I. ГЕОМОРФОМЕТРИЯ И СОВРЕМЕННЫЕ ПОДХОДЫ К ЛАНДШАФТНОМУ СИНТЕЗУ
15. ВОЗМОЖНОСТИ СИНТЕЗА БИОТЫ С МОРФОДИНАМИЧЕСКОЙ ОСНОВОЙ ЛАНДШАФТА
15.1. Объектно-ориентированная классификация изображений для выявления состояний ландшафта
Если цифровые модели рельефа используются для определения и делимитации мезоформ рельефа (и, следовательно - морфодинамической основы ландшафта), то космические снимки различных сенсоров (Landsat, Modis, Sentinel) служат для выделения различных типов природных и/или культурных ландшафтов а также видов землепользования, что как раз и соответствует англоязычному словосочетанию Landuse|Landcover, зачастую заменяемому (особенно в работах, посвященных геоинформационному моделированию) более привычным Landcover. Заметим, что попытки перевода этого термина на русский как "ландшафтный покров" или "ландшафтно-земельный покров" стилистически не вполне удобоваримы и поэтому вызывают острые возражения особенно у представителей школы классического российского ландшафтоведения. В этом смысле на современные гис-технологии лучше проецируются представления ленинградской школы ландшафтоведения, в рамках которых морфодинамическая основа ландшафтов определяется как "ландшафтные местоположения", а инварианты биоты и землепользования считаются "состояниями ландшафта" [Исаченко, Резников, 1996; Исаченко, 1999]. С этих позиций можно полагать, что, классифицируя космические снимки мы определяем типы (или виды) состояний ландшафтов.
Для демонстрации методов классификации изображений с выделением состояний ландшафтов, а также для характеристики современных подходов к синтезу ландшафтных местоположений и ландшафтных состояний воспользуемся всей той же "сценой" - территорией Приэльбрусья (верховья реки Баксан), что позволит нам сравнить традиционные способы ландшафтного картографирования с современными алгоритмами полуавтоматизированного гис-моделирования.
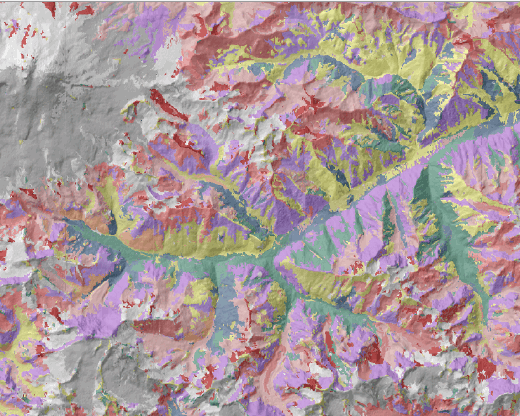
Для определения числа классов ориентируемся на существующую ландшафтную карту национального парка "Приэльбрусье" (составленную А.Н.Гуней и М.Н.Петрушиной традиционным способом), в которой выделены 5 типов и 13 подтипов ландшафтов [Колбовский, Гуня, Петрушина, 2022] (Рис. 15.1).
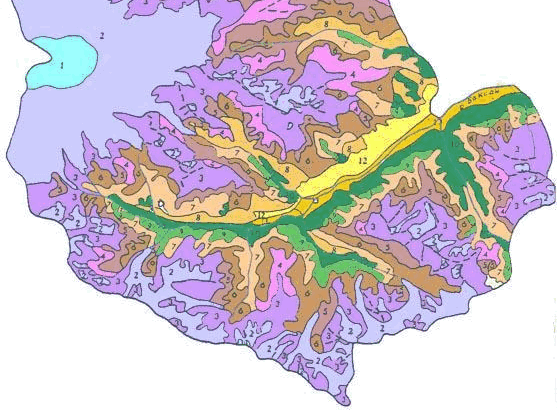
Рис. 15.1 Ландшафтная карта (авторы А.Н.Гуня, М.Н.Петрушина)
Таблица 15.1 Типы и подтипы ландшафтов национального парка "Приэльбрусье"
| № | Типы и подтипы ландшафтов | Критерии выделения при экспертном ручном картографировании | |
|---|---|---|---|
| Морфолитогенная основа | Типы растительности и современное землепользование | ||
| 1 | Нивально-гляциальные | Выше 3500 (в отдельных случаях на склонах северной экспозиции — выше 3200) | Снег, лед без следов использования |
| 1.1 | Ледниковые Снежно-ледниковые | Более 4500 м | Снег, лед без следов использования, господство отрицательных температур |
| 1.2 | Снежно-фирново-ледниковые | На абсолютных высотах 3500 — 4500 м | Снег, лед без следов использования, небольшой период с максимальными положительными температурами |
| 1.3 | Скально-снежные, с фрагментарным развитием накипных лишайников | Выше 3500 м (в отдельных случаях на склонах северной экспозиции — выше 3200) | Нет сплошного снега и льда, скально-снежные участки на летних снимках, все еще зона минимальных среднесуточных температур |
| 2 | Горно-луговые | с 2000 м до границы нивально-гляциальных ландшафтов | Задернованность и вегетация, отмечаемая на летних снимках |
| 2.1 | Субнивальные | 3000 (3100) — 3500 м | Проективное покрытие около 10-20%, как правило, не используемые |
| 2.2 | Лугово-тундровые | 2900 — 3100 м | Проективное покрытие 20-50%, как правило, не используемые |
| 2.3 | Альпийские | 2700 — 2900 м | Проективное покрытие 50-75%, как правило, редко используемые в качестве летних пастбищ |
| 2.4 | Субальпийские | 2400 — 2700 м | Проективное покрытие более 75%, летние пастбища, реже — сенокосы |
| 2.5 | Остепненные | Склоны южной экспозиции, 2000 (1900) — 2400 м | Проективное покрытие более 75%, сезонные пастбища, реже — сенокосы |
| 3 | Горно-лесные | До 2400 (2500) м, в основном, на склонах северной экспозиции | Лесная растительность разной степени сомкнутости |
| 3.1 | Мелколиственно-криволесные | Как правило, склоны северной экспозиции 2300 - 2500 м | Березовые криволесья, куртинами, не используются |
| 3.2 | Мелколиственно-хвойные | до 2300 м, склоны северной экспозиции, днище долины, реже –склоны южной экспозиции | Сосновые леса с примесью березы, использование по днищам долин для рекреации |
| 3.3 | Мелколиственные | Ущелья р. Малки и ее притоков | Березовые мелколесья, не используются |
| 4 | Горно-степные | Склоны южной экспозиции до 1900 м | Степи с пятнами можжевельника, проективное покрытие около 40-60%, используются под круглогодичный выпас |
| 4.1 | Кустарниковые | Склоны южной экспозиции до 1900 м | Степи с пятнами можжевельника, проективное покрытие около 40-60%, используются под круглогодичный выпас |
| 5 | Горно-лугово-степные | Днище долины ниже 1800 м | Окультуренный ландшафт: селитьба, поливные сенокосы |
Таким образом, число классов в данном случае может быть принято равным 13-14.
Классификация изображений в геоэкологии - это процесс группировки пикселей изображения в классы, относящиеся к фрагментам природных и культурных ландшафтов и/или видам землепользования. Методы классификации могут также использоваться для мониторинга изменений окружающей среды, таких как формирование ареалов сплошных рубок или районов, пострадавших от пожаров. На практике получили распространение две основные формы классификации: 1) классификация на основе пикселей и 2) классификация на основе объектов.
Классификация на основе пикселей рассматривает спектральный отклик или цифровые "подписи" для каждого пикселя и использует один из математических методов, назначающих их в класс. Существует две группы методов, с помощью которых классы пикселей могут быть назначены; unsupervised|неконтролируемые и supervised|контролируемые классификации.
В неконтролируемой классификации классы могут быть присвоены автоматически на основе алгоритма группировки. Как правило, единственными определяемыми пользователем входными данными в этом процессе являются каналы|band космического снимка, которые используются в процессе назначения классов, а основной опцией - количество выходных классов LandUse/LandCover. Наиболее распространенным, но далеко не единственным алгоритмом неконтролируемой классификацией является кластерный анализ и его различные инварианты.
В отличие от этого контролируемая классификация или классификация с обучением требует от пользователя определения тренировочных (их еще называют "затравочными") участков известного типа LULC (ландшафтно-землепользовательского покрова). Пиксели затем группируются в классы на основе спектральных данных пикселей тренировочного участка. Алгоритмы подобного рода считаются быстрыми и эффективными; однако они могут приводить к ошибкам, которые трудно корректировать.
Существуют так называемые Object-based classification|Объектно-ориентированные классификации, которые вместо того, чтобы рассматривать отдельные пиксели группирует их в области ("сегменты") с аналогичными спектральными свойствами, и поэтому весь процесс именуется сегментацией. Затем эти объекты могут быть классифицированы с использованием неконтролируемых или контролируемых методов. Объектно-ориентированная классификация предоставляет возможности более гибко редактировать классифицированные области и позволяет использовать более сложные методы, включающие форму сегмента и контекст.
Алгоритм Объектно-ориентированной классификации, снимков серии Landsat обычно включает пять последовательных действий:
Шаг 2: Вырезание интересующей области,
Шаг 3: Определение числа конечных классов,
Шаг 4: Запуск сегментации изображения,
Шаг 5: Оценка результатов,
Шаг 5: Вычисление площадей.
Выбор комбинации каналов - один из самых важных шагов в этой последовательности, поскольку различные типы природных ландшафтов и виды землепользования, а также просто разные виды объектов по-разному отображаются в сочетаниях каналов. Подбор, как правило, осуществляется с опорой на уже имеющийся (и описанный в литературе) опыт, но адаптация и регионализация любого опыта под конкретную задачу, разумеется, предполагают готовность пользователя продвигаться итерационно - многотрудным методом "проб и ошибок". Кроме того в сложных случаях не исключена вероятность, когда одни "сущности" (например, типы лесов) будут определяться по одному композиту, а другие (например, виды сельскохозяйственных угодий) - по-другому. Для начала используем "популярный" композит Landsat 8 NIR-Red-Green (5-4-3) на территорию Приэльбрусья (Рис. 15.2).

