит оценку роли и вклада каждой независимой переменной модели по восьми параметрам (Рис. 19.43).
Рис. 19.43 Скриншот таблицы Summary of OLS Results - Model Variables
Поле (столбец) Coefficient|Коэффициент отражает силу и тип отношений между предиктором и зависимой переменной. Не забываем, что в нашей модели расстояний большие значения метрик означают удаленность, а не близость - это важно для дальнейших рассуждений. Если значение положительно, связь между показателями прямая (в нашем случае это слабо выраженное отношение между людностью и удаленностью реки и леса). Если коэффициент отрицательный, то мы имеем дело с обратной связью (в данной таблице чем больше расстояние от дорог, вышек сотовой связи и школ, тем меньше людность населенных пунктов).
Поле t-Statistic - Тест T используется для оценки значимости факторов-переменных. Нулевая гипотеза означает, что для всех случаев коэффициент близок к нулю (и, соответственно, не подходит для моделирования). Данное поле рекомендуют анализировать совместно со следующим полем Probability [b]|Вероятности оценивающим статистическую значимость через устойчивую вероятность; такие значения помечены "звездочкой" (*). В нашей модели высокие значения t-Statistic (и звездочка Probability) "присвоены" (перечисляем в порядке величины) расстоянию от дорог (- 6,937763), расстоянию до школ (- 6,202936), расстоянию от вышек сотовой связи (- 3,536865) и расстоянию до крупных рек и водохранилищ (- 3,917301). Все значения - с отрицательным знаком, т.е., демонстрируют обратную связь - чем больше удаленность, тем ниже людность (и наоборот, близость объектов данного типа "работает" на увеличение людности). Из помеченных "звездочкой" положительных и значимых факторов - удаленность от малых и средних рек и лесных- массивов (т.е., чем дальше от малой реки и леса - тем больше людность. В эту же группу попадает, как ни странно - удаленность от железнодорожных платформ, возможно по той причине, что многие из них действительно удалены от крупных деревень и поселков (железная дорога как скоростная магистраль ведет себя "независимо", иначе бы она проходила прямо по деревенским "большакам").
Следующая таблица PDF-отчета - OLS Diagnostics|Оценка Значимости Модели содержит два показателя, Joint F-Statistic|Соединенная F-статистика и Joint Wald Statistic|Соединенная статистика Вальда, отвечающие за общую статистическую значимость модели.
Рис. 19.44 Таблица OLS Diagnostics|Оценка Значимости Модели
Соединенная F-статистика в данном случае может считаться значимой (18,740616) поскольку значок * имеет и показатель Статистика Кенкера (BP). Joint Wald Statistic|Соединенная статистика Вальда используется для определения общей значимости модели 120,19 при степени свободы - 10. Статистика Кенкера (BP) является в этом ряду едва ли не основной, поскольку если ее значения меньше статистически значимых (p < 0,01), то смоделированные отношения не являются последовательными (либо из-за нестационарности, либо из-за гетероскедастичности). Последний параметр этой таблицы - Статистика Жака-Бера (Jarque-Bera) показывает, являются ли невязки (полученные/известные зависимые переменные минус предсказанные/ожидаемые значения) нормально распределенными. В данном случае значение самого теста слишком велико 4098563, и, одновременно p-значение (вероятность) ничтожно мало и это значит, что модель смещена, а отношение между зависимой переменной и предикторами не являются линейными.