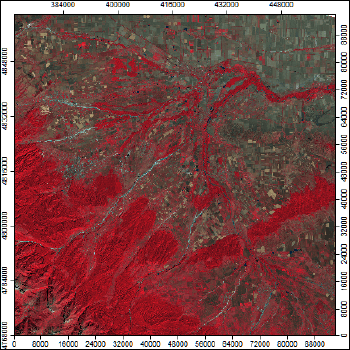
Рис. 15.2 Композит NIR-Red-Green (5-4-3) в искусственных цветах: а) горный район, b) предгорье и освоенная равнина
Выберем для сегментации горную часть сцены, для которой мы располагаем ландшафтной картой. Для этого просто центрируем необходимую область в окне карты SAGA GIS используя инструменты Zoom и Pan. Быстрое вырезание в окне карты SAGA GIS производится инструментом Clip Grid (Interactive) набора Grid группы Grid System. После запуска инструмента "стрелкой" Action обводим прямоугольником видимую область; открывается диалоговое окно с параметрами выбранного фрагмента, если результат устраивает -
Три вырезанных области трех каналов появятся в Новой Системе Грида (поскольку размеры растра были изменены). Исходные слои можно отключить из просмотра, а вновь полученные - сохранить в проекте SAGA GIS.
Используем инструмент Object Based Image Segmentation набора Segmentation группы Imagery. Эта цепочка инструментов сегментации изображений на основе объектов объединяет ряд алгоритмов для удобного вывода геообъектов в виде полигонов и обычно применяется к спутниковым снимкам. Сегментация выполняется способом Seeded Region Growing Algorithm|Наращивание посевной области [Adams, Bischof, 1994; Bechtelf et all,2008].
Инструмент Object Based Image Segmentation имеет сравнительно простой интерфейс; к выбираемым опциям относятся Band Width for Seed Points|Ширина полосы "посева" рандомных точек - чем крупнее масштаб, тем, по-видимому, меньше должна быть величина, по идее большее значение должно привести к более крупным контурам. В позиции Post Procession (способ обработки) выбираем Unsupervised Classification|Неконтролируемая Классификация. В позиции Number of Classes|Число Классов указываем 14. Флажок с опции split clusters можно снять.
Data Objects
Grid Systems: ...
>> Features: 3 objects (Landsat 8 NIR-5, Red-4, Green-3)
Normalise: (оставляем пустым)
Shapes
<< Segments: create
Options
Band Width For Seeds Points Generations: 10
Distance: features space and position
Variance in Features Space: 1
Variance in Position: 1
Similarity Threshold: 0
Generalisation: 1
Post-Processing: unsupervised classification
Number of Clusters: 14
Split Clusters: (оставляем пустым)
Появившийся векторный полигональный слой Segments добавляем к карте и раскрашиваем по 14 классам Graduated Color.
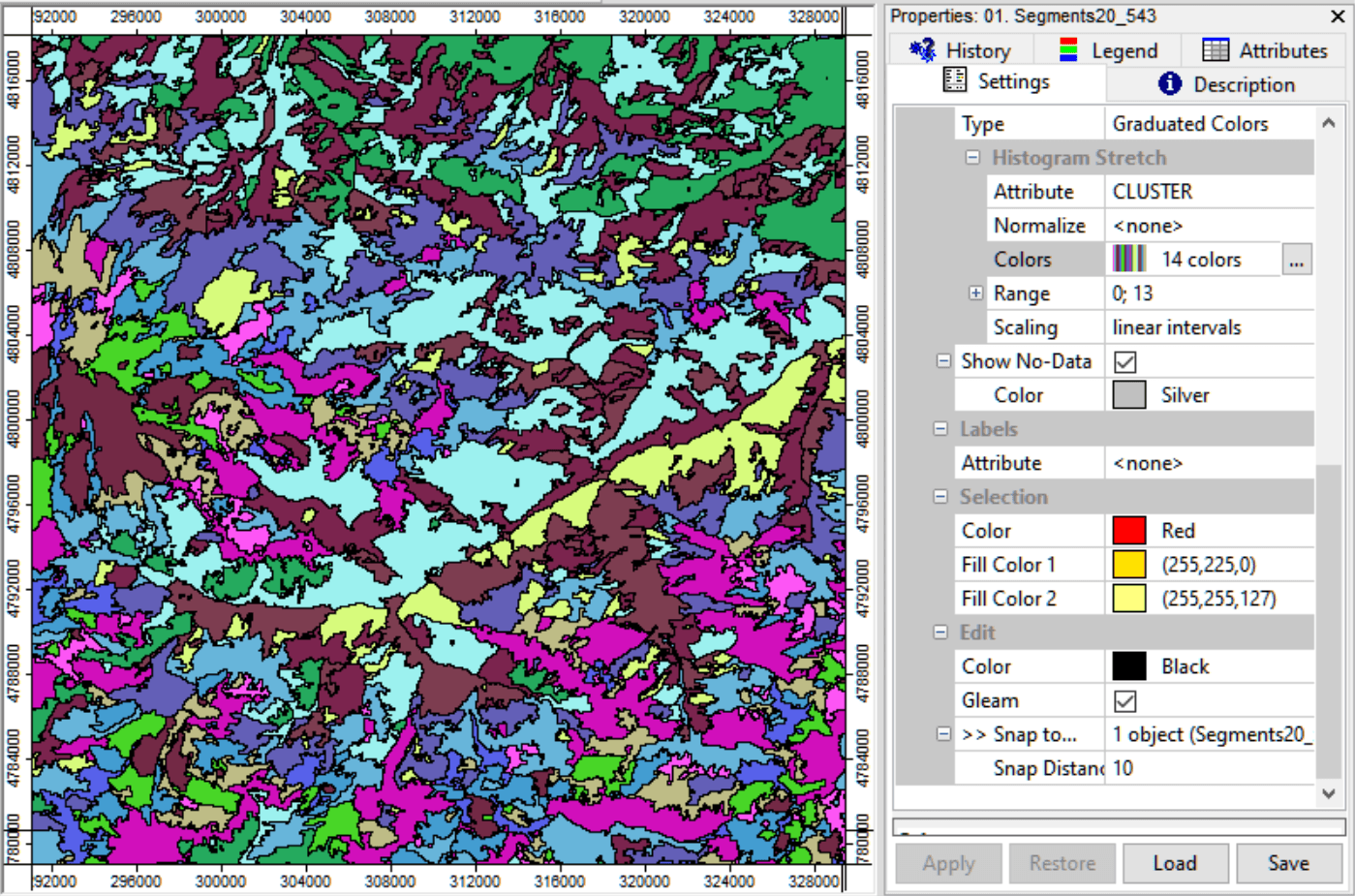
Рис. 15.3 Результат дешифрирования (сегментации) композита NIR-Red-Green (5-4-3) на 14 классов
Сравнение слоя Segment с оригиналом ландшафтной карты позволяет увидеть плюсы и минусы автоматической неконтролируемой сегментации: неплохо различаются склоны с разной экспозицией главной долины, заснеженная вершина Эльбруса и высокие хребты, а также фрагменты склонов разной экспозиции, занятых альпийскими лугами и лесами разных типов.
Дальнейшая оптимизация работы с неконтролируемой сегментацией может заключаться в поиске оптимальных композитов, изменении числа классов и изменением параметра Ширина рандомного посева. Алгоритм в любом случае остается прежним: вырезание необходимой области, составление композита из вырезанных фрагментов, сегментация. Так, например, композиты TIR1-SWIR1-NIR 10-6-5 или SWIR1-NIR-Red 6-5-4 дают иной результат (Рис. 15.4).