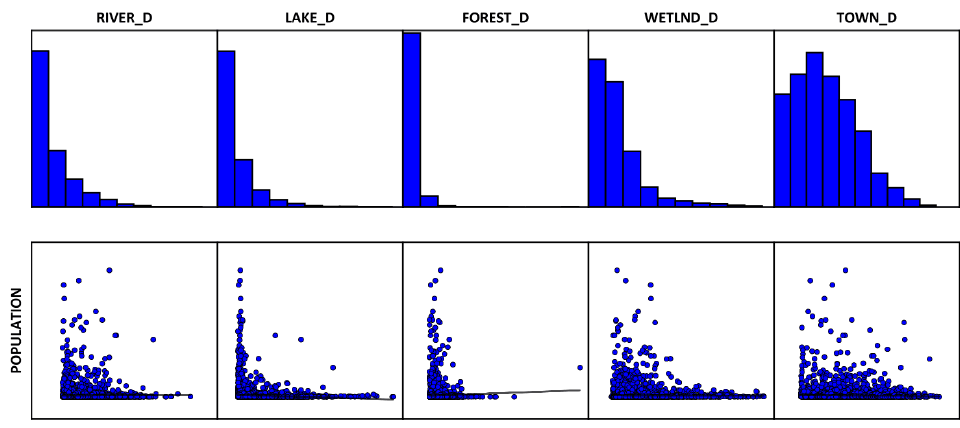
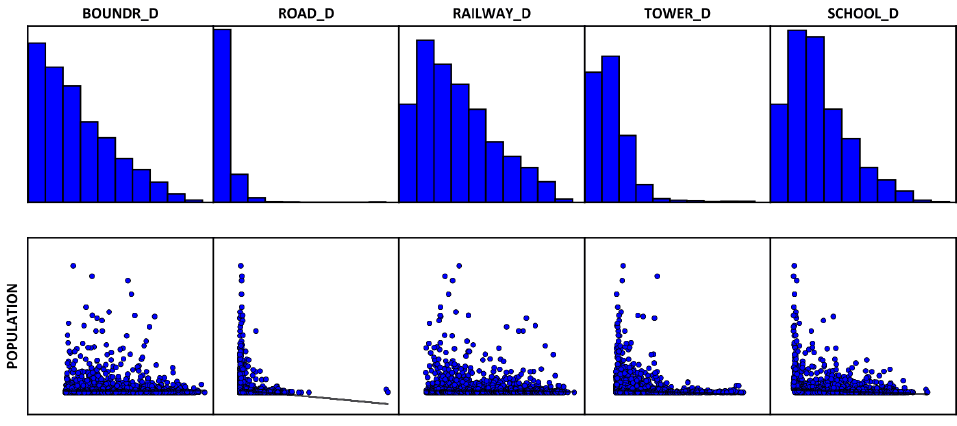
В третьем разделе выходного отчета приводятся графики, представляющие собой гистограммы и диаграммы рассеяния для каждой объясняющей переменной (фактора) и зависимой переменной. Гистограммы выполняют ту е функцию что и точечный график, полученный ранее в SAGA GIS и показывают, как распределяется каждая переменная. При это OLS не требует, чтобы переменные были нормально распределены.
Рис. 19.45 Гистограммы и диаграммы рассеяния для каждой объясняющей переменной модели, в верхнем ряду (слева-направо): малые и средние реки, крупные реки озера и водохранилища, леса, болота, города-райцентры; в нижнем ряду: границы районов, автодороги, ж/д платформы, вышки сотовой связи и средние школы
Каждая диаграмма рассеивания рассеяния отображает отношение между объясняющей переменной и зависимой переменной. Сильные связи проявляются в виде диагоналей и направления наклона указывает, является ли отношение положительным или отрицательным. Мы можем видеть, что важные (значимые) для нашей модели переменные (дороги, вышки сотовой связи, школы и районные центры центров) распределены нормально, хотя и со смещением. Наиболее значительная дисперсия значений свойственна паре переменных - расстоянию до центров и удаленности от границ района.