Рис. 15.4 Результат дешифрирования (сегментации) композита SWIR1-NIR-Red (6-5-4) на 14 классов
15.2. Кластерная классификация состояний ландшафта
Кластерный анализ - один из способов классифицирования, который разбивает совокупность объектов на классы (кластеры, группы), и, в некоторых случаях позволяет попутно выявить оптимальное число групп. Считается, что мы прибегаем к кластеризации, когда не очень хорошо представляем какие качества (признаки) объектов позволяют их классифицировать.
K-Means Clustering|К-Среднее кластеризация - это еще один вариант неконтролируемой классификации, который автоматически разделяет пиксели изображения на определенное число категорий, имеющих сходные спектральные характеристики. Начальные "сеянные" пиксели служат для инициирования неконтролируемого алгоритма K-средних. Группы пикселей имеют одинаковые значения, а стандартные отклонения и дисперсии невелики. Успешность и эффективность кластеризации относительна, так как число классов, назначенных пользователем, может включать в себя несколько типов ландшафтов (или видов землепользования), которые на самом деле имеют сходные спектральные характеристики, что может быть проблемой для анализа и приведет к ошибкам в характеристиках выходных классов.
В SAGA GIS к инструментам неконтролируемой классификации относится алгоритм K-Means Clustering for Grids набора Classification группы Imagery. Одно из преимуществ данного алгоритма - неограниченное число включаемых в анализ компонентов - в данном случае каналов Landsat, а также возможность получить статистики, объясняющие характеристики каждого кластера (класса).
Grids
Grid System: ...
>> Grids: 4 Objects (Landsat 8, * отображаются выбранные каналы, SWIR2-7, NIR-5, Red-3, Green-4)
<< Claster: create
Tables
<< Statistics: create
Options
Method: Hill_Climbing Rubin
Clusters: 14
Maximum iterations: 10
Normalise: оставить пустым
Start position: random
В диалоговом окне инструмента кроме опции выбора числа классов критическим являются Method|Cпособ кластеризации; предлагаются два различных: Iterative minimum distance [Forgy, 1965], Hill climbing [Rubin, 1967], и Combined, который является компромиссом между обозначенными двумя.
 |
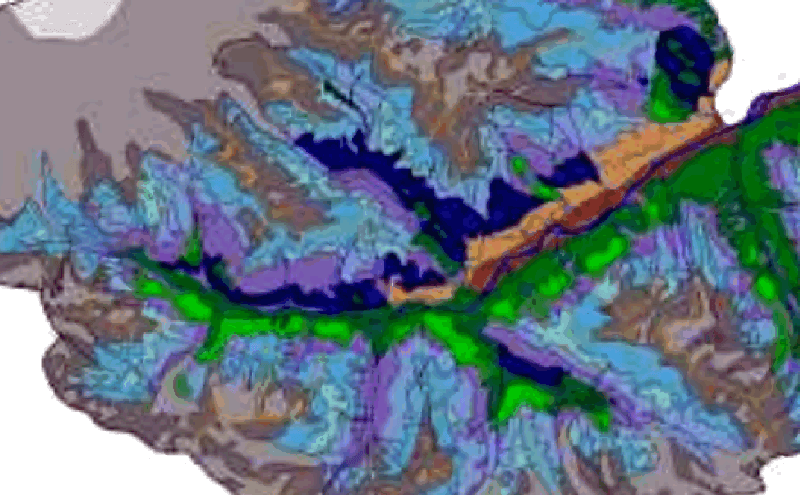 |
Рис. 15.5 Сравнение результата кластеризации на основе каналов SWIR2-NIR-Red-Green (7-5-3-4) на 14 классов по алгоритму Iterative minimum distance с исходной ландшафтной картой на Приэльбрусье
 |
|
Рис. 15.6 Сравнение результата кластеризации на основе каналов SWIR2-NIR-Red-Green (7-5-3-4) на 14 классов по алгоритму Hill climbing с исходной ландшафтной картой на Приэльбрусье
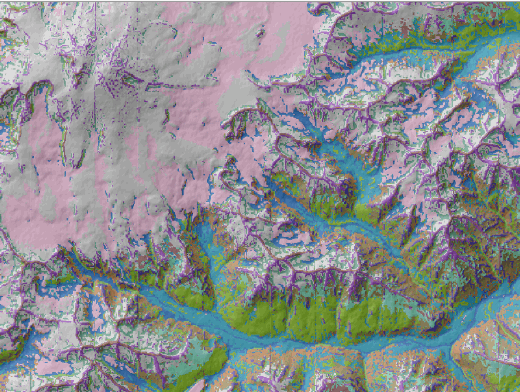
Совершенно очевидно, что K-Means Clustering for Grids - более "умный" алгоритм, поскольку полученный результат гораздо ближе в привычному "рукотворному" варианту ландшафтной карты: мы видим отчетливо прорисованный конус Эльбруса со снежно-фирновым поясом, высокие скально-снежные хребты с боковыми субнивальными отрогами, альпийские луга, фрагменты хвойных и мелколиственных склонов а также сохраненную систему долинных ландшафтов (в неконтролируемой сегментации она в значительной степени была разорвана на отдельные "патчи"), хорошо проработаны и боковые притоки с обращенными к ним контрфорсами вторичных хребтов и отдельных склонов различной экспозиции; отображена и общая "фрактальность" ландшафтной мозаики.
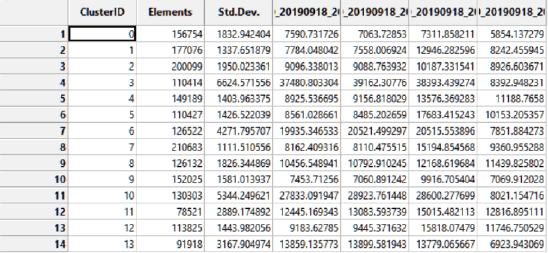
Рис. 15.7 Скриншот таблицы значений кластеров для классификации по алгоритму Hill climbing
Дополнительно генерируемая алгоритмом K-Means Clustering for Grids таблица значений кластеров (отражающая характеристики для каждого класса по выбранным каналам Landsat 8, среднее квадратическое отклонение и число пикселей данного класса) может быть сохранена в форматах CSV или DBF, затем проанализирована в Excel.
О разбросе значений отдельных кластеров можно судить, построив в SAGA GIS с помощью инструмента Scatterplot диаграмму рассеяния, где по оси Y - значения стандартного отклонения (StdDev), а по оси X - номера кластеров (Cluster).
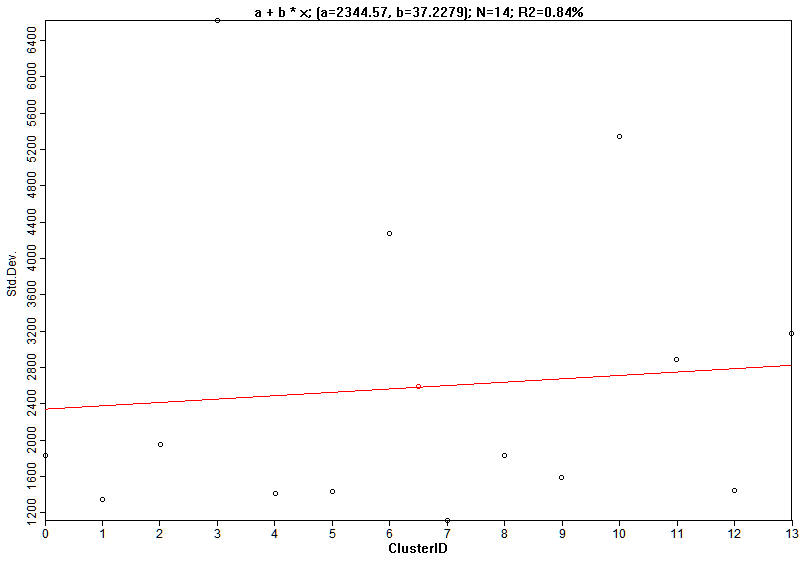
Рис. 15.8 График разброса кластеров для классификации по алгоритму Hill climbing
15.3. Подходы к синтезу состояний и морфодинамической основы ландшафта в гис-моделировании
По причинам объективного характера геоинформационное моделирование развивалось прежде всего в рамках европейской и североамериканской версий ландшафтной экологии, однако самое интересное заключается в том обстоятельстве, что практически все алгоритмы ГИС-моделирования воспроизводили "на новый лад" известные и до сих пор дискуссионные "сюжеты" российского ландшафтоведения, в более широком контексте — географии в целом. Последовательно разрабатываемые и сменявшие друг друга подходы к ГИС-моделированию сложных объектов и феноменов во многом отражают логику научного поиска и эволюцию представлений в рамках классической науки о ландшафтах. В этом смысле можно выделить следующие этапы развития ГИС-моделирования геосистем:
-
1) экспертно-интуитивное выделение границ способом ручного рисования — первоначально в программе векторной графики, позже в различных ГИС-пакетах;
2) гибридное экспертно-компьютерное картографирование на основе комбинированного оверлея в среде ГИС предварительно оцифрованных традиционных тематических карт (геологических, геоморфологических, геоботанических, почвенных и т.д.);
3) комбинированный оверлей классифицированных растровых переменных (производных от ЦМР и снимков типа Landsat), изначально полученных в ГИС и отображающих различные параметры морфолитогенной основы и растительного покрова/землепользования;
4) учет катенарной (склоновой) и гребне-килевой дифференциации с использованием соответствующих геоморфометрических переменных (например — индекса относительного положения на склоне);
5) модели нечеткого наложения с использованием переменных с нечеткой принадлежностью;
6) полуавтоматизированные модели кластеризации и группирования, основанные на k-средних, искусственных нейронных сетях и деревьях классификации, применяемых к более или менее широкому набору переменных;
7) иерархические (поэтапно выполняемые) модели с участием эксперта, задающего правила в рамках классической или нечеткой логики и смены "ведущего фактора дифференциации".
Важно подчеркнуть — перечисленные подходы не абсолютно инновационные, поскольку их логические и математические основания были разработаны в середине либо второй половине XX в., но опыт применения строгих и воспроизводимых ГИС-алгоритмов, позволил выявить их возможности и ограничения, преимущества и недостатки.
Экспертно-интуитивный подход (в западной науке часто именуется как "гештальт-метод") [Wilson, 2018] заключается в экспертном выделении и ручном рисовании границ геосистем. В своем "классическом" виде он был отработан первоначально в отечественном почвоведении [Временная методика, 1984; Степанов, 2006] и доведен до совершенства в рамках методики российского ландшафтного картографирования [Видина, 1962; Исаченко, 1999]. Сущность метода заключается в том, что эксперт выделяет границы ландшафтов (или их частей) сначала в камеральных условиях ориентируясь на несколько источников-подложек (карта четвертичных отложений, разгруженная топографическая карта с горизонталями, фотоплан), действуя, частично, в рамках задаваемых правил формальной логики ("если — то"), частично — руководствуясь интуицией (опытом). Сегодня классический метод не утратил своего значения (прежде всего — дидактического, обучающего), и воспроизводится в ГИС, являя собой вариант рисования в векторных слоях; возможно, один из наиболее замечательных примеров подобных рода "state of art mapping" — ландшафтные карты Атласа ООПТ Санкт-Петербурга [Атлас..., 2016] .
Важно подчеркнуть, что в классическом варианте ручного картографирования исследователь зачастую трассирует отрезки границ между геосистемами одного и того же уровня по разным "тематикам" (переменным), т.е., осуществляет смену ведущего фактора дифференциации в соответствии с экспертной концепцией "на лету". В одном случае граница между урочищами может пролегать по рубежу между четвертичными отложениям, в другом — по морфоизографе, отделяющей ложбину от водораздела, в третьем по границе между луговой и лесной растительностью [Жучкова, Раковская, 2004].
Гибридное экспертно-геоинформационное картографирование опирается на векторизацию бумажных карт, с последующим наложением и согласованием полученных тематических слоев. Таким образом, например, была построена государственная [Ландшафтная карта Мингео СССР] масштаба 1:2500000. Основным методом синтеза в рамках этого подхода было наложение — процедура, которая с позиций формальной логики и математики аналогична оверлею в современных ГИС: комбинированию растров или пересечению полигональных векторов. К. Лоуэлл [Lowell, 1990] и Р. Бейли [Bailey, 1998] отмечали, что, хотя наложение карт представляется самым логичным методом идентификации экосистем, этот подход имеет недостатки, к которым можно отнести:
- Произвольность и невоспроизводимость классификаторов, неизбежно возникавшая в результате смешения традиционных тематических карт (геологических, геоботанических, почвенных), изначально разработанных под разные задачи;
- Эффект информационного шума, проявляющийся в избыточном количестве классов, многие из которых статистически ничтожны;
- Эффект мозаичной "пилы" вдоль границ классов;
- Невысокая, как правило, точность (в том числе вследствие различной детальности и масштабов исходных материалов).
По этим же причинам не слишком удачными оказались и попытки сочетания оцифрованных тематических карт, так или иначе являющимися результатом традиционного мануального картографирования с переменными-производными от ДДЗ [Sayre R., 2008].
Настоящее геоинформационное моделирование связано с появлением работ, в которых наложению подвергались не оцифрованные, а новые тематические (факторные) слои (растровые и векторные) изначально полученные в ГИС посредством преобразования Цифровой Модели Рельефа, или дешифрирования космических снимков, расчета различных коэффициентов по разным сочетаниям каналов и т.д. Так, сочетанием классифицированных растров абсолютной и относительной высоты, уклона и обобщенной кривизны можно получать неплохие и выразительные модели для мелкомасштабного картографирования (см например, карту морфоструктур Африки, полученную таким образом) Global Ecosystems. Однако, (против первоначальных ожиданий) оказалось, что и в этом случае комбинирование растров и пересечение векторов, хотя и может дать корректный результат в случае наложения относительно несложных и немногих переменных, тем не менее, не может служить удовлетворительным способом многофакторного экосистемного (ландшафтного) синтеза.
Максимальное число слоев, которые могут быть подвергнуты оверлею простым комбинированием не может превышать трех, в крайнем случае - четырех "тематик", потому что уже при парном комбинировании (например. простейшем комбинировании абсолютной высоты и уклона) образуются избыточное число сложно интерпретируемых финальных классов, некоторые из которых к тому же являются пустыми множествами, т.е., представляют собой совокупности мыслимых логически, но ничтожных по количеству объектов. Этот эффект заметно усиливается при добавлении в комбинацию растров (или пересечение тематических векторных слоев) каждого нового слоя, что делает данный способ в целом малопригодным для делимитации любых феноменов существующих в многомерном пространстве факторов: ландшафтов, геосистем, экосистем.
Другая очевидная слабость простого комбинирования (растров) или пересечения (векторных слоев) заключается в исходном признании равенства значения факторов. Между тем в реальной действительности в одном случае более сильным фактором формирования и функционирования экосистем может выступать высота места, в другом - экспозиция склона, в третьем - крутизна и т.д. Простой оверлей комбинированием растров позволяет учесть иерархию факторов в виде итоговой классификации за счет процедуры конкатенации позволяющей вывести на первое место в итоговом индексе наиболее значимый показатель. Например, классификация иерархических уровней ландшафтных местоположений может выглядеть как "высота-экспозиция-уклон", или как "экспозиция-высота-уклон", но на комбинаторную мозаику и границы классов результирующего растра изменение позиции в индексировании не повлияет.
В классическом ландшафтоведении при ручном картографировании это затруднение преодолевалось через представления о ведущем факторе, что определяло не только иерархию итоговой классификации, но и технику мануально-экспертного рисования, конкретно - на конфигурацию каждого оверлея, который подвергался последовательной корректировке и отбраковке несущественных деталей [Видина, 1962; Жучкова, Раковская, 2004].
В ГИС-моделировании строгим алгоритмом учета силы/значимости признаков в многомерном пространстве ординации является Weighted Overlay|Взвешенное Наложение - процедура, в рамках которой пользователь назначает "вес" слою в виде целых или десятичных коэффициентов. Например, если мы полагаем, что в условиях выраженной высотной поясности высота места в два с половиной раза более значима чем уклон, а экспозиция - в два раза более важна чем уклон, то факторам при оверлее должны быть присвоены значения 1 - slope, 2 - aspect, 2,5 - height.
Будучи более совершенным по сравнению с простым комбинированием Взвешенное Наложение имеет свои ограничения. Во-первых, трудно представить себе ситуацию, когда соотношение значимости факторов остается постоянным в пределах всей сцены моделирования: например, в предгорье, среднегорье и высокогорье. Следовательно, сцены должна быть разделена на фрагменты, каждый из которых обрабатывается отдельно.
Другое, более существенное затруднение заключается в невозможности учитывать через Взвешенный оверлей обстоятельство синергетического действия факторов (признаков). Например влияние экспозиции обычно связано с уклоном и может быть значимым начиная с некоторых значений последнего: скажем, степень прогрева южных склонов может экспоненциально возрастать на склонах крутизной свыше 5-80, но при этом может не проявляться на высоте менее 500 м вследствие затенения параллельным хребтами, и далее - на высоте свыше 2200 м - фактор экспозиции может почти нивелироваться факторами крутизны и гребне-килевой дифференциации, поскольку именно два последних контролируют, например, сохранность снежников.
Взаимосвязи подобного характера требуют уже более сложных алгоритмов моделирования, в том числе разработанных с использованием аппарата нечеткой логики. Выше на примере геоморфометрических переменных и моделирования форм мезорельефа мы обращались к полуавтоматизированным алгоритмам нечеткой принадлежности и нечеткого наложения (см. раздел 13.4.). Однако для решения более сложных задач эти инструменты используются иначе - с разработкой предварительной гипотезы и свода правил, выраженных на языке Fuzzy Logic|Нечеткой Логики.
Исходная предпосылка нечеткой логики заключается в признании двух видов неопределенности в данных, подающихся на "вход" модели: неопределенность в атрибутах и неопределенность в локализации (пространственном расположении). Таким образом первая неопределенность отображает невозможность однозначного ответа на вопрос "что", вторая - на вопрос "где". Неопределенность в атрибутах существенно значима для моделей обсуждаемого типа, поскольку позволяет описывать размытость (неточность) границ между классами и работать с ситуациями, в которых строгие границы между классами принципиально невозможны, т.е., речь идет как раз об упомянутом выше методологическом "камне преткновения", выраженном в названии статьи "Do mountain exist?".
Нечеткая логика определяет возможности (или вероятности) того, что тот или иной объект, характеризующийся неким набором признаков, относится к определенному классу ("гора", "холм", "разнотравно-злаковый луг", "сосняк бруснично-зеленомошный"). Подчеркнем, что речь идет не просто о неточности измерений (что тоже имеет место), но и о естественном протяженном характере переходов (экотонов) между "ядрами" типичности классов - явление, давно уже описанное в классическом ландшафтоведении, и приводящее многих исследователей к мысли о невозможности "векторного" моделирования ландшафтов.
Использование алгоритмов нечеткой логики предполагает предварительное построение гипотезы с ансамблем правил, описанных на языке нечеткой (не булевой) логики. Допустим пользователь полагает уклон важным фактором ландшафтной дифференциации. В обычном случае мы используем один из вариантов экспертного или полуавтоматического (естественные границы, геометрические интервалы, квантили) классифицирования этого показателя на классы. В итоговом атрибутированном растре каждый пиксель либо относится (значение true в рамках булевой логики) либо не относится (значение false) к конкретному классу. В рамках нечеткой логики переходы между таксонами выражают не по правилам вероятностного подхода (т.е., вне зависимости от "переломов" гистограммы распределения), а согласно графику одной из линейных или криволинейных функций (Fuzzy Gaussian, Fuzzy Large, Fuzzy Linear, Fuzzy MS Large, Fuzzy Small), значения которой (точки на прямой, точки перелома прямой, точки изгиба кривой) позволяют присвоить каждому пикселю исходного растра (в нашем примере растру уклона) показатель степени принадлежности к определенной части множества (подмножеству).
Свойство принадлежности назначается по шкале от 0 до 1. В этом случае, скажем, значение 1 будет означать полную принадлежность к классу (например "крутой склон"), а значение 0,60 - только частичную принадлежность ("скорее крутой, чем пологий"), тогда как значение 0,00 с полной определенностью не относятся к подмножеству склонов "крутые".
Для такой предварительной обработки значений растров переменных используется инструмент Fuzzy Membership|Нечёткая принадлежность. Таким же образом обрабатываются все остальные факторы, рассматриваемые как входные параметры модели (значения таксонов ландшафтных и вегетационных индексов, классы landuse|landcover). Далее производится нечеткое наложение Fuzzy Overlay набора привлеченных параметров. В этом смысле данный алгоритм аналогичен классическому (где на первой стадии проводится реклассификация сырых переменных - факторных растров, на второй - их комбинирование).
Нечеткая логика как способ обработки исходных данных и метод их переклассификации лежит в основе многих современных алгоритмов, в том числе - нейронных сетей.
Нечеткая логика требует экспертного участия, поскольку результаты будут напрямую зависеть от сформулированных правил. Например, пользователь решает, что в модели ландшафтов горной области должны получить отображение четыре высотных пояса, но их границы (как это всегда и бывает) не могут быть однозначно определены строгими пороговыми значениями. Тогда для каждого пояса можно задать правила соответствия приблизительно следующего вида: "пояс мелколиственных березовых лесов начинается не ниже 1600 м и никогда не заходит за высоту 2400 м, при этом типичные высота которую занимает данная растительная формация обычно находится между 1800 и 2200 м". Такого вида принадлежность передается функцией принадлежности Нечеткий Гауссов (Fuzzy Gaussian).
Дополнительные возможности для моделирования предоставляет инструмент Fuzzy Overlay|Нечеткого Наложения позволяющий использовать разные типы нечетких операторов (OR, AND, PRODUCT, SUM, GAMMA). Например, при обычном комбинировании растров высоты и залесенности склонов, мы получаем результаты вида "очень высокий незалесенный склон" только в случае, если в соответствующих входных растрах высота - True и наличие леса - Fulse.
Использование Нечеткого Наложения может предоставить целый спектр результатов в зависимости от типа наложения и оператора, в одних случаях сужая искомое подмножество, в других случаях расширяя его. Так Fuzzy And|Нечеткое И - определяет наиболее "жесткое" наложение при котором принадлежность и для уклона, и для залесенности > =0,5, что определит минимальное вхождение исходных растров в результат. Fuzzy Or|Нечеткое Или, напротив, является самым мягким условием наложения, при котором в результирующий растр войдут ячейки, у которых хотя бы одно из свойств (уклон или залесенность) > =0,5.
Рассмотренные выше подходы к сегментации рельефа, растительного покрова и характера землепользования представляются перспективными для решения проблемы ГИС-моделирования сложных геоэкосистем, например, природных или культурных ландшафтов. В любом случае подобное моделирование должно предваряться получением ответов на два вопроса:
1) Какие исходные данные используются?
2) Какие существующие алгоритмы наилучшим образом подходят для решения конкретной задачи?.
Различные варианты возможных ответов на эти два вопроса могут быть (в первом приближении) сведены к двум подходам, в какой-то степени воспроизводящим экспертные техники традиционного ландшафтного картографирования. Заметим здесь, "в скобках", что вопрос о почвах мы оставляем за рамками наших рассуждений, поскольку почвоведы апробируют аналогичные алгоритмы полагая при этом, что в результате синтеза местоположений с растительным покровом они получат... soil`s predictible maps, т.е., модели почвенного покрова [Kumar, Sinha, 2018; Кириллова, 2020].
Первый подход, (пожалуй, наиболее близкий к технике классического ландшафтного картографирования), предполагает синтез двух предварительно полученных слоев: морфолитогенной основы в виде ландшафтных местоположений|landscape site [Jasiewicz, Stepinski, 2013] и биоты в виде классифицированных типов растительности/типов землепользования (LULC) [Hansen et al., 2022].
Второй подход заключается в "сборке" из более-менее обширного набора слоев, являющихся частными характеристиками ландшафтных местоположений и растительного покрова. В рамках этого подхода можно выделить два метода, первый, когда в роли переменных для характеристики меcтоположений используются вторичные (производные) геоморфометрические переменные, а для характеристики растительного покрова — ландшафтные (в том числе вегетационные, но не только) индексы. Другой метод, разработанный в рамках второго подхода, предполагает агрегирование, с одной стороны, относительно большого числа первичных (локальных) метрик, (уклон, экспозиция, различные виды кривизны, индекс конвергенции и т.д.), с другой - отдельных каналов космических снимков или неклассифицированных вегетационных индексов.
Различие между этими вариантами в том, что в случае привлечения большого числа первичных метрик мы в большей степени устраняемся от экспертного участия, каковое включает переклассификацию, т.е., дифференциацию сложных переменных посредством выбора числа и пороговых значений классов. Ведь если значение индекса топографической позиции является отражением гребне-килевой дифференциации, то высота, уклон, профильная/горизонтальная кривизна характеризуют первичные параметры данной точки поверхности, и, следовательно мы перепоручаем полуавтоматическому ГИС-алгоритму больший объем "работы" по компоновке итоговых таксонов получаемого в итоге прототипа ландшафта.
Таким образом, два потенциальных подхода к ГИС-моделированию геоэкосистем различаются по нескольким основаниям:
- степени вовлечения экспертного знания (максимально — в первом, минимально — во втором);
- прозрачности процесса моделирования (в первом случае мы можем судить о том, из каких именно исходных классов биоты и ландшафтных местоположений образовались конечные классы ландшафтов, во втором — перед нами условно "серый ящик", хотя по таблицам статистики, скажем, в случае кластерного анализа мы можем установить дифференцирующую роль и значения всех привлеченных параметров);
- числу используемых для делимитации и классификации слоев-переменных, характеристик ландшафтных местоположений, биоты и землепользования (первый подход — две, второй — от 3-6 до более чем 5-8);
- сложности интерпретации результатов.
Инструменты, выбираемые для ГИС-моделирования могут быть условно разделены на воспроизводящие традиционные экспертные техники и инновационные, связанные с современными методами кластеризации, группирования и машинного обучения.
К воспроизводящим привычные экспертные алгоритмы относится простое наложение признаков - комбинированием с помощью инструмента Combine. Достоинство этого метода заключается в его традиционности: у пользователя возникает ощущение, что конечные классы можно получить в результате операции, представляющей собой алгебру матриц. Каждая точка пространства получает набор характеристик, которые могут быть объединены конкатенацией в составной индекс. Однако этот алгоритм пригоден только для первого подхода - сочетания "предуготовленных" классов ландшафтных местоположений с классами растительного покрова/землепользования. "Родовые" недостатки наложения комбинированием мы упоминали выше: возникновение некоторого числа ничтожных классов, сложный и некорректный характер границ и т.д.
Однако, наибольшие перспективы связаны с современными алгоритмами кластеризации, которые в первом приближении могут быть разделить на две крупных категории: полуавтоматические (Unsupervasied) методы и контролируемые (Supervasied) методы классификации.
Полуавтоматические алгоритмы классификации:
- Иерархический кластерный анализ,
- K-Means кластеризация,
- ISODATA кластеризация.
Контролируемые алгоритмы классификации (с обучением):
- Дискриминантный анализ,
- Деревья классификации,
- Нейронная сеть прямого распространения,
- Случайный лес,
- Наивный байесовский классификатор.
Все перечисленные методы, в принципе, могут примениться в рамках любого из описанных выше подходов, однако результаты всякий раз будут в существенной степени зависеть от учитываемых факторов, состава и качества исходных слоев, масштаба, сложности классификаторов исходных тематик и т.д.
15.4. Первый подход: синтез готовых классификаций ландшафтных местоположений и биоты
Для ознакомления с возможностями первого подхода попытаемся соединить результаты классификации ландшафтных местоположений с классификацией растительного покрова и землепользования для моделирования прототипов природных ландшафтов. В качестве исходных используем полученные ранее (см. разделы 11 и 13) слои сегментированного рельефа (K-means cluster classification по семи морфометрическим переменным в SAGA GIS - Рис. 15.9a) и автоматического дешифрирования изображения Landsat 8 (Неконтролируемая кластеризация на основе каналов SWIR2-NIR Red-Green - Рис. 15.9b) на ключевую территории Приэльбрусья, для которой существует ландшафтная карта выполненная обычным традиционным способом (авторы А.Н.Гуня и М.Н.Петрушина).


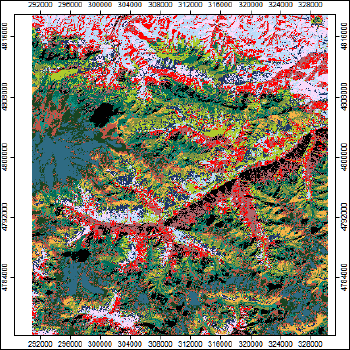

Рис. 15.9 Исходные растры сегментации: a) ландшафтных местоположений - 16 классов, b) состояний биоты и землепользования - 14 классов
Традиционное (как в классическом ландшафтоведении) наложение комбинированием может быть осуществлено тремя алгоритмами геоинформационного моделирования: Combine (комбинированием), Multiply (умножением в калькуляторе растров), и Fuzzy Overlay (нечетким наложением).
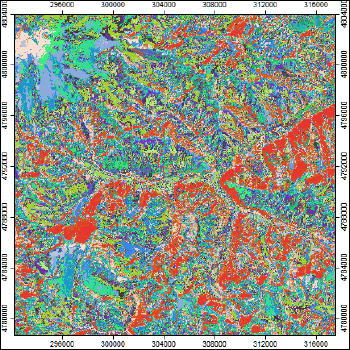

Рис. 15.10 Результат оверлея растров рельефа и биоты инструментом Multiply в SAGA GIS - 224 классов
Перемножение 14 классов растительного покрова/землепользования и 16 классов рельефа образует мозаику из 224 классов, которые достаточно сложно интерпретировать, если не применить один из способов группирования классов.
Аналогичный результат получим оверлеем способом Combine в ArcMAP10.x
 |
 |
Рис. 15.11 Результат оверлея растров рельефа и биоты методом Combine в ArcMAP10.x: a) сырой комбинированный растр - 224 класса, b) растр после чистки и генерализации алгоритмами Focal statistic и Boundary Clean - 222 класса
Самостоятельный интерес представляет картина частотного распределения классов, которая отображается на вкладке Classify оформления слоя ArcMAP10.x и позволяет обнаружить три-четыре иерархических уровня организации ландшафта, связанных, вероятно, с горным массивом Эльбруса, широтно вложенной долиной Баксана, главными боковые хребтами и долинами северо-западного и юго-восточного простирания, крупными контрфорсами хребтов и небольшими ущельями, и, наконец, отдельными склонами и распадками между ними.
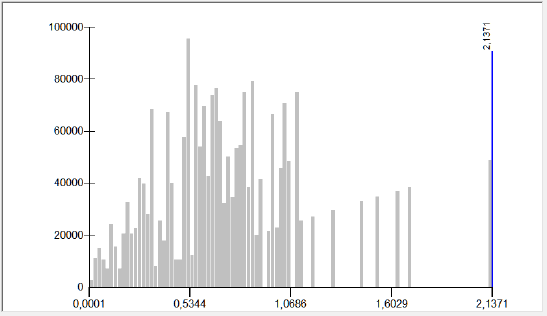
Рис. 15.12 Гистограмма распределения итоговых классов наложения ландшафтных местоположений и состояния биоты и землепользования
Аналогичное действие может быть произведено с двумя векторными полигональным слоями - ландшафтных местоположений и состояний - с помощью инструмента Identity|Идентичность (в ArcMAP10.x: Analyst Tools >> Overlay >> Identity). При использовании опции join_attributes=ALL атрибутивные значения из входных классов пространственных объектов будут скопированы в выходной класс. Конкатенацией исходных кодов можно получить комплексный индекс. Результат векторного пересечения аналогичен комбинированию растров - 224 класса.
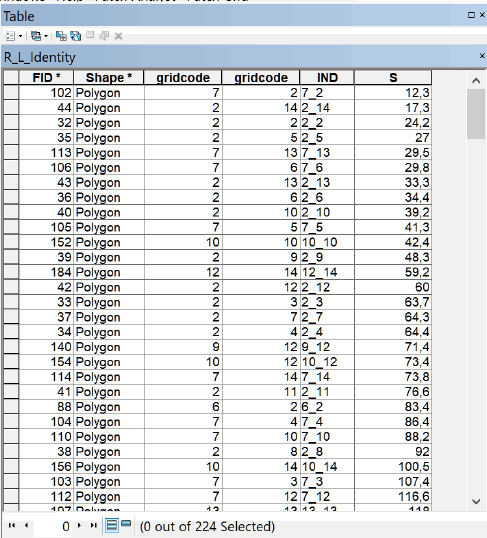
Рис.15.13 Таблица векторного слоя пересечения полигонов инструментом Идентичность
Далее полигоны можно классифицировать и свести к необходимому числу классов используя один из инструментов кластеризации: Grouping Analysis|Анализ Группирования ArcMAP10.x или K-means cluster classification SAGA GIS и последующее Dissolve|Cлияние полигонов по номеру группы или кластера.
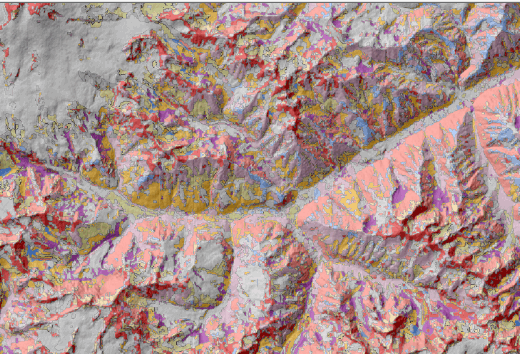
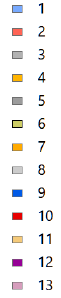
Обобщая опыт синтеза простым наложением, можно отметить, что алгоритм классического ландшафтного оверлея сохраняет дидактическое (т.е., обучающее) значение, но степень его пригодности уменьшается пропорционально сложности привлеченных растров ландшафтных местоположений и ландшафтного покрова, т.е., пропорционально увеличению площади и усложнению разнообразия сцены моделирования.
Нестрогим (в терминологии ГИС-моделирования) экспертным вариантом комбинирования можно считать алгоритм "подстановки" дополнительной характеристики к "основной": когда (согласно технике ландшафтного картографирования ленинградской школы [Исаченко, 1999]) за базовый признак принимаются ландшафтные местоположения, а биота рассматривается как инвариант состояния. Для воспроизведения этого метода в рамках ГИС-модели значения (классы) биоты могут быть извлечены в предварительно построенную матрицу ландшафтных местоположений. Если оба слоя (слой местоположений и слой состояния биоты) - полигональные векторы, то может быть использован алгоритм Identity|Идентичность ; в варианте с растрами вычисляется Zonal Statistic|Зональная статистика слоя состояния биоты по слою ландшафтных местоположений.
Инструмент ArcMAP10.x Zonal Statistic (Spatial Analyst Tools >> Zonal >> Zonal Statistic) ArcMAP10.x содержит две опции: в поле Zonal Field|Поле Зоны - следует указать уникальный идентификатор полигонов (но не gridcode!) и опцию Statistic Type|Тип Статистики. Последняя принципиально важна: в пределах любого конкретного полигона местоположений могут оказаться ячейки растра, принадлежащие к разным классам состояния ландшафта (LULC) - двум-трем и более. При "интуитивном" рисовании по двум калькам (местоположений и биоты) эксперт принимает индивидуальное решение в каждом конкретном случае, в варианте ГИС-моделирования мы должны предположить - на что больше похожа такая интуиция, т.е., выбрать тип статистики: "MEAN|СРЕДНЕЕ АРИФМЕТИЧЕСКОЕ", "MEDIAN|МЕДИАНА" или "MAJORITY|БОЛЬШИНСТВО".