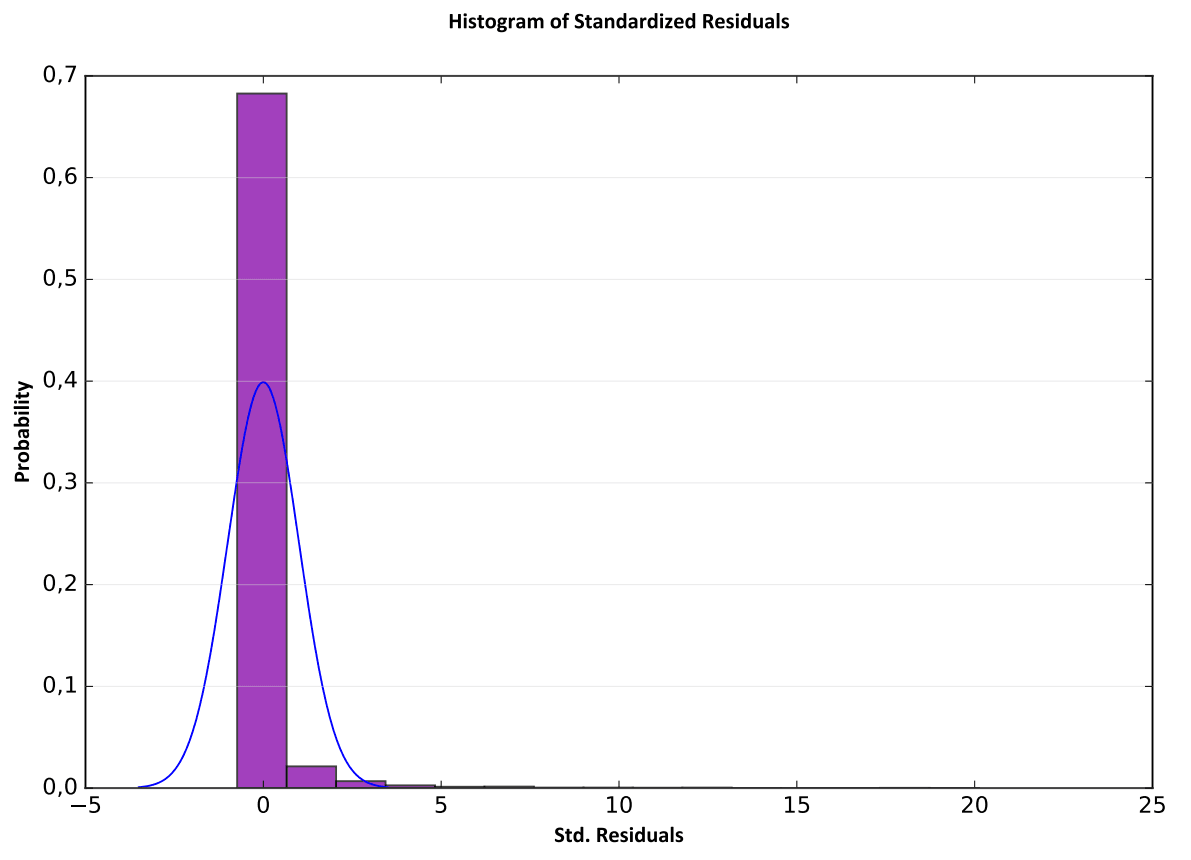
Четвертый раздел выходного файла отчета представляет гистограмму переоценок и недооценок модели. "Столбики" гистограммы отображают фактическое распределение, а тонкая линия вверху диаграммы показывает форму, которую приняла бы гистограмма, если остатки имели нормальное распределение.
Рис. 19.46 Гистограмма переоценок и недооценок модели
В идеале гистограмма остатков будет соответствовать нормальной кривой, обозначенной выше синим цветом. Если гистограмма выглядит очень непохожей на нормальную кривую, то модель может быть предвзятой. В данном случае мы получили достаточно достоверную модель с небольшим смещением в сторону положительных значений "переоценок".