Преимущества этого метода перед простым оверлеем (комбинированием) очевидны, и в целом подобное решение не так далеко от традиционного ландшафтного картографирования. Обратим внимание, что извлечение зональной статистики оказывает влияние на форму мозаики итогового растра, чтобы в этом убедиться достаточно сравнить полученный растр зональной статистики с векторными контурами ландшафтных местоположений и состояний ландшафта.
 |
 |
Слой состояний ландшафта (растительного покрова/землепользования) не влияя на очертания границ отдельных полигонов слоя ландшафтных местоположений интегрирует полигоны с одинаковыми значениями, что приводит к формированию более обобщенного рисунка контуров (Рис. 15.16).
 |
 |
Рис. 15.17 Сравнение растра зональной статистики состояний ландшафта по полигонам ландшафтных местоположений с экспертной ландшафтной картой
Сравнение растра зональной статистики состояний ландшафта по полигонам ландшафтных местоположений с экспертной ландшафтной картой показывает неплохое сходство (Рис. 15.17). Многие контуры лесных и степных ландшафтов, практически идентичны, что обусловлено высокой степенью связи ландшафтных местоположений, приуроченных к мезоформам рельефа и типа растительности: например, на склонах южных экспозиций — степи, а на склонах северной экспозиции — леса. Также схожи контуры ландшафтов с отсутствием или очень слабым развитием растительности: гляциальные на привершинных поверхностях и субнивальные луговые на верхних склонах хребтов.
Fuzzy Overlay|Нечеткое наложение может рассматриваться как еще один алгоритм синтеза морфолитогенной основы и биоты ландшафта. Инструменты Нечеткого наложения присутствуют как в ArcMAP10.x (Spatial Analyst Tools >> Overlay >> Fuzzy Overlay), так и в SAGA GIS (Grid >> Calculus >> Fuzzy Intersection). В обеих ГИС пользователю необходимо выбрать Overlay type|Тип наложения; инструмент Fuzzy Overlay ArcMAP10.x предоставляет здесь больше возможностей.
Выбор типа наложения открывает спектр вариантов объединения данных, базирующихся на анализе теории множеств:
- AND|И,
- Or|Или,
- Product|Произведение,
- Summ|Сумма,
- Gamma|Гамма.
Для ситуации, в которой входными данными являются уже определенные классы (ландшафтных местоположений и состояния ландшафта), мы не можем воспользоваться методами Fuzzy Summ (линейная комбинационная функция даст около 200 классов) и Fuzzy Product (перемножает значения входных ячеек и без предварительного определения Нечеткой принадлежности является полным аналогом процедуры Combine).
Fuzzy And определяет своего рода общее минимальное значение для принадлежности "пригодности" всех входных переменных, соответственно число итоговых классов будет равно числу классов растра с минимальным количеством таксонов - в данном случае это 14 классов ландшафтных состояний. Fuzzy Or, напротив, возвращает максимальное значение наборов, к которым относится местоположение ячейки, и, следовательно, число классов будет эквивалентно числу классов растра с максимальным количеством таксонов (16 классов ландшафтных местоположений).
 |
 |
Рис. 15.18 Синтез ландшафтных местоположений и состояний ландшафта методом Fuzzy overlay: a) Fuzzy AND|Нечеткое И, b) Fuzzy OR|Нечеткое ИЛИ
Сравнивая два типа Нечеткого наложения можно заметить, что Нечеткое ИЛИ лучше сохраняет целостность долинно-речной и эрозионной сети. Однако оба варианта достаточно далеки от экспертной карты, что свидетельствует о несхожести нечеткой логики с логикой традиционного ландшафтного картографирования.
Более сложные решения (уже выходящие за рамки традиционных методов ручного картографирования) проблемы синтеза морфолитогенной основы ландшафта и биоты предполагают использование алгоритмов кластерного анализа (неконтролируемого и с обучением), а также методом классификации максимального подобия и искусственной нейронной сети.
К неконтролируем методам классификации относятся так называемый Изокластерный анализ и К-means классификация. Инструменты изокластерного анализа выполняет неконтролируемый алгоритм классификации (Isodata, что означает Self-Organizing Data Analysis Techniques|Итеративные Методы Самоорганизующегося анализа данных): сложный алгоритм автоматически разбивающем пиксели композитного растрового слоя на определенное число таксонов ("классов"), имеющих сходные "спектры" по всей совокупности использованных выходных переменных, когда в каждом данном таксоне по конкретной переменной значения пикселей близки, а стандартные отклонения и дисперсии невелики; операция повторяется несколько раз, чтобы в конечном итоге создать сегментированное изображение, и может дополнительно генерировать файл "спектральной" сигнатуры, содержащий характеристики каждого класса [Memarsadeghi et al., 2007].
В SAGA GIS ISODATA Clustering for Grids|Изокластерный анализ для гридов позволяет использовать ряд опций, которые заметно влияют на итоговый результат.
Grid systems: ...
>> Features: LULC, Landscape sites
<< Clusters: Create
Tables
<< Statistic: Create
Option
Normalize: check
Maximum Number of iterations: 20
Initial Number of Clusters: 12
Maximum Number of Clusters: 16
Mininal Number of Samles in a Cluster: (*минимальное число образцов для отдельного кластера) 12
Start Partition: (*порядок разбиения на кластеры) random
Однако реальное число выходных кластеров в SAGA GIS определяется самим алгоритмом - повлиять на него можно лишь косвенно (в зависимости от входных данных), увеличивая число максимальных классов.

Рис. 15.19 Синтез ландшафтных местоположений и состояний ландшафта методом алгоритмом ISODATA Clustering SAGA
Инструмент пакеты ArcMAP10.x Iso Cluster Unsupervised Classification (Spatial Analyst >> Multivariate) сочетает в себе функциональные возможности собственно изокластерного анализа и Maximum Likelihood|Классификации максимального правдоподобия. Критические опции: Number of classes|Число классов, Minimum number of cells in a valid class|Значение минимального числа ячеек, представляющих класс (по умолчанию - 20) и Sample interval|Расстояние между сеянными образами. Первая опция позволяет регулировать величину ареалов выходных классов, вторая повлияет на текстуру выходного файла. Изокластерный анализ ArcMAP10.x имеет преимущество перед аналогичным алгоритмом SAGA GIS поскольку позволяет контролировать главную опцию - число классов.


Рис. 15.20 Синтез ландшафтных местоположений и состояний ландшафта методом алгоритмом ISODATA ArcMAP 10.x
Алгоритм изокластерного анализа по своему содержанию достаточно сложен, именно поэтому он позволяет получить сравнительно корректный, близкий к экспертному рисованию результат: неплохо выделены привершинные поверхности массива Эльбруса, хорошо передана локальная (контрфорсы - распадки) гребне-килевая дифференциация склонов. К погрешностям метода можно отнести нарушенную структуру долинно-речной и эрозионной сети.
Собственно кластерный анализ может быть проведен с помощью инструмента K-Means Clustering for Grids SAGA GIS. Критичными опциями являются число кластеров, Method|Метод, и Start Partition|Порядок дифференциации.

Рис. 15.21 Синтез ландшафтных местоположений и состояний ландшафта методом алгоритмом K-Means Clustering for Grids SAGA GIS
Теоретически результат кластеризации может быть оптимизирован с использованием принципиально иного инварианта кластеризации - кластеризации с обучением. Инструменты подобного рода присутствуют во всех популярных ГИС, в SAGA GIS это Supervised Classification for Grids (Imagery >> Classification), в ArcMAP10.x - близкий по алгоритму инструмент Classify Raster.
Классификация с обучением требует предварительного создания файла "затравок" или образцов предполагаемых классов. В нашем случае они могут быть получены путем формирования векторного слоя точек в центрах ареалов экспертной ландшафтной карты и последующим превращением точечного файла в полигональный посредством инструмента Buffer.

Рис. 15.22 Полигональный файл обучающих образцов - небольших окружностей, полученных буферизацией центроидов векторных контуров обводки исходной экспертной ландшафтной карты
Инструмент Supervised Classification for Grids SAGA GIS содержит несколько опций, из которых критичны Method|Метод (предлагается семь вариантов) и Probability Reference|Способ соотнесения с образцом (абсолютный и относительный).
 |
 |
 |
 |
Рис. 15.23 Результаты кластеризации в SAGA GIS с обучением: а) с опциями Method - Maximum Likelihood и Probability Reference - Relative, b) Method - Winner Takes all, Probability Reference - Absolute
Выходные классы классификации с обучением соответствуют набору таксонов обучающего файла по числу и сохраняют семантику (номенклатуру) классов. Результат может оказаться разочаровывающим - как в данном случае. Отчасти это может объясняться малым количеством "затравок" и небольшой площадью их ареалов, однако может существовать и более серьезная проблема - выбранные для затравок "точки" являются на самом деле плохой "репрезентацией" экспертных действий, иными словами - они не являются "ядрами" типичности в каждом конкретном классе.
Наконец, еще один вариант синтеза с использование обучения, который приобретает все большую популярность - классификация по алгоритму Нейронных Сетей - Neural Network Classification (Imagery >> OpenCV >> Artificial), реализованному в SAGA GIS и представляющему собой интеграцию библиотеки машинного обучения OpenCV для классификации гридов. Инструмент сложен в использовании и предполагает тщательную настройку опций способом "проб и ошибок".
Grids
Grid systems: ....
>> Features: LULC, Landscape sites
<< Clusters: Create
Options
Load Model
Model Training
>> Training Areas: Points_Landscape_Buff
Class Identifier: Ind
Save Model
Number of Layers: 3 *Число слоев в нейронной сети (за исключением входных, варианты от 1 до 3
Number of Neurons: 3 *Число нейронов в каждом слое сети, целое число от 1 до 3
Maximum Number of Iteration: 300 *Максимальное Число Итераций
Activation Function: Identity *Используемая Функция (Identity, Sigmoid, Gaussian)
Training Method: back propagation *Метод Обучения (resilient propagation, back propagation)
Weight Gradient Term: 0,1
Moment Term: 0,1
Также как и в случае кластеризации с обучением, результат работы алгоритма Neural Network Classification по образцам-затравкам далек от экспертной ландшафтной карты, и несмотря на сохраненную семантику легенды на самом деле презентует всего 7 классов (остальные, по всей вероятности "элиминируются" в процессе выполнения скрипта как ничтожные).
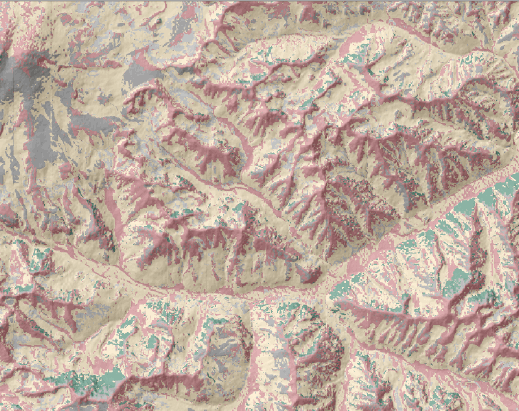
Рис. 15.24 Результат синтеза морфолитогенной основы и состояний ландшафтов с помощью инструмента Искусственная нейронная сеть в SAGA GIS
Таким образом ГИС-моделирование ландшафтов на основе двух классифицированных растров, (один из которых отображает дифференциацию морфолитогенной основы, а другой - растительный покров и виды землепользования) может быть осуществлено с использованием разных алгоритмов. Методы, которые, казалось бы, логически отражают последовательность действий при экспертном картографировании (простой оверлей слоев комбинированием) приводят к плохо интерпретируемым результатам с избыточным числом классов и общим высоким уровнем информационного шума. В качестве паллиативного можно рассматривать оверлей алгоритмом Идентичность с последующим группированием классов. В том случае, если поставлена задача максимально приблизиться к конфигурации экспертно-мануальной карты, вероятно, оптимальным вариантом является Зональная Статистика растра ландшафтных состояний по полигонам ландшафтных местоположений.
Более сложные методы неконтролируемой классификации - такие как К-среднее Кластерный Анализ и Изокластерный Анализ, дают результаты, представляющие самостоятельный интерес (с точки зрения их соответствия сложному набору ландшафтообразующих факторов), но мало сравнимый с экспертной картой - прежде всего по подробности итоговой мозаики и точности изображения. Классификация с обучением не позволяет радикально оптимизировать результат кластерной классификации ни в случае кластерного анализа, ни в случае применения искусственных нейронных сетей, поскольку итогом обучения является примитивизация изображения, утрата ряда классов и преувеличение роли и ареалов оставшихся таксонов.
15.5. Второй подход: синтез набора различных переменных, характеризующих признаки ландшафтных местоположений и состояний ландшафта
Возможности второго подхода связаны с использованием набора из нескольких переменных, характеризующих те или иные свойства ландшафтных местоположений растительного покрова и землепользования (т.е., состояний ландшафта). Подобная методика требует живого участия эксперта, прежде всего, в выборе переменных, и только затем - в определении способа их интеграции. Очевидно, что и то, и другое, не может быть установлено "раз и навсегда": набор переменных будет зависеть от особенностей региональной ландшафтной дифференциации, а способ интеграции - от масштаба сцены, целей моделирования и требований к конечным (выходным) данным.
Интеграция нескольких слоев не может быть решена средствами простого (комбинирование, идентичность) или сложного (зональная статистика) оверлея. Перспективными здесь являются алгоритмы кластерного и изокластерного анализа, нечеткого наложения с предварительной обработкой входных переменных инструментом нечеткой принадлежности и алгоритмы искусственных нейронных сетей. Попытаемся продемонстрировать такого рода "ландшафтный синтез" используя в качестве переменных геоморфометрические показатели, ландшафтные и вегетационные индексы.
Как мы уже могли убедиться Изокластерный анализ является одним из способов выделения классов на основе нескольких переменных. ISODATA Clustering for Grids SAGA GIS позволяет выявить таксоны без точного указания оператором числа конечных классов: можно лишь определить минимальное и максимальное значение. Естественно результат будет весьма чувствительным к набору переменных и их количеству: продемонстрируем это обстоятельство на трех примерах.
В первом примере проведем анализ для семи переменных, пять из которых определяют ландшафтные местоположения, два - растительный покров и землепользование:
- Relative Slope Position|Относительное положение на склоне,
- Slope|Уклон поверхности,
- Maximum Curvature|Максимальная кривизна,
- Minimal Curvature|Минимальная кривизна,
- Positive Openness|Положительная открытость,
- IPVI, Infrared Percentage Vegetation Index|Инфракрасный вегетационный индекс,
- NDWI, Normalised Differentiated Water Index|Нормализованный дифференцированный водный индекс.
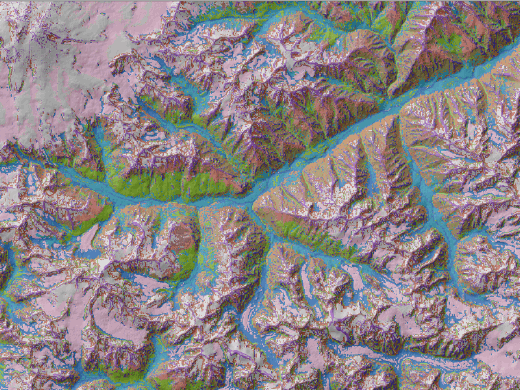

Рис. 15.25 Первый вариант синтеза семи слоев по алгоритму ISODATA Clustering for Grids SAGA GIS
В следующем примере увеличим число и изменим, частично, состав переменных:
- Normalized Height|Нормализованная высота,
- Slope|Уклон поверхности,
- Openness|Общая открытость,
- Valley Depth|Глубина долин,
- Maximum Curvature|Максимальная кривизна,
- Minimal Curvature|Минимальная кривизна,
- IPVI, Infrared Percentage Vegetation Index|Инфракрасный вегетационный индекс,
- NDWI, Normalised Differentiated Water Index|Нормализованный Дифференцированный Водный Индекс,
- NDMI, Normalized Difference Moisture Index|Стандартизованный Индекс Различий Увлажненности.


Рис. 15.26 Второй вариант синтеза девяти слоев по алгоритму ISODATA Clustering for Grids SAGA GIS
Преимущество любых видов кластерного анализа (в частности ISIDATA классификации или K-means классификации) - возможность получить характеристики итоговых таксонов в виде таблицы статистик Means|Среднее и StDev|Стандартное отклонение; последний параметр может быть полезен как показатель близости ("кучности") значений внутри группы.
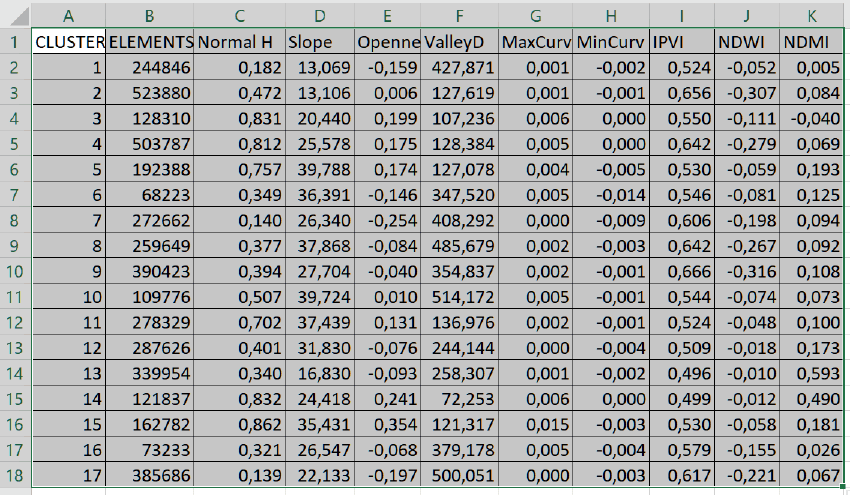
Рис. 15.27 Таблица средних значений 17 кластеров второго варианта (по девяти переменным) ISODATA Clustering for Grids SAGA GIS
В третьем варианте уменьшим число переменных, отражающих ландшафтные местоположения за счет введения более сложного нелокального показателя — индекса топографической позиции и введем ландшафтный индекс NDSI, специально предназначенный для выделения ледовых и снежных поверхностей.
- Topographical Index|Индекс топографической позиции,
- Slope|Уклон поверхности,
- Openness|Общая открытость,
- Convergence Index|Индекс схождения,
- IPVI, Infrared Percentage Vegetation Index|Инфракрасный вегетационный индекс,
- NDMI, Normalized Difference Moisture Index|Стандартизованный индекс различий увлажненности,
- NDSI, Normalized Difference Snow Index|Стандартизованный индекс индекс различий снежного покрова.


Рис. 15.28 Третий вариант синтеза семи слоев по алгоритму ISODATA Clustering for Grids SAGA GIS
Сравним полученные варианты кластеров. Первый вывод, который можно сделать: число привлеченных растров-переменных влияет на количество конечных классов - чем больше переменных, тем большее число итоговых таксонов (15 - для семи переменных в первом случае, 17 - для девяти во втором). Качество привлеченных растров также оказывает влияние: сложные комплексные переменные с классифицированными значениями уменьшают число итоговых таксонов. Так введение Индекса топографической позиции в третьем примере сократило число таксонов до 12. Замена или добавление даже единственной переменной в набор, подвергающийся кластерному анализу, заметно меняет мозаику итоговой классификации. Так, и первая, и вторая классификация хорошо передают элементы долинно-речной и эрозионной сети, а также катерную (склоновую) дифференциацию. Присутствие двух видов кривизны позволяет разделить склоны на локальные контрфорсы и тальвеги (распадки) между ними. Однако замена Относительного положения на склоне на Нормализованную высоту фактически убирает дифференциацию склонов массива Эльбруса. Ландшафтные и/или вегетационные индексы ответственны за генерацию более-менее протяженных ареалов в местах с относительно выровненным рельефом, что хорошо видно на примере второго варианта с присутствием трех индексов. Введение сложных индексом в целом гомогенизирует мозаику выходных классифицированных растров, так Индекс топографический позиции затушевывает склоновую дифференциацию, акцентируя при этом гребне-килевое разделение.
K-means кластерный анализ - близкий алгоритм, с несколько иной математикой "внутри" и поэтому дающий другие результаты; для сравнения используем те же переменные, что и для трех вариантов ISODATA классификации
В общих чертах результат практически не отличим от первого варианта классификации, в частности абсолютно идентично обработан массив Эльбруса с выделенными двумя классами ледниковых (привершинных) и фирново-снежно-ледниковых ландшафтов. Аналогично сконфигурировались ледниковые полуцирки и выводные долинные ледники нивального пояса. Сходным образом интерпретированы долина Баксана и его притоков. Различия наблюдаются в катенарной дифференциации склонов: K-means алгоритм разбивает их на дробные фрагменты, тогда как ISODATA анализ сохраняет подобие высотной поясности, особенно в нижней и средней части склонов, что приближает результат изокластерной классификации к экспертно-мануальному образцу.
 |
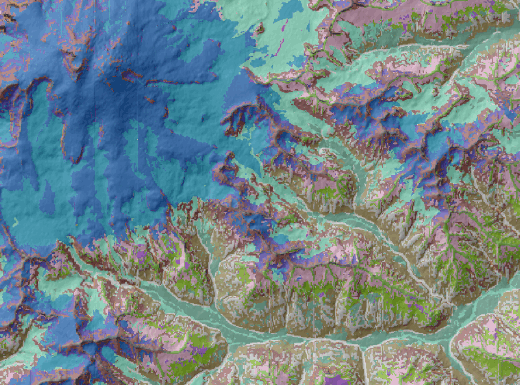 |
Рис. 15.29 Сравнение фрагментов классификации, полученных по алгоритму ISODATA анализа (a) и K-Means Clustering for Grids (b)