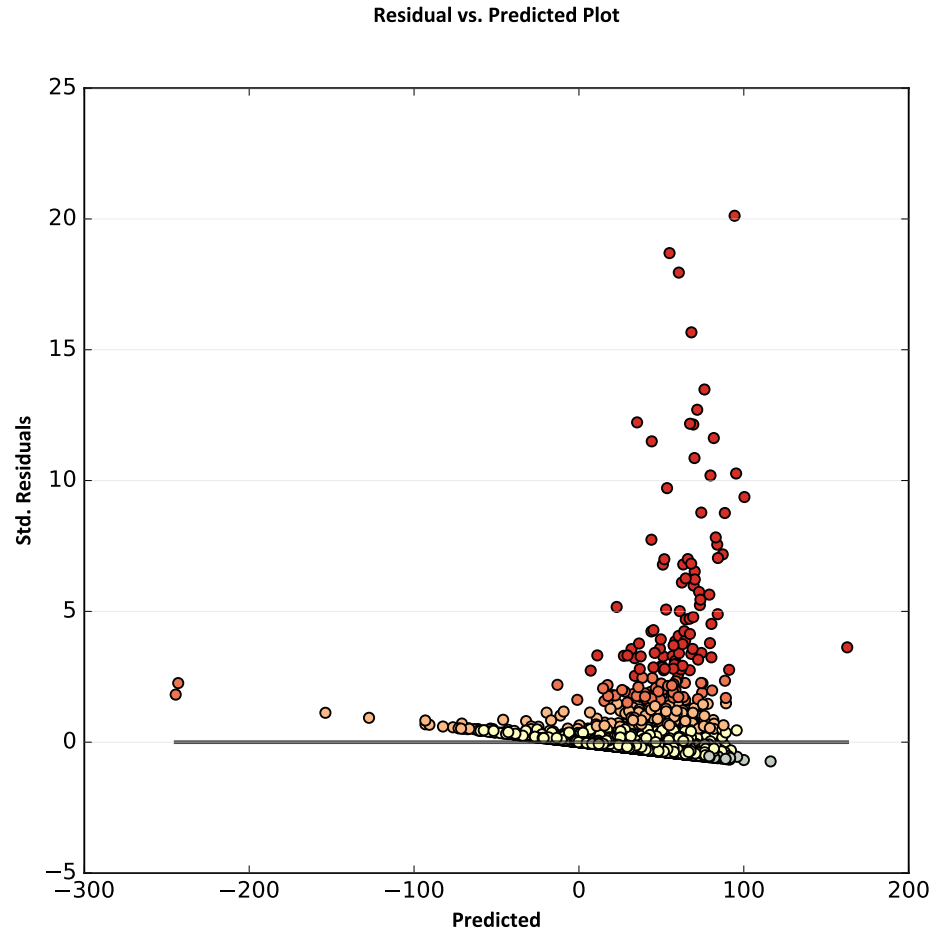
Заключительный пятый раздел отчета отвечает на вопрос имеются ли проблемы с зависимостью дисперсии от случайной величины. На диаграмме рассеивания показано отношение остаточных и прогнозируемых значений модели.
Рис. 19.47 Диаграмме рассеивания показывающая отношение остаточных и прогнозируемых значений модели
График невязок показывает распределение пере- и недооценок по отношению к предсказываемой зависимой переменной. Для хорошо специфицированной модели этот график должен представлять случайное распределение, однако в данном случае он имеет выраженную структуру, обнаруживающую присутствие "шаблона кривизны" в модели и это обстоятельство указывает нам, что действительно значимые факторы связаны с изучаемым феноменом нелинейно (см. например на диаграмму рассеивания для пары "людность-расстояние от автодорог".
SAGA GIS также располагает инструментами регрессионного анализа, причем в разных вариантах:
когда феномен и предикторы (факторы) - гриды;
когда феномен - шейп, а предикторы гриды;
когда и феномен, и предикторы - шейпы.
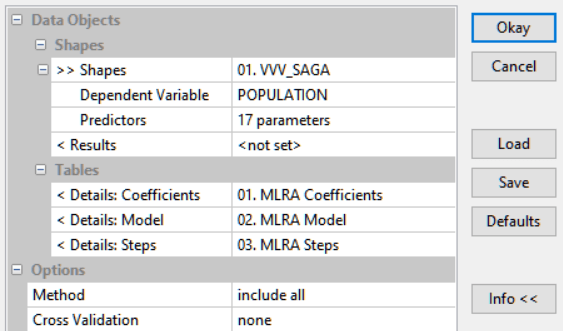
Для нашего файла векторных точек village_P с извлеченными значениями близости подходит инструмент Multiple Linear Regression Analysis (Shapes)|Множественный Линейный Регрессионный Анализ (Шейп-файлы); автор O.Conrad (2012). Из краткого описания следует, что это тот же (уже знакомый нам по ArcMAP10.x) Ordinary Least Squares|Метод наименьших квадратов. Диалоговое окно инструмента включает указание зависимой переменной (феномена) и параметров-предикторов. На выходе таблицы коэффициентов и модели. Опция Method|Метод, предлагает четыре варианта (include all, forwad, backward, stepwise - по умолчанию). Вторая опция Cross Vaslidation|Перекрестная верификация также предлагает 4 недокументированные варианта (none - по умолчанию, leave one out, 2-fold, k-means).