Рис. 15.30 Синтез девяти слоев (набор переменных - второй вариант) по алгоритму K-Means Clustering for Grids SAGA GIS
Очевидно, что решение о наборе переменных, которые мы бросаем в "топку" кластерного анализа принимается на основе экспертных знаний. Но есть еще одна полезная операция, которая поможет "убрать лишнее" из набора, т.е., вывести из анализа те показатели, которые слишком сильно коррелируют друг с другом и могут повлиять на результат классификации. Анализ главных компонент или расширение Кархунена-Лоева (Karhunen-Loeve) - классический метод уменьшения размерности или анализа исследовательских данных. Коэффициенты корреляции (и/или коэффициенты ковариации) между многими растровыми слоями можно рассчитать с помощью Principal Component Analysis|Анализа Главных Компонент. Инструмент реализован как в SAGA GIS: (Spatial and Geostatistic >> Principal Component Analysis (PCA)), так и в ArcMAP10.x (Spatial Analyst Tools >> Multivariate >> Principal Components).
В SAGA GIS разработанный О.Конрадом (O.Conrad, 2010) инструмент "запрашивает" на вход растры-переменные; критическая опция Method|Метод, позволяет получить три варианта аналитической матрицы на выходе correlation matrix (таблица коэффициентов корреляции), variance-covariance matrix (таблица коэффициентов ковариации), sums-of-square-and-cross-products-matrix (таблица сумм квадратов).
Выходной файл PCA Eigen Vectors в данном случае отражает variance-covariance matrix может быть сохранен в формате DBF и проанализирован по значениям коэффициентов ковариации. В общем случае полагают, что любые пары переменных со значениями коэффициента выше 0,60 должны быть внимательно рассмотрены, со значениями большими 0,80 однозначно отбракованы, т.е., из двух таких переменных для последующего включения в любые инструменты синтеза (кластерный анализ и др.) должен быть оставлен только один.
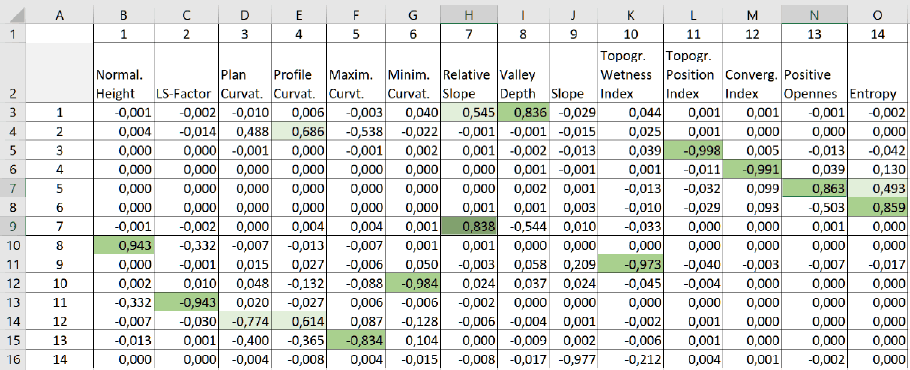
Рис. 15.31 Скриншот таблицы коэффициентов ковариации (variance-covariance matrix) Анализа Главных Компонент для 14 геоморфометрических переменных
Построение матрицы ковариации Анализа Главных Компонент для набора из 14 геоморфометрических переменных позволяет наглядно выявить близкие по смыслу параметры, которые не должны использоваться в одних и тех же процедурах классификации, кластерного анализа и т.д. Так очевидно связаны между собой параметры Normalized Height|Нормализованная высота и Valley Depth|Глубина долин (Kv=0,943), Topographic Position Index|Индекс топографической позиции и Plan Curvature|Плановая кривизна (Kv=0,998) LS-factor|Фактор длины-крутизны склона (Kv=0,942), Topographic Wetness Index|Топографический индекс влажности и Slope|Уклон (Kv=0,973), Profile Curvature|Профильная кривизна и Convergence Index|Индекс конвергенции, Positive Openness|Положительная открытость и Maximum Curvature|Максимальная кривизна, Entropy|Энтропия рельефа и Minimum Curvature|Минимальная кривизна.
Переменные, отражающие состояние растительного покрова и землепользования - в частности, вегетационные и ландшафтные индексы также могут оказаться связанными между собой. Анализ Главных Компонент для девяти таких индексов обнаруживает тесно связанные индексы: WDVI и NDVI, VARI и IPVI, SAVI и NDWI, NDSI и ThTVI.
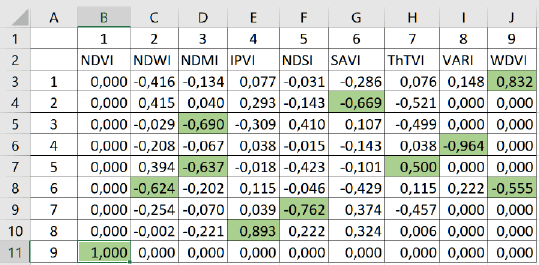
Рис. 15.32 Скриншот таблицы коэффициентов ковариации для 9 вегетационных и ландшафтных индексов
Таким образом, c одной стороны, взаимосвязанные переменные не могут быть использованы в одном и том же наборе, подаваемом на вход в инструментах классификации, с другой - дают возможность замены переменных в качестве инвариантов в различных сочетаниях показателей.
15.6.Сложные алгоритмы моделирования - классификация с возможностью обучения
Методы машинного (компьютерного) зрения представляют собой реализацию объектно-ориентированной классификации, т.е., в ходе работы алгоритма происходит не только определение спектральных показателей объекта, но и определение контуров и геометрических характеристик. Поэтому в качестве обучающей выборки для компьютерного зрения должны выступать не отдельные пиксели изображения, а их ансамбли, соответствующие ареалам прототипа ландшафтной карты или лесохозяйственным выделам, что автоматически увеличивает требования к объему обучающей выборки минимум на два порядка
Современные ГИС-пакеты предоставляют достаточно широкий набор популярных инструментов так называемого "машинного обучения". Так в SAGA GIS мы обнаружим следующие алгоритмы:
- Artificial Neural Network Classification|Искуственные нейронные сети,
- Boosting Classification|Бустинг,
- K-Nearest Neighbours Classification|KNN классификатор,
- Decision Tree Classification|Дерево решений,
- Logistic Regression|Логистическая регрессия,
- Normal Bayes Classification|Байесовский классификатор,
- Random Forest Classification|Случайный лес,
- Support Vector Machine Classification|Метод опорных векторов.
Несмотря на различия, все инструменты геоинформационного моделирования, построены на интеграции библиотек машинного обучения (Machine Learning library) для классификации основе совокупности переменных, и по этой причине имеют схожий интерфейс: пользователь определяет набор растровых переменных и обучающий векторный (полигональный) файл с полем значений, задающих номер класса. Число выходных классов также определяется числом таксонов обучающего вектора, хотя в некоторых алгоритмах его следует указать в качестве минимального. Остальные опции являются специфичными для каждого конкретного алгоритма и, как правило, требуют "тонкой" настройки.
Основная проблема, общая для всех методов с использованием машинного обучения заключается поиске подходящего источника исходных (т.е., собственно "обучающих") данных. Для этой цели могут быть выбраны:
- Обучение по экспертной ландшафтной карте,
- Обучение по наземным съемкам (ландшафтным описаниям, геоботаническим площадкам),
- Обучение по картам лесоустройства (для лесопокрытых ареалов).
Преимущества и недостатки первого варианта (использование экспертной карты "ручного" рисования) мы уже обсуждали. В принципе можно взять любую такую карту, оцифровать ее, и попытаться извлечь в векторные полигоны ареалов (каковые, по идее, и должны представлять собой "ядра типичности") значения переменных, полученных по данным дистанционного зондирования - геоморфологических метрик и вегетационных и/или ландшафтных индексов, однако результат, как правило, оказывается разочаровывающим: разброс значений внутри большей части классов оказывается весьма заметным...
Обучение по наземным съемкам возможно лишь на ограниченных по площади участках, в пределах которых плотность точек (например - точек геоботанических описаний) соизмерима с разнообразием и сложностью предполагаемого рисунка выделов будущей модели: очевидно, что для больших территорий это правило невозможно соблюсти. Поэтому в пределах обширных ареалов (измеряемых сотнями километров) наземные съемки могут рассматриваться лишь как вспомогательный источник верификации "регулярных" данных, - в качестве последних, обычно, рассматриваются материалы лесоустройства.
Именно лесоустроительные данные сегодня, как правило, являются основой обучения моделей. Несомненным достоинством таких материалов можно считать достаточно крупный масштаб выделов (каковые, при съемках в масштабе 1:10 000 могут считаться аналогами ландшафтных фаций и урочищ, а при съемках 1:25 000 аналогами группы урочищ или местностей) и наличие целого ряда характеристик, выраженных как в понятиях номинальной (бонитет, класс товарности, лесорастительные условия, породный состав), так и в интервалах количественной шкалы, так называемые лесотаксационные параметры - запас, полнота, рост, диаметр). И те и другие могут использоваться в соответствующих моделях как обучающие признаки.
Слабые стороны использования лесоустроительных данных также хорошо известны:
- устаревший характер материалов (вопреки существующим правилам обновления многие лесные регламенты имеют возраст, значительно превышающий 10 лет);
- неизбежный "отпечаток" регулярной квартальной и неправильной повыдельной сеток, по которым фиксируются и агрегируются лесотаксационные параметры;
- зачастую невысокое качества и недостоверность данных (особенно в труднодоступных и многолесных ареалах);
- необходимость закладки пробных площадок (не менее 1 на 1 км2) в лесных насаждениях для верификации и устранение возможных ошибок.
Содержательная проблема, которую приходится решать при построении и отладке любых моделей классификации с обучением - набор исходных данных, используемых для характеристики морфодинамической основы и состояний ландшафта; как правило, это геоморфометрические переменные, производные от ЦМР и различные вегетационные и/или ландшафтные индексы (получаемые в результате обработки и расчета по каналам сенсоров типа Landsat или Sentinel).
Таблица 15.2 Признаки, наиболее часто используемые для сегментации ландшафтов при классификации с обучением| Индексы/Метрики | Признаки | Входные данные |
|---|---|---|
| Растительный покров | ||
| NDVI | Normalized difference vegetation index | Red, NIR |
| TNDVI | Transformed normalized difference vegetation index | Red, NIR |
| RVI | Ratio vegetation index | Red, NIR |
| SAVI | Soil adjusted vegetation index | Red, NIR |
| TSAVI | Transformed soil adjusted vegetation index | Red, NIR |
| MSAVI | Modified soil adjusted vegetation index | Red, NIR |
| MSAVI2 | Modified soil adjusted vegetation index 2 | Red, NIR |
| GEMI | Global environment monitoring index | Red, NIR |
| IPVI | Infrared percentage vegetation index | Red, NIR |
| LAIFromNDVILog | Leaf Area Index from log NDVI | Red, NIR |
| LAIFromReflLinear | Leaf Area Index from reflectances with linear combination | Red, NIR |
| LAIFromNDVIFormo | Leaf Area Index from Formosat 2 TOC | Red, NIR |
| Водные объекты | ||
| NDWI (Gao 1996) | Normalized difference water index | NIR, MIR |
| NDWI2 | Normalized difference water index (Mc Feeters 1996) | Green, NIR |
| MNDWI | Modified normalized difference water index (Xu 2006) | Green, MIR |
| NDTI | Normalized difference turbidity index (Lacaux et al.) | Red, Green |
| Почвы и грунты | ||
| RI | Redness index | Red, Green |
| CI | Color index | Red, Green |
| BI | Brightness index | Red, Green |
| BI2 | Brightness index 2 | NIR, Red, Green |
| Антропогенные объекты | ||
| BSU | Built Surfaces Index | NIR,Red |
| Геоморфометрические переменные | ||
| STD H | Standard deviation of elevation | Elevation |
| Slope | Slope gradient | Elevation |
| Aspect | Slope aspect | Elevation |
| CrvPln | Plane curvature | Elevation |
| CrvPrf | Profile curvature | Elevation |
| CrvTng | Tangential curvature | Plane curvature |
| CrvMax | Maximum curvature | Elevation |
| CrvMix | Minimum curvature | Elevation |
| CrvTot | Total Curvature | Elevation |
| HAR | Height above river | Channel, Flow accumulation |
| HAND | Height above nearest depression and channel | Channel, Elevation |
| VlDpth | Valley Depth | Channel, Elevation |
| HlHght | Hill Height | Elevation |
| PosOpn | Positive Openness | Elevation |
| TPI | Topographic Position Index | Elevation |
Инструмент SAGA GIS Artificial Neural Network Classification(O.Conrad, 2016) (Imagery >> OpenCV) представляет собой интеграцию библиотеки машинного обучения OpenCV для классификации искусственных нейронных сетей на основе переменных гридов (растровых слоев).Специфические опции инструмента:
Load Model
Training areas: *указывается файл с образцами Training Method|способ распространения: resilient propagation, back propagation
Number of Layers|Число слоев нейросети: *по умолчанию - 3
Number of Neurons|Число нейронов: в каждом слое нейросети: *по умолчанию 3
Maximum Number of Iteration|Максимальное число итераций: *по умолчанию 300
Error change Epsilon|Критерий прекращения обучающего алгоритма: *определяет насколько велико различие между итерациями для продолжения процесса *по умолчанию 0,0000012
Activation Function|Функция активации: Sigmoid
Для классификации используем уже выбранные нами девять переменных:
- Normalized Height|Нормализованная высота,
- Slope|Уклон поверхности,
- Openness|Общая открытость,
- Valley Depth|Глубина долин,
- Maximum Curvature|Максимальная кривизна,
- Minimal Curvature|Минимальная кривизна,
- IPVI, Infrared Percentage Vegetation Index|Инфракрасный вегетационный индекс,
- NDWI, Normalised Water Index Differentiated|Нормализованный Дифференцированный водный Индекс,
- NDMI, Normalized Difference Moisture Index |Стандартизованный индекс различий увлажненности.
Критическими параметрами, требующими особого внимания, являются Число слоев нейросети и Число нейронов. Так в нашем случае при использовании дефолтных значений сеть как бы "недорабатывает" и итоговый рисунок выглядит далеким от обучающего образца



Рис. 15.33 Результат классификации по девяти переменным инструментом Artificial Neural Network Classification SAGA GIS с параметрами: a) Число слоев сети - 3, Число нейронов - 3, b) Число слоев сети -5, Число нейронов - 5
Показательно, что Artificial Neural Network Classification в SAGA GIS выдает легенду, внешне соответствующую обучающему файлу (13 классов), но при открытии классифицированного растра в ArcMAP10.x обнаружим 7 классов с индивидуальными значениям; при этом увеличение числа слоев и нейронов нейронной сети влияет на сложность итоговой мозаики, приближая ее к "образцу" экспертной карты, но не меняет количества классов: алгоритм ANNC (при использованных переменных и принятых значениях опций) "не видит" необходимости в 13 таксонах).
Decision Tree Classification использует алгоритм Decision Tree|Дерево решений имитирующий процедуру того, как решает задачи прогнозирования человек. В общем случае это k-ичное дерево с решающими правилами в нелистовых вершинах (узлах) и некотором заключении о целевой функции в листовых вершинах (прогнозом). Решающее правило — функция от объекта, позволяющее определить, в какую из дочерних вершин нужно поместить рассматриваемый объект. В листовых вершинах могут находиться разные объекты: класс, который нужно присвоить попавшему туда объекту (в задаче классификации), вероятности классов (в задаче вероятности), непосредственно значение целевой функции (задача регрессии).
Интерфейс инструмента Decision Tree Classification включает параметры Maximum Tree Depth, Minimum Sample Count и Maximum Categories; дефолтный результат Дерева решений в нашем случае (изменен только параметр Maximum Categories - в соответствии с числом классом) ближе к обучающему образцу.
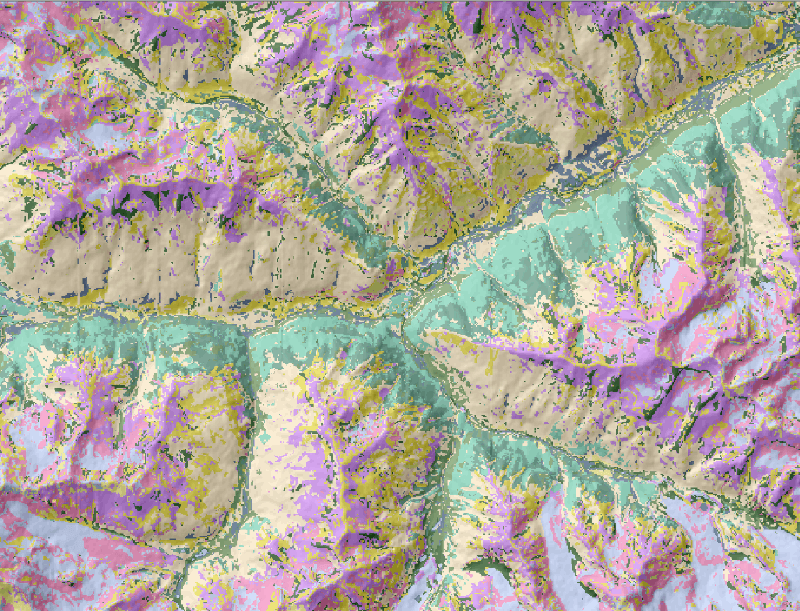

Рис. 15. 34 Результат классификации по девяти переменным инструментом Decision Tree Classification SAGA GIS
Полученная с использованием Decision Tree для ключевого участка Приэльбрусья классификация выдерживает заданное образцом число классов (13), хорошо выделяет долину Баксана, передает целостность массива Эльбруса (разделяя его склоны и контрфорсы) и корректно отражает катенарную и гребне-килевую классификацию местности; кроме того, алгоритм конфигурирует классы склонов разной экспозиции. В целом можно констатировать что при данном наборе параметров алгоритм позволяет получить результат, максимально близкий к экспертной ландшафтной карте.
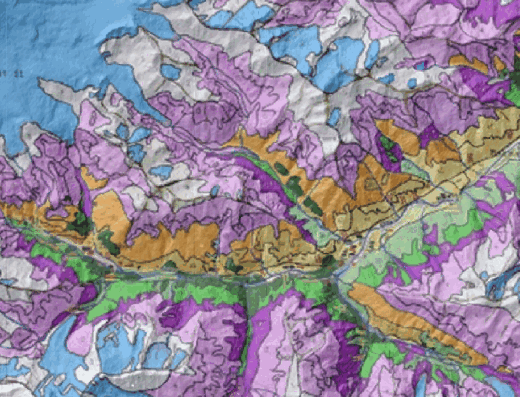 |
 |
Рис. 15. 35 a) фрагмент экспертной ландшафтной карты, использованной для обучения b) классификация на 13 классов инструментом Decision Tree SAGA GIS
Random Forest Classification алгоритм машинного обучения, заключающийся в использовании ансамбля деревьев решений, каждое из которых само по себе даёт очень невысокое качество классификации, но совокупный результат может получиться удовлетворительным "Случайный Лес". Интерфейс инструмента практически полностью аналогичен инструменту Decision Tree Classification и результат классификации также почти эквивалентен.

Рис. 15.36 Результат классификации по девяти переменным инструментом Random Forest Classification SAGA GIS
Еще один широко используемый способ машинного обучения - K-Nearest Neighbours Classification|Метод k-ближайших соседей метрический алгоритм для автоматической классификации объектов. Суть метода в том, что объект приписывается к тому классу, который является наиболее распространённым среди k-соседей, классы которых уже известны. Алгоритм может быть применим к выборкам с большим количеством атрибутов (многомерным). Среди критических опций:
Training Method (classification, regression model: в данном случае - классификация),
Algoritm Type|Тип Алгоритма: *brute force.

Рис. 15.37 Результат по 9 переменным K-Nearest Neighbours Classification SAGA с обучением
Полученная с помощью K-Nearest Neighbours классификация также неплохо справляется с передачей катенарной и гребне-килевой дифференциации, обеспечивает более подробную мозаику классов, но при этом хуже передает различия между склонами разной экспозиции.
Logistic Regression (OpenCV) - как явствует из названия этот инструмент использует логистическую регрессию для решения задач классификации с линейно-разделяемыми классами. Предполагается, что зависимая переменная (в данном случае класс ландшафтов) принимает два значения и имеет биномиальное распределение, т.е., дискретное распределение вероятностей случайной величины X, принимающей целочисленные значения. Данное распределение характеризуется двумя параметрами: целым числом n>0, называемым числом испытаний, и вещественным числом P1, находящимся в диапазоне между 0 и 1 называемом вероятностью успеха в одном испытании. Критические опции:
Namber of Iteration|Число итераций,
Regularization|Регуляция,
Training Method|Метод обучения: *определяет каким образом будет проходить обучение, варианты - Batch Gradient Descent|Пакетным градиентный спуск или Batch Mini Gradient Descent|Мини-пакетный градиентный спуск,
Количество итераций можно рассматривать как количество выполненных шагов, а скорость обучения определяет продолжительность процедуры классификации. Для компенсации переобучения может быть выполнена регуляризация. (L1 или L2 в позиции Regularization).


Рис. 15.38 Результат классификации по девяти переменным Logistic Regression с обучением
Дефолтный результат на ключевом участке выдает 9 конечных классов с неплохо переданной гребне-килевой и катенарной дифференциацией, а также с учтенной экспозицией, однако, как можно видеть, массив Эльбруса лишен различий между прямыми склонами и контрфорсами, а долина Баксана "слилась" со склонами южной и юго-восточной экспозиции
Normal Bayes Classification Байесовская классификация |- закрытый алгоритм SAGA GIS не содержащий каких-либо опций в диалоговом окне (кроме входящего файла обучающего векторного файла), но, тем не менее, обеспечивающий неплохие результаты.
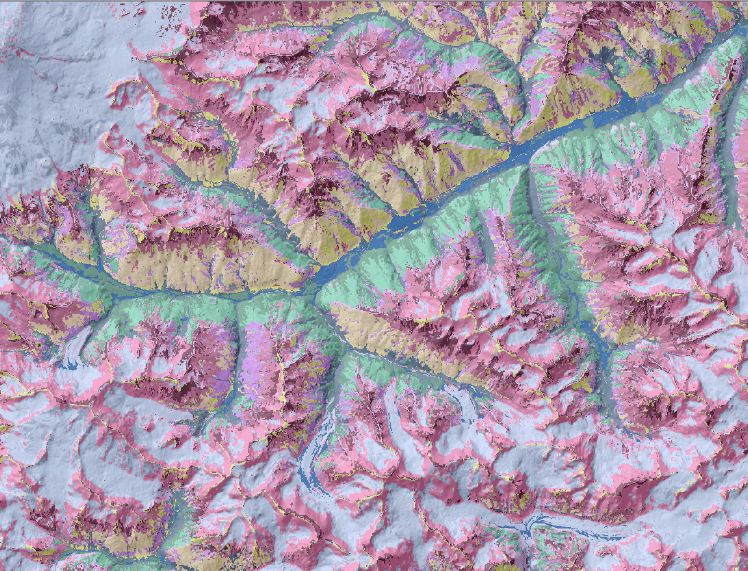

Рис. 15.39 Результат Normal Bayes Classification классификации по девяти переменным с обучением
Классификация сохраняет целевое число конечных таксонов, отражает склоновую и гребне-килевую дифференциацию, различие в экспозициях макросклонов и выделяет элементы долинно-речной сети.
Support Vector Machine Classification (OpenCV)|Метод опорных векторов — один из наиболее популярных методов обучения, который применяется для решения задач классификации и регрессии. Основная идея метода заключается в построении гиперплоскости, разделяющей объекты выборки оптимальным способом. Предполагается, что чем больше расстояние (зазор) между разделяющей гиперплоскостью и объектами разделяемых классов, тем меньше будет средняя ошибка классификатора. Метод достаточно сложен, требует больше вычислительных ресурсов и занимает больше времени чем все предыдущие методы машинного обучения.


Рис. 15.40 Результат Support Vector Machine Classification классификации по 9 переменным SAGA с обучением<
Результат алгоритма Опорных Векторов, вероятно, порадовал бы глаз "классического ландшафтоведа", поскольку полученная классификация отлично выражает две комплементарные подсистемы: долинно-речной сети и водоразделов горных хребтов и контрфорсов, однако при этом теряются детали катенарной дифференциации. Из девяти входных файлов четыре принадлежат к вегетационным индексам, однако их вклад оказался затушеванным геоморфологическими факторами.
Можно, разумеется, менять входные факторы - в частности заменить Топографический Индекс на показатели Кривизны: классификация приобретает иной вид, однако, влияние биоты в ней по-прежнему неочевидно...


Рис. 15. 41 Результат Support Vector Machine Classification классификации по девяти переменным с заменой Топографического Индекса на Максимальную и Минимальную Кривизны SAGA с обучением
Подводя итоги данного раздела, заметим, что ГИС-моделирование в любой области географии и экологии — сложный и трудоемкий процесс, требующий терпения, толерантности и объективности. Возможно, эти качества объясняют закономерный возврат (хотя уж на новом уровне) к экспертным подходам. Разрабатываемые сегодня, модели (в частности — алгоритмы геоморфологического, почвенного и ландшафтного моделирования) можно охарактеризовать как синтетические, и в таком качестве они вбирают в себя все лучшее из накопленного за четверть века арсенала, а именно: разделение процесса на этапы, соответствующие разным пространственным (иерархическим) уровням, возможность выбора и смены ведущего фактора дифференциации на каждом из таких уровней, предварительное конфигурирование и параметрическое описание прогнозируемых сущностей, формулировку экспертных правил нечеткой принадлежности, использование алгоритмов кластерного анализа и "машинного обучения".
Попытаемся сформулировать в самом общем виде базовые позиции, которые могут быть отнесены к арсеналу достижений ГИС-моделирования.
Традиционные экспертные геоэкологические классификации экосистем и соответствующие продукты тематического ручного картографирования представляют собой форму эвристического концептуального моделирования, недостаток которого заключается в том, что, хотя подобное моделирование и представлялось "системным", его правила и процедуры не всегда являются потенциально алгоритмизируемыми и воспроизводимыми. По этой причине традиционное экспертное картографирование не может быть надежной основой для формирования баз данных, необходимых для управления природопользованием и сопровождения практики ландшафтного планирования.
История развития и совершенствования методов ГИС-моделирования во-многом повторяет и воспроизводит историю развития традиционных подходов, с той, однако, разницей, что отработанные в ГИС-моделировании исследовательские сюжеты раз и навсегда получают доказательное обоснование. Так, например, с позиций ГИС- моделирования процедуры "индивидуального физико-географического районирования" и "типологического картографирования" могут быть осуществлены одним и тем же инструментом кластерного анализа и различаются определением условий соседства прогнозируемых полигонов и алгоритмом описания близости по выбранным параметрам дифференциации.
Мы вынуждены согласиться с тем утверждением, что не существует "идеальных" алгоритмов моделирования "на все случаи жизни": разработанные на сегодняшний день методы отличаются прежде всего по лежащей в их основе "математике" (множественная линейная регрессия, дискриминантный анализ, кластеризация k-средних, обобщенные линейные модели, обобщенные аддитивные модели, искусственные нейронные сети и деревья классификации). Помимо этого, алгоритмы различаются по набору и взаимным отношениям входных параметров, степени автоматизации, участию "экспертного знания", числу "шагов" (этапов) моделирования, возможности учета разных масштабов и свойств фрактальности, наконец (но не в последнюю очередь) - по предсказательной способности. Ни один из этих методов не "лучше" в том смысле, что каждому присущи свои свойства, такие как простота (или сложность) использования, доступность и прозрачность интерпретации, чувствительность к размеру выборки и т.д. Так, уже привычные нам построенные на линейных отношениях модели будут проще нейронных сетей, но последние в большей степени соответствуют реальной действительности.