Рис. 19.48 Диалоговое окно инструмента Multiple Linear Regression Analysis SAGA
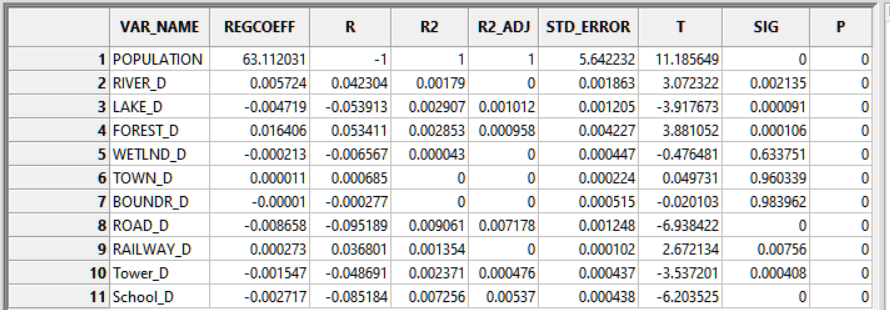
Таблица коэффициентов содержит колонки знакомых значений. Поле REGCOEFF соответствует полю Coefficient(i)PDF-отчетаArcMAP10.x, и мы обнаружим здесь практически те же значения для набора факторов-переменных. Поле T - значимость факторов также совпадает по значениям, полученным ранее с цифрами поля t-StatisticArcMAP10.x.
Рис. 19.49 Таблица результатов Multiple Linear Regression Analysis SAGA
Поле R представляет пере- и недооценки прогнозируемых значений. Коэффициент детерминации R2 и R2 ADJ (R-Squared и Adjusted R-Squared в ArcMAP) являются показателями производительности модели. Возможные значения варьируются от 0.0 до 1.0. Значение Скорректированного R-Квадрата всегда несколько ниже, нежели R-Квадрат поскольку отражает сложность модели (количество переменных), поэтому гораздо точнее отражает производительность модели. В данной модели значения R2 ADJ даже для тех факторов, которые обнаружили объяснимое влияние на людность НП крайне невысоки. Например значение R2 ADJ для фактора близости к средним школам (School_D) 0,0057 говорит о том, что данный фактор объясняет порядка 0,57% случаев поведения зависимой переменной. Таким образом SAGA GIS позволяет осуществить регрессионный анализ с практически аналогичными ArcMAP10.x результатами и параметрами оценок (хотя и более скромным дизайном).
19.8 Географически взвешенная регрессия
Подведем некоторые итоги. Мы выстраивали свою гипотетическую модель (или исследовательскую гипотезу) на основе так называемого "здравого смысла", а также исходя из наличных и общедоступных данных. Здравый смысл подсказывает нам, что людность населенных пунктов должна быть связана с близостью (или напротив) удаленностью сельского населенного пункта от некоторых природных (река, лес) или искусственных (город, дороги) объектов. Осуществленное нами "многотрудное" моделирование дало некоторые результаты, хотя, возможно, не столь содержательные, как нам бы того хотелось. К скромным достижениям нашей модели можно отнести следующие позиции:
Кластерный анализ населенных пунктов с использованием параметров близости к природным и искусственным объектом может быть неплохой основой для их классификации;
Метод анализ главных компонент позволяет выявить и "отбраковать"" взаимосвязанные переменные;
Выбранные нами для объяснения людности НП переменные обнаружили различную силу взаимосвязи с изучаемым явлением, часть из них оказалось "чуть-чуть" значимой, часть - "ничтожной";
Несмотря на низкую производительность модели выявлены два типа отношений между факторами и феноменом - прямая связь, когда увеличение дистанции приводит к увеличению числа жителей и обратная связь, когда с увеличением дистанции от объекта людность НП возрастает.
Всмотримся повнимательнее в предложенные нами факторы. Близость НП к реке или лесу могла играть существенную роль в средние века (на этапе возникновения села или деревни), и даже еще в конце XIX начале XX в., но позже с появлением транспорта этот фактор мог и не играть значительной роли и уж точно не определял критически людность деревни или села. В прошлом веке это число определялось функцией НП - наибольшее количество людей, как правило, проживало на так называемых центральных усадьбах и "отделениях" колхозов и совхозов, где находились основные производственные мощности (машинотракторные станции, зернохранилища, лесопилки, фермы), строилось новое жилье, осуществлялось бытовое обслуживание и создавались условия для обучения (школы, детские сады) подрастающего поколения.
Железнодорожные платформы были весьма важны для селян всю вторую половину прошлого века, но сегодня, они используются скорее дачниками, чем собственно сельскими жителями. Вышки сотовой связи не могут влиять на "людность", поскольку здесь причина перепутана со следствием: их устанавливают как раз там, где уже высока плотность населения, и этом смысле это не столько "предиктор", сколько "зависимая переменная".
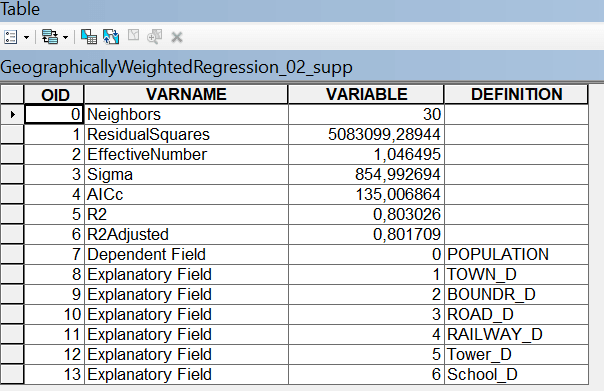
Автомобильные дороги играли и продолжают играть существенную роль в системе сельского расселения (определяя, например доступность тех же школ), но в наше время при широком распространении личного автотранспорта люди склонны выбирать не столько ближайшую, сколько более перспективную школу, тем самым "ослабляя" значимость фактора расстояний. С другой стороны, наличие автомобильных трасс напрямую определяет возможности доставки сельскохозяйственной продукции на городские рынки. Следовательно, есть смысл попытаться оптимизировать модель, после верификации пространственной автокорреляции применить инструмент Географически взвешенной регрессии|Geographical Weighted Regression.
Результаты географически взвешенной регрессии значительно отличаются от обычной регрессии в отношении эффективности модели. Коэффициент детерминации R2 увеличился до 0,8 и это означает, что приблизительно 80% феномена людности определяются выбранным набором факторов с учетом пространственной неоднородности их распределений. Тем не менее данная модель не слишком состоятельна, и прежде всего потому, что взаимосвязи между феноменом и наиболее влиятельными предикторами, очевидно, не имеют линейного характера. Кроме того полученный результат стимулирует нас искать другие факторы. Например, можно предположить, что людность НП связана с наличием работы, каковая, в свою очередь зависит от сохранения или развития производственных функций. Тогда в качестве параметров можно было привлечь такие факторы как наличие и численность предприятий агрокомплекса, сохранность и площадь сельскохозяйственных угодий (полей, пастбищ). К сожалению, эти факторы не "лежат на поверхности", и, чтобы их получить, надо осуществить настоящую "добычу данных", используя административный ресурс.
Заметим также, что некоторые факторы могут потребовать другого представления в рамках модели. Так, для сельскохозяйственных угодий будет важным не "расстояние до ближайшего поля", а скорее общая площадь в пределах окрестностей (размер которых придется специально определять). Собственно, и те факторы, которые мы использовали, могли быть "приготовлены" иначе: вполне возможно, что для учета фактора транспортной доступности полезнее было оценивать доступность в интервалах времени (получасовая, часовая и т.д.).
Все эти соображения убеждают нас в том, что моделирование - итерационный процесс, и это значит, что практически никогда невозможно получить сразу модель, достоверно и корректно объясняющую интересующее нас явление. Но поскольку наличие прозрачного и воспроизводимого алгоритма - одно из неотъемлемых свойств ГИС-моделирования - каждый шаг, каждая итерация будут приближать нас к желаемому результату.




{kind=link}
{kind=link